





结束了中文分词工具的安装、使用及在线测试,开启中文词性标注在线测试之旅,一般来说,中文分词工具大多数都附带词性标注功能的,这里测试了之前在AINLP公众号上线的8款中文分词模块或者工具,发现它们都是支持中文词性标注的,这里面唯一的区别,就是各自用的词性标注集可能有不同:
以下逐一介绍这八个工具的中文词性标注功能的使用方法,至于安装,这里简要介绍,或者可以参考之前这篇文章:Python中文分词工具大合集:安装、使用和测试,以下是在Ubuntu16.04 & Python3.x的环境下安装及测试。
1) Jieba: https://github.com/fxsjy/jieba
安装:
代码对 Python 2/3 均兼容
全自动安装:easy_install jieba 或者 pip install jieba / pip3 install jieba
半自动安装:先下载 http://pypi.python.org/pypi/jieba/ ,解压后运行 python setup.py install
手动安装:将 jieba 目录放置于当前目录或者 site-packages 目录
中文词性标注示例:

2) SnowNLP: https://github.com/isnowfy/snownlp
特点:
中文分词(Character-Based Generative Model)
词性标注(TnT 3-gram 隐马)
情感分析(现在训练数据主要是买卖东西时的评价,所以对其他的一些可能效果不是很好,待解决)
文本分类(Naive Bayes)
转换成拼音(Trie树实现的最大匹配)
繁体转简体(Trie树实现的最大匹配)
提取文本关键词(TextRank算法)
提取文本摘要(TextRank算法)
tf,idf
Tokenization(分割成句子)
文本相似(BM25)
支持python3(感谢erning)
安装:
$ pip install snownlp
中文词性标注示例:

3) PkuSeg: https://github.com/lancopku/pkuseg-python
pkuseg具有如下几个特点:
多领域分词。不同于以往的通用中文分词工具,此工具包同时致力于为不同领域的数据提供个性化的预训练模型。根据待分词文本的领域特点,用户可以自由地选择不同的模型。我们目前支持了新闻领域,网络领域,医药领域,旅游领域,以及混合领域的分词预训练模型。在使用中,如果用户明确待分词的领域,可加载对应的模型进行分词。如果用户无法确定具体领域,推荐使用在混合领域上训练的通用模型。各领域分词样例可参考 example.txt。
更高的分词准确率。相比于其他的分词工具包,当使用相同的训练数据和测试数据,pkuseg可以取得更高的分词准确率。
支持用户自训练模型。支持用户使用全新的标注数据进行训练。
支持词性标注。
仅支持Python3, 测试词性标注的时候会自动额外下载一个包:
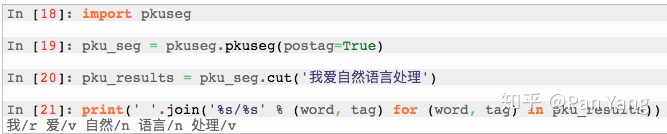
中文词性标注示例:
4) THULAC: https://github.com/thunlp/THULAC-Python
THULAC(THU Lexical Analyzer for Chinese)由清华大学自然语言处理与社会人文计算实验室研制推出的一套中文词法分析工具包,具有中文分词和词性标注功能。THULAC具有如下几个特点:
能力强。利用我们集成的目前世界上规模最大的人工分词和词性标注中文语料库(约含5800万字)训练而成,模型标注能力强大。
准确率高。该工具包在标准数据集Chinese Treebank(CTB5)上分词的F1值可达97.3%,词性标注的F1值可达到92.9%,与该数据集上最好方法效果相当。
速度较快。同时进行分词和词性标注速度为300KB/s,每秒可处理约15万字。只进行分词速度可达到1.3MB/s。
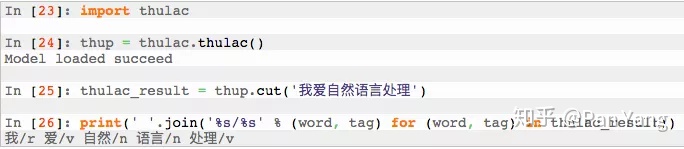
中文词性标注示例:
5) pyhanlp: https://github.com/hankcs/pyhanlp
pyhanlp: Python interfaces for HanLP
自然语言处理工具包HanLP的Python接口, 支持自动下载与升级HanLP,兼容py2、py3。
安装
pip install pyhanlp
注意pyhanlp安装之后使用的时候还会自动下载相关的数据文件,zip压缩文件600多M,速度有点慢,时间有点长
中文词性标注示例:

