






终于开学啦,希望自己能够把笔记记下去。属性数据分析我们是冯铮晖老师上的,老师的英语听着很舒服。
第一章主要内容简介
20200917更~
1 Categorical Response Data
我们这门课研究的主要是作为响应变量的属性数据,那么什么是属性数据?
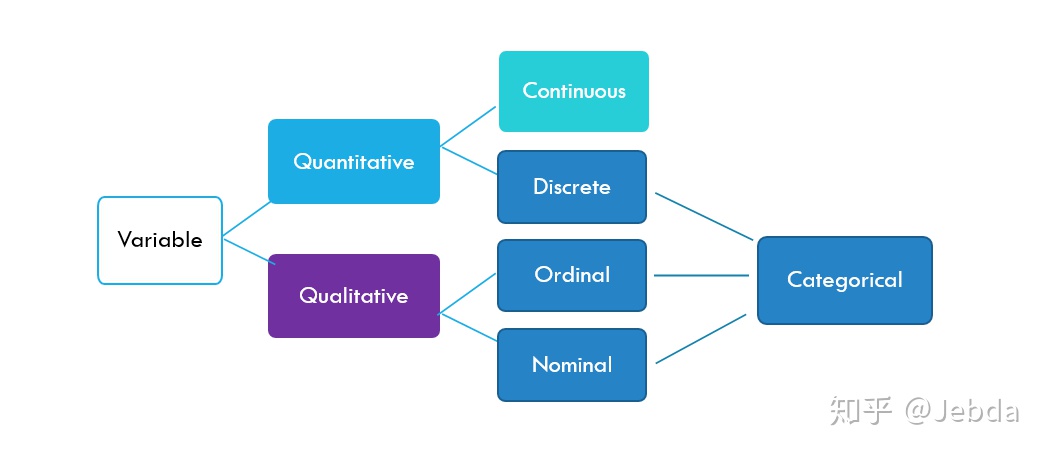
- 一般来说,我们的变量可以分为两种类型:定性变量(qualitative)与定量变量(quantitative)。其中,定性变量又可以分为nominal (平凡的,可以理解为无先后顺序的)以及ordinal (有先后顺序的) ,定量变量又可以分为连续的 (continuous) 与离散的 (discrete)。
- 其中,定性变量与定量变量中的离散型变量统称为属性数据。
2 Probability Distributions for Categorical Data
我们研究的响应变量其实就是随机变量,那么什么是随机变量?另外,常见的离散型分布有哪些呢?
- 随机变量的定义: a real-valued function from sample space to real space。
- 常见的离散型分布有:二项分布[Binomial Distribution],多项分布[Multinomial Distribution],后边我们还会用到泊松分布[Poisson Distribution]、负二项分布[Negativebinomial Distribution]、超几何分布[Hypergeometric Distribution]等)
3 Statistical Inference
什么是统计推断?为什么要做统计推断?怎样做统计推断?
Statistical Inference is an estimation, prediction, or some other generalization about a population based on information contained in a representative sample.
- 简而言之,统计推断就是通过代表性样本的结构或者所包含的信息来对样本所在的总体进行估计、预测或者根据样本性质来推知总体性质。

