





通过上一章我们对进程的概念稍微有点了解了
在这一章我们来了解下,怎么创建进程。
创建一个进程的唯一方法是由某个已存在的进程调用fork或vfork函数。被创建的新进程称为子进程,已存在的进程称为父进程。
我们先来看下fork函数:
函数原型:__pid_t fork (void);

fork函数没有参数,它是一个单调用双返回的函数,在某个进程调用此函数后,若创建子进程成功,则这个函数在父进程中的返回值是创建的子进程的进程号,而在子进程中的返回值是0,如果创建不成功则返回-1;每个进程可以有许多子进程,而每个进程至多有一个父进程,在上一章中我们通过getppid()函数来获得父进程的ID,我们可以通过这个函数的注释发现,子进程是父进程的一个复制,是分配有新的内存空间的,而不是和父进程共享内存。
现行的许多实现机制实际上并不将父进程的所有数据、堆、栈全部复制下来,而是使用一种"写时复制(cow)"的技术,父进程和子进程共享数据和堆栈区域,但是内核将它们都设置为只读权限,当任一进程要修改这些区域时,在生成该块内存的复制,通常是虚存的一页。
我们来看一个列子:
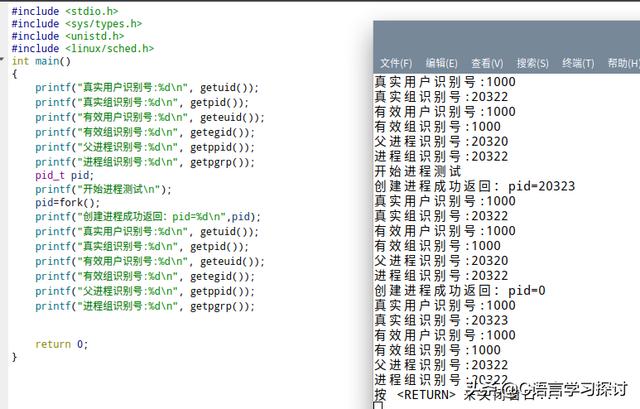
在这里程序在执行fork创建了一个子进程,子进程为就绪状态,当父、子进程都从fork函数返回时,处理机可能先调用到父进程,所以先返回了pid=20323,然后在父进程把接下来的程序执行完后,处理机又调度到子进程,由于子进程继承了父进程的执行环境,因此它也继承了父进程的执行地址,所以也从输出pid的语句开始,所以返回pid=0,可以看到它的父进程是20322。
然后我们来看下面的这段代码:
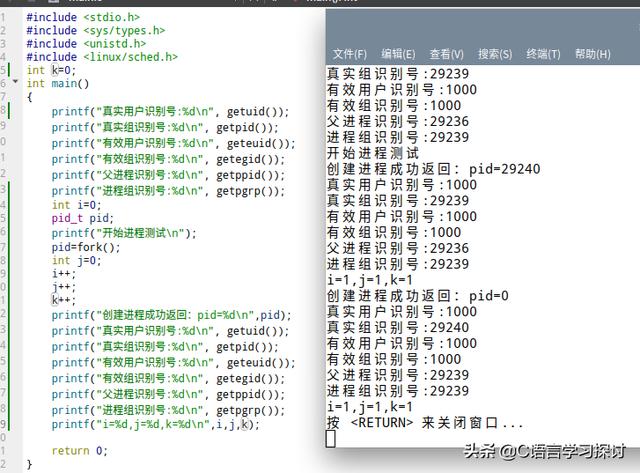
不管是全局变量还是局部变量他们的值都没有受到进程的影响,这是因为他们只在自己的进程空间里操作,互不干涉。
在看这个程序:
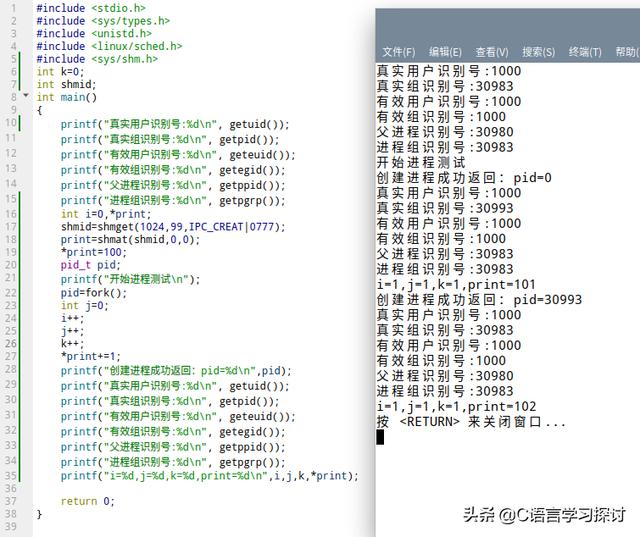
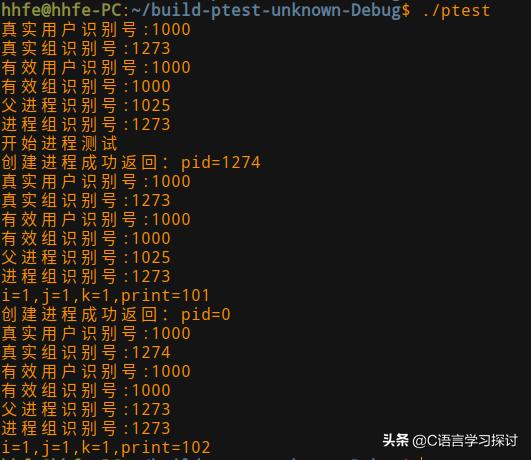
在第17行和第18行申请了一共享内存段,然后将该共享内存段用shmat附在进程的虚拟地址空间上,该共享内存段的虚拟首地址存放在print变量中,将该地址的内容赋值为100,然后开始测试操作,因为print指向存储单元中的值是两个进程共享的,从程序的运行结果看,该值与进程被调度到执行的时机有关。由于处理机调度的随机性。共享内存段的内容随父子进程的随机调度可能变得不一样,所以,在共享内存段中,使用fork一定要小心,进程要控制对共享内存段的同步操作。
现在人工智能比较火,大家可以学习下















 1375
1375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