6)FoolNLTK:https://github.com/rockyzhengwu/FoolNLTK
特点
可能不是最快的开源中文分词,但很可能是最准的开源中文分词
基于BiLSTM模型训练而成
包含分词,词性标注,实体识别, 都有比较高的准确率
用户自定义词典
可训练自己的模型
批量处理
仅在linux Python3 环境测试通过
安装,依赖TensorFlow, 会自动安装:
pip install foolnltk
中文词性标注示例:

7) LTP: https://github.com/HIT-SCIR/ltp
pyltp: https://github.com/HIT-SCIR/pyltp
pyltp 是 语言技术平台(Language Technology Platform, LTP) 的 Python 封装。
安装 pyltp
注:由于新版本增加了新的第三方依赖如dynet等,不再支持 windows 下 python2 环境。
使用 pip 安装
使用 pip 安装前,请确保您已安装了 pip
$ pip install pyltp
接下来,需要下载 LTP 模型文件。
下载地址 - `模型下载 http://ltp.ai/download.html`_
当前模型版本 - 3.4.0
注意在windows下 3.4.0 版本的 语义角色标注模块 模型需要单独下载,具体查看下载地址链接中的说明。
请确保下载的模型版本与当前版本的 pyltp 对应,否则会导致程序无法正确加载模型。
从源码安装
您也可以选择从源代码编译安装
$ git clone https://github.com/HIT-SCIR/pyltp
$ git submodule init
$ git submodule update
$ python setup.py install
安装完毕后,也需要下载相应版本的 LTP 模型文件。
这里使用"pip install pyltp"安装,安装完毕后在LTP模型页面下载模型数据:http://ltp.ai/download.html,我下载的是 ltp_data_v3.4.0.zip ,压缩文件有600多M,解压后1.2G,里面有不同NLP任务的模型。
中文词性标注示例:

8) Stanford CoreNLP: https://stanfordnlp.github.io/CoreNLP/
stanfordcorenlp: https://github.com/Lynten/stanford-corenlp
这里用的是斯坦福大学CoreNLP的python封装:stanfordcorenlp
stanfordcorenlp is a Python wrapper for Stanford CoreNLP. It provides a simple API for text processing tasks such as Tokenization, Part of Speech Tagging, Named Entity Reconigtion, Constituency Parsing, Dependency Parsing, and more.
安装很简单,pip即可:
pip install stanfordcorenlp
但是要使用中文NLP模块需要下载两个包,在CoreNLP的下载页面下载模型数据及jar文件,目前官方是3.9.1版本:
https://nlp.stanford.edu/software/corenlp-backup-download.html
第一个是:stanford-corenlp-full-2018-02-27.zip
第二个是:stanford-chinese-corenlp-2018-02-27-models.jar
前者解压后把后者也要放进去,否则指定中文的时候会报错。
中文词性标注使用示例:

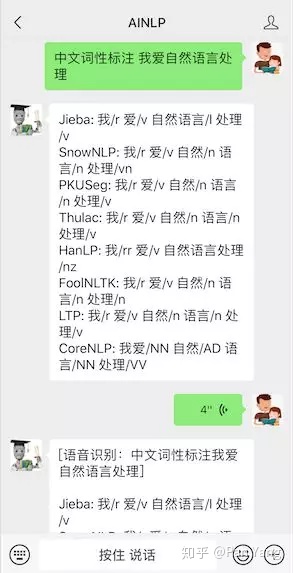
最后,感兴趣的同学可以关注我们的公众号 AINLP,输入"中文词性标注 测试内容"进行词性标注测试:

参考:
五款中文分词工具在线PK: Jieba, SnowNLP, PkuSeg, THULAC, HanLP
中文分词工具在线PK新增:FoolNLTK、HITLTP、StanfordCoreNLP
Python中文分词工具大合集:安装、使用和测试














 1412
1412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









