





 本文详细介绍了正则表达式中的贪婪与非贪婪模式,并通过Python示例展示了如何使用这些模式进行字符串匹配与替换。此外还介绍了特殊分组、非捕获组及正则表达式的特殊序列。
本文详细介绍了正则表达式中的贪婪与非贪婪模式,并通过Python示例展示了如何使用这些模式进行字符串匹配与替换。此外还介绍了特殊分组、非捕获组及正则表达式的特殊序列。

编程键盘
贪婪模式与非贪婪模式
正则表达式通常用于查找匹配的字符串.在Python中,数量词默认是贪婪的(在少数语言里,也可能是非贪婪的),总是尝试匹配尽可能多的字符;非贪婪模式正好相反,总是尝试匹配尽可能少的字符.

添加?可实现非贪婪模式
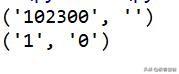
结果
re.sub方法实现替换字符
re.sub(pattern,repl,string,count=0)
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
repl(replace)参数也可以是一个函数:
import re # 将匹配的数字乘于 2def double(matched): value = int(matched.group('value')) return str(value * 2) s = 'A23G4HFD567'print(re.sub('(?Pd+)', double, s))
repl函数
上边的函数调用,函数名后边都没有括号.
下边是几个匹配的比较
import re#匹配目标def target_match(content): result=re.match('^Hellos(d+)sWorld',content) return result,result.group(),result.group(1),result.span()#通用匹配def gena_match(content): result=re.match('^Hello.*Demo$',content) return result,result.group(),result.span()#贪婪匹配def greed_match(content): result=re.match('^He.*(d+).*Demo$',content) return result,result.group(1)#非贪婪匹配def un_greed_match(content): result=re.match('^He.*?(d+).*Demo$',content) return result,result.group(1)if __name__=='__main__': con_match='Hello 1234567 World_This is a Regex Demo' print(target_match(con_match)) print(gena_match(con_match)) print(greed_match(con_match)) print(un_greed_match(con_match))结果为:
结果
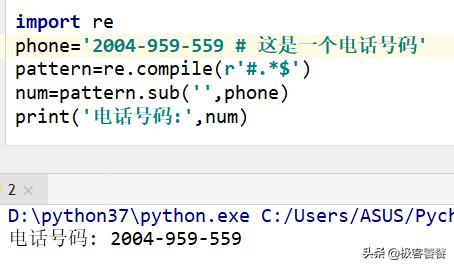
使用了compile将正则表达式转为了模式对象
对于上面我们也可以这样实现:
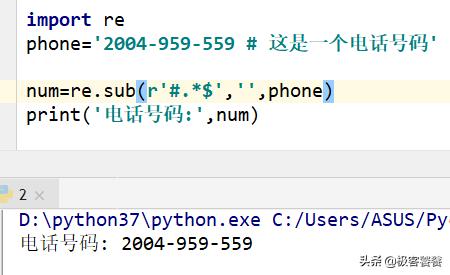
re.sub
使用re.compile()创建了模式对象,就必须在sub()方法中省略掉pattern这一参数项.
简单介绍下compile()函数:
re.compile(pattern[, flags])参数:
- pattern : 一个字符串形式的正则表达式
- flags 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
- re.I 忽略大小写
- re.L 表示特殊字符集 w, W, b, B, s, S 依赖于当前环境
- re.M 多行模式
- re.S 即为' . '并且包括换行符在内的任意字符(' . '不包括换行符)
- re.U 表示特殊字符集 w, W, b, B, d, D, s, S 依赖于 Unicode 字符属性数据库
- re.X 为了增加可读性,忽略空格和' # '后面的注释
该函数根据包含的正则表达式的字符串创建模式对象。可以实现更有效率的匹配。在直接使用字符串表示的正则表达式进行search,match和findall操作时,python会将字符串转换为正则表达式对象。而使用compile完成一次转换之后,在每次使用模式的时候就不用重复转换。当然,使用re.compile()函数进行转换后,re.search(pattern, string)的调用方式就转换为 pattern.search(string)的调用方式。
特殊分组
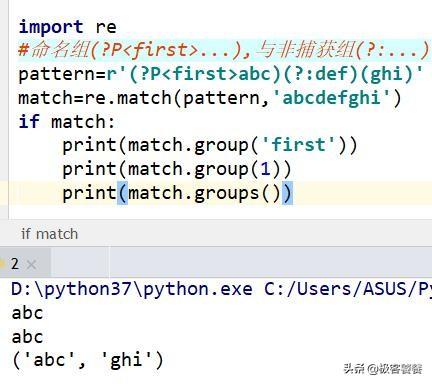
正常我们是使用()来进行分组,这里有两个特殊的分组:命名组和非捕获组
命名组格式为(?P...),其中那么是组的名字,...是内容.它可以通过group(name)来代替编号访问,也可以通过编号来访问.
非捕获组(?:...),它不能通过组方法访问,所以将他们添加到现有的正则表达式中不会破坏编号.
特殊序列
一个有用特殊的序列 是反斜杠和1到99之间的数字,例如1 表示匹配group(1)的表达式.
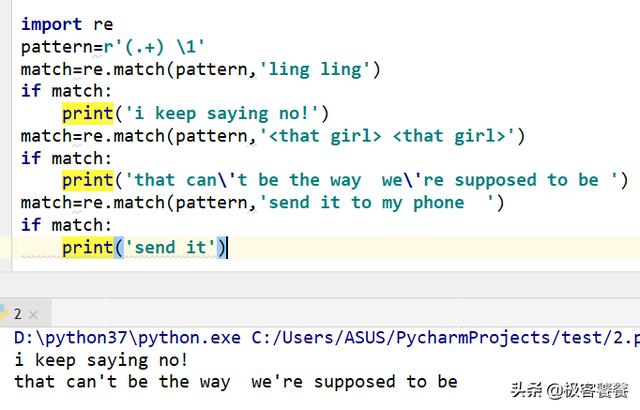
这里的(.+)分别匹配了ling和.1表示(.+)匹配的第一组表达式就是ling和.所以(.+) 1表示ling ling ;
关于正则表达式的详情可以点击这里:Python3 正则表达式 | 菜鸟教程


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









