






在这篇文章中,我们将探讨一种比较两个概率分布的方法,称为Kullback-Leibler散度(通常简称为KL散度)。通常在概率和统计中,我们会用更简单的近似分布来代替观察到的数据或复杂的分布。KL散度帮助我们衡量在选择近似值时损失了多少信息。
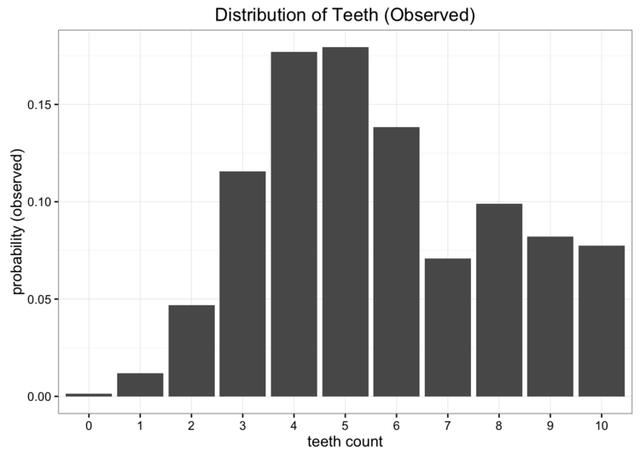
让我们从一个问题开始我们的探索。假设我们是太空科学家,正在访问一个遥远的新行星,我们发现了一种咬人的蠕虫,我们想研究它。我们发现这些蠕虫有10颗牙齿,但由于它们不停地咀嚼,很多最后都掉了牙。在收集了许多样本后,我们得出了每条蠕虫牙齿数量的经验概率分布:
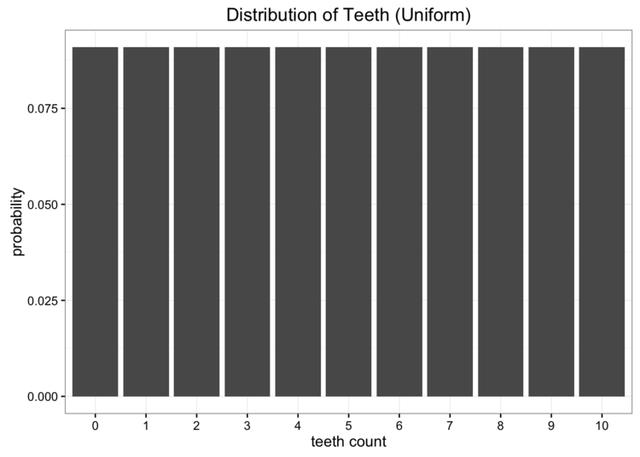
虽然这些数据很好,但我们有一个小问题。我们离地球很远,把数据寄回家很贵。我们要做的是将这些数据简化为一个只有一两个参数的简单模型。一种选择是将蠕虫牙齿的分布表示为均匀分布。我们知道有11个可能的值,我们可以指定1/11的均匀概率
显然,我们的数据不是均匀分布的,但是看起来也不像我们所知道的任何常见分布。我们可以尝试的另一种选择是使用二项分布对数据进行建模。在这种情况下,我们要做的就是估计二项分布的概率参数。我们知道如果我们有n次试验,概率是p,那么期望就是E[x]= np。在本例中n = 10,期望值是我们数据的平均值,计算得到5.7,因此我们对p的最佳估计为0.57。这将使我们得到一个二项分布,如下所示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 635
635











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









