







一、概述
我们在编写网络应用程序的时候需要注意codec(编解码器),因为数据在网络中传输的都是二进制字节码数据,而我们拿到的目标数据往往不是字节码数据。因此在发送数据时就需要编码,接收数据时就需要解码。

codecd的组成部分有两个:decoder(解码器)和encoder(编码器)。encoder负责把业务数据转换成字节码数据,decoder负责把字节码数据转换成业务数据。
其实Java的序列化技术就可以作为codec去使用,但是他硬伤太多了:
- 无法跨语言
- 序列化后体积太大了,是二进制编码的5倍。
- 性能低
由于Java序列化技术硬伤太多,所以netty自身提供了一些codec:
netty提供的解码器:
- StringDecoder,对字符串数据进行解码。
- ObjectDecoder,对Java对象进行解码。
- …
netty提供的编码器:
- StringEncoder,对字符串数据进行编码。
- ObjectEncoder,对Java对象进行编码。
- …
netty本身自带的ObjectDecoder和ObjectEncoder可以实现pojo对象或各种业务对象的编码和解码。但是其内部任然是使用Java序列化技术
所有我们不建议使用。那么我们就需要更高级的编解码器。
二、Protobuf
protobuf 是Google发布的开源项目,全称Google protocol buffers ,特点如下:
- 支持跨平台、多语言(支持绝对多数语言,Java 、c++、c#、python等)
- 高性能、高可靠性
- 使用protobuf 编译器能自动生成代码,protobuf 是将类的定义换成 .proto 文件进行描述,然后通过protoc.exe 编译器 编译成 .java文件
目前使用netty开发的时候,经常使用protobuf作为codec (编解码器)
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>3.6.1</version>
</dependency>
2.1 如何使用protobuf
第一步先编写.proto文件
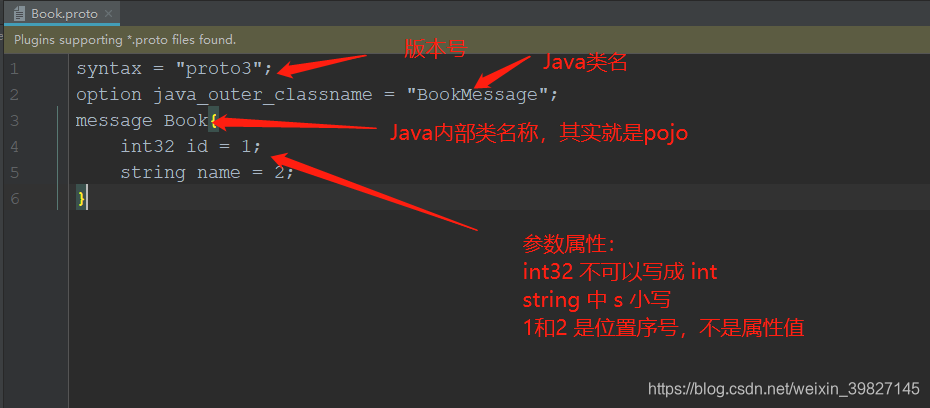
第二步
下载protoc编译器
下载地址
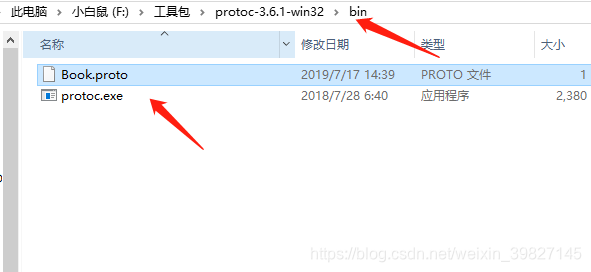
第三步:
解压后,打开bin目录,可以把我们写好的Book.proto文件复制到这个路径下,方便操作
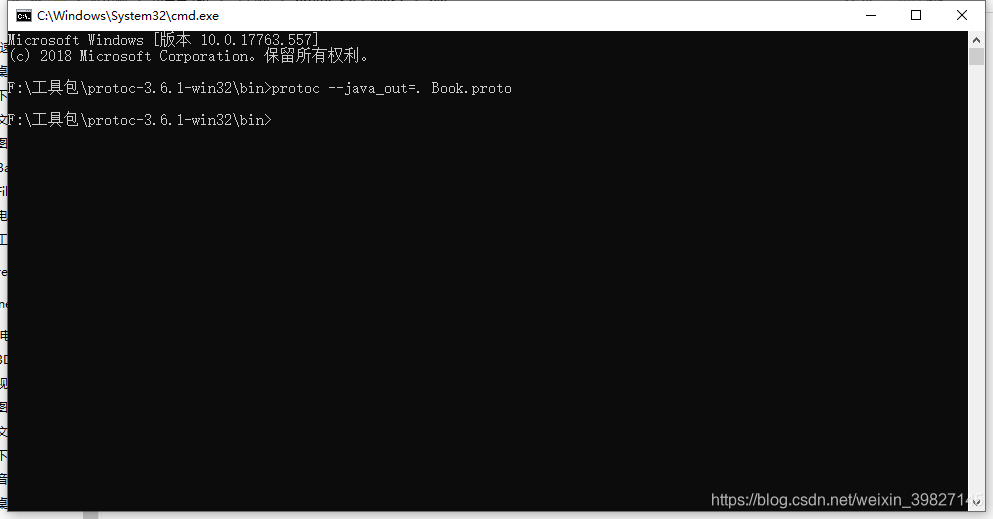
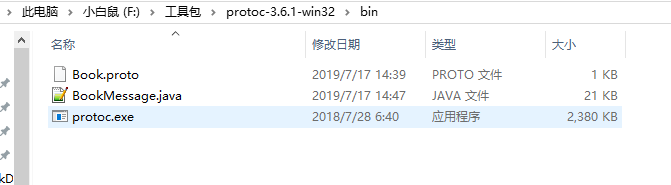
执行命令:protoc --java_out=. Book.proto
说下这里的 .(点) 就表示当前路径,如果你的文件在其他位置就写文件的绝对路径。.(点)和文件名之间要加空格















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