- 一般来说,我们的样本是形如
的样本对(这里假设含有响应变量),我们想知道
与
之间的关系,或者想通过新来的
去预测未知的
,就需要统计推断。如果我们已经预设了
与
之间的关系形式,例如线性,那么问题就转化为去估计对应的参数。
- 统计推断其实主要包含了两个方面:Estimation (估计) 与 Testing (检验)。估计我们有点估计 (point estimate) ,区间估计 (interval estimate) ,检验我们有常见的假设检验 (hypothesis testing)
4 More on Statistical Inference for Discrete Data
- 主要介绍三种估计量以及在小样本情况下如何进行推断
原-引言
本系列依据的参考书是 An Introduction to Categorical DataAnalysis, 3rd Edition
在正式介绍属性数据分析之前,我们将介绍一些关于属性数据的概念,复习一下关于属性数据最重要的两个分布:二项分布和多项分布,复习一下极大似然估计以及利用极大似然估计进行参数估计,复习一下如何利用贝叶斯方法进行统计推断。
属性数据的类型
属性变量事实上可以看作是有固定标签的数据,是定性数据,比如:某一个疾病的发病情况可分为有、无;对某一个事物的态度可以分为喜欢、厌恶、无感;疾病的阶段可以分为早期、中期、晚期;电脑的品牌有戴尔、惠普、联想、苹果、其他。
关于记号我们的约定是:当我们想表示一个响应变量是一个随机变量的时候,我们用大写字母表示,例如
我们接下来研究的对象,是以属性数据作为响应变量,而解释变量可以为属性数据,也可以为定量的数据。典型的例子便是银行对一个人是否会有信用卡违约进行判断,依据是这个人的婚姻情况(是否结婚,为属性数据)、住房情况(是否有房,为属性数据)、年龄(连续变量,定量)、薪资(连续变量,定量)、受教育水平(属性数据)、宗教信仰(属性数据),性别(属性数据)等等。
我们遇到的很多属性数据拥有简单的两个属性:是否拥有住房?是、否。这样的属性数据我们称之为二元变量。但倘若一个变量拥有多余两个属性,我们将这样的数据分成两类。一类是属性的排列没有顺序之分,另一类是属性的排列有顺序之分。
没有顺序之分的数据例如:通勤方式(步行、自行车、公交车、私家车、飞机、地铁),音乐类型(世界音乐 [《My Irish Friend》] 、摇滚 [《Stairway to Heaven》]、古典 [《六月船歌》]、流行 [《好想爱这个世界啊》]、说唱 [《差不多先生》]、其他)
有顺序之分的数据例如:发怒的频率 (从不、偶尔、经常),开心的程度(一点不开心,一般般开心,相当开心)。
针对数据的属性是否有排列顺序,我们将使用不同的方法。
整个课程的脉络
首先我们假设数据之间是独立的,在这个前提下,我们有
- 第1&2章: 非模型基础的属性数据分析方法
- 第3章:广义线性模型
- 第4&5章:二元Logistic回归模型
- 第6章:多元Logistic回归模型(有序、无序)
- 第7章:对数线性模型,用于分析多个属性响应变量之间的关系
接下来我们放宽假设,认为数据之间有相关性,于是有了第8&9&10章
第11章介绍的是分类与聚类方法以及高维数据的处理
第12章是对属性数据方法历史的回顾
按冯老师的意思,我们只会学习前6章,因此最重要的两个部分,便是列联表与logistic回归。
属性数据的分布
二项分布
显然,二元变量完全可以转化成我们
随机变量
多项分布
这其实是二项分布的推广,假设变量一共有
多项分布的边缘分布是二项分布。
似然函数与极大似然估计
20200922更~
首先我们来看什么是似然函数:
The likelihood function is the probability of the observed data, expressed as a function of the parameter value.
我们最大化似然函数的目的其实很简单:让已经发生的事情是最有可能发生的。毕竟我们已经知道了分布的具体形式,需要做的就是去估计参数。
那么什么是极大似然估计呢?
The maximum likelihood estimate(MLE) is the parameter value at which the likelihood function takes its maximum.
通常来说,我们会推荐用MLE来作为二项分布中参数的估计,这是因为:
- 对于二项分布来说,MLE拥有良好的解释性:当我们对参数
进行极大似然估计的时候,
的极大似然估计是
,我们记为
,这个值代表了
次试验中事件发生的真实频率。
- MLE有着渐进正态性
当我们有了估计量
一般来说,假设检验的步骤有:
- 写出原假设
与备择假设
- 定义显著性水平
(当然可以定义置信水平
,
)
- 找到一个统计量,并写出这个统计量在原假设下的分布
- 将统计量的观察值与critical value进行比较,或者计算P-value
- 得出结论
事实上,假设检验是一种反正法。因为我们想要去直接证明一件事情正确是很难的,但是如果我们要证明一件事情错误,却相对来说容易一些——只需要找到一个反例就可以了。这也是为什么假设检验总是采用reject region,说fail to reject the null hypothesis 而不是说 we accept the null hypothesis。
让我们先用数统中学过的方法来看一个例题——对于二项分布
假设我们认为硬币应当是均匀的,于是需要将这个结论与我们现实中观察到的情形进行对比。也就是说,我们观察到的频率是
- 于是我们的原假设与备择假设可以写为:
- 我们定义显著性水平为
- 我们所构造的统计量依据中心极限定理得到——因为倘若
,那么一定有
,对于大样本来说有
,于是在原假设为真,即
的情况下,就有
,于是我们的统计量为
,这里
根据不同的样本会有不同的值。在原假设成立的情况下,便有统计量服从标准正态分布。
- 我们将通过试验得到的
值代入我们的统计量,便可以得到统计量的观察值,然后根据置信度或者显著性程度查表得到我们的critical value
以及
,根据需要选择一个与我们统计量的观察量进行比较,从而得出结论。当然,我们直接计算P-value来和显著性水平进行比较。P-value=P(
is true) 或者 P(
is true)。需要注意的是,由于我们计算出的P值只是真实P值的一个近似,P值的目的仅是给出拒绝原假设的强烈程度,一般P值取两位或者三位精度的
- 当然,我们也可以利用置信区间来判断。置信区间的构造的第一种方法是这样的:我们想让以下的式子成立:
,这相当于在求出所有的不会让原假设被拒绝的
的值,我们需要求解一个关于
的二元一次方程(因为
与
都是已知的),来获得置信区间。
以上例子中的统计量,我们称为Score Test。
显然,上边这个例子中,关于置信区间的求解是很不友好的,主要的原因是因为要去求解一个二元一次方程,但有一个事实可以让我们在样本量很大的时候简化计算。
由于
这个时候,我们就可以利用
但是这样一来,好处是置信区间变得容易计算了——
事实上,我们可以把统计量
我们相当于利用二项分布的例子介绍了两种统计量:Score Test 以及 Wald Test,两者的主要区别就在标准误的选择不同——Score Test 使用的是
关于置信区间的构造我们还可以利用AC Test。 AC Test 的基本思想是:将原本的

关于离散数据的更多统计推断
这里会介绍三种利用似然函数进行参数推断(置信区间和显著性检验)的方法。这里将以二项分布为例进行讲述。
Wald Test
令
当
这种基于ML估计值及其标准误估计的统计量称作Wald统计量。使用此统计量的
似然比检验
另一种利用似然函数进行检验的方法源自于两个极大似然函数的比率:
- 原假设参数空间中似然函数的极大值
- 更大的参数空间(包括原假设和备择假设的参数空间)中似然函数的极大值
似然比检验的统计量为
这个检验统计量始终是非负的,而且,较小的
Score Test
得分检验在二项分布中,主要是将标准误换成了在原假设成立前提下的标准误。


小样本二项推断
对于比例的判断,当
对于小样本的问题,直接使用二项分布计算P值会更加安全。
比如:一共做了
而双边备择假设情况下的P值为
对于小样本的离散数据,统计学家倾向使用不同类型的P值。中间P值等于试验观测结果概率的二分之一加上更极端结果的概率。对于小样本,我们可以使用反解二项分布显著性检验的方法构造置信区间,而不采用正态近似。
第一章到此结束,撒花~















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









