





点击上方“Python数据科学”,选择“星标”公众号
重磅干货,第一时间送达
作者:石晓文
来源:小小挖掘机
计划写一个新系列,分别使用Excel、Python、Hive、SparkSQL四种方式来实现简单的数据分析功能,例如GroupBy、透视表等功能。
俗话说的好,工欲善其事,必先利其器,所以咱们先介绍一下环境的搭建!虽说Hive和Spark都是分布式的宠儿,但是咱们仅仅实现单机版!
所有需要安装的工具列表如下:
1、Excel
2、Python
3、JDK
4、IDEA
5、Mysql
6、Scala
7、Spark
8、Hadoop
9、Hive
前五个咱们就不说了,网上的工具一大堆,我默认你已经全部安装过了,咱们重点讲下后面四个的安装和配置。废话不多说,一个个来,踩坑一天的经验全部分享给你!
1、Scala安装
下载压缩包并解压
首先我们要到官网下载安装包。官网传送门: http://www.scala-lang.org/download/
我下载的是scala-2.12.3.tar.
下载后进入安装包所在目录进行解压操作:
tar -zxvf scala-2.12.3.tar
添加环境变量
执行如下命令打开配置文件:
vim ~/.bash_profile
添加如下两行:
export SCALA_HOME=你Scala的路径/scala
export PATH=$PATH:$SCALA_HOME/bin
添加结束后推出编辑配置文件,使用如下的命令使配置生效:
source ~/.bash_profile
检验是否配置生效
在命令行输入scala,并测试一段简单的语句,证明scala安装成功:

输入:q可以退出scala的交互环境。
2、Spark安装
下载压缩包并解压
到官网下载spark的安装包,我用的是spark-2.1.1-bin-hadoop2.7.tgz
使用如下的命令进行解压:
tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz
修改配置文件
解压后进入conf 文件夹下将 spark-env.sh.template 改名为 spark-env.sh,并修改 spark-env.sh 文件添加信息:
export SCALA_HOME=/Users/yangyibo/Software/scala
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_92.jdk/Contents/Home
export SPARK_MASTER_IP=192.168.100.176
export SPARK_WORKER_MEMORY=512m
export master=spark://192.168.100.176:7070
上面的ip地址需要替换成你自己电脑的ip,可以使用ifconfig命令查看。
随后,修改 slaves.template 添加信息:
master
配置环境变量
执行如下命令打开配置文件:
vim ~/.bash_profile
添加如下信息:
export SPARK_HOME=你的spark路径
export PATH=$PATH:$SPARK_HOME/bin
添加结束后推出编辑配置文件,使用如下的命令使配置生效:
source ~/.bash_profile
验证安装情况
进入安装包的sbin 目录执行 start-all.sh 脚本
./start-all.sh

如果出现上面的错误,其实是没问题的,因为是单机版,所以ssh并不需要配置
启动后进入spark 的bin 目录运行spark-shell 进入终端。
./spark-shell
如果看到下面的结果,就证明你安装成功啦,你就可以直接在交互环境中编写scala和spark语句啦。
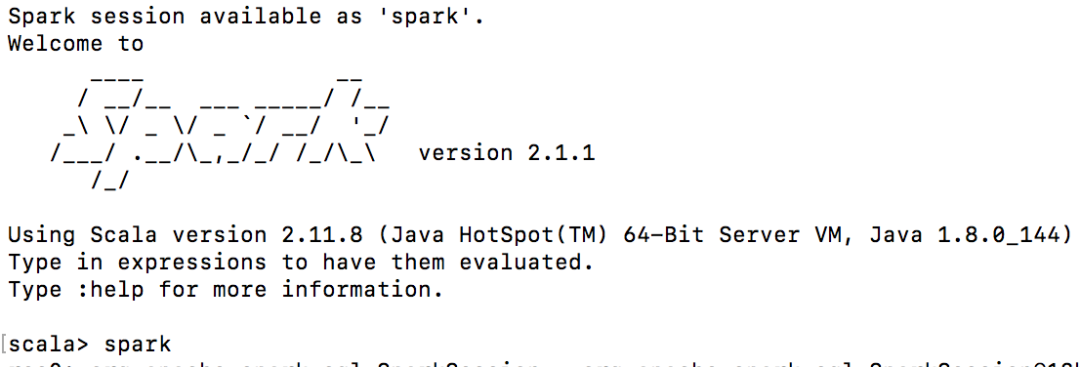
停止spark
进入spark的sbin目录,执行命令
$ ./stop-all.sh
3、使用IDEA创建Project
安装好了Spark,咱们先用IDEA测试一下。
打开IDEA之后,新建一个project:

选择scala工程:
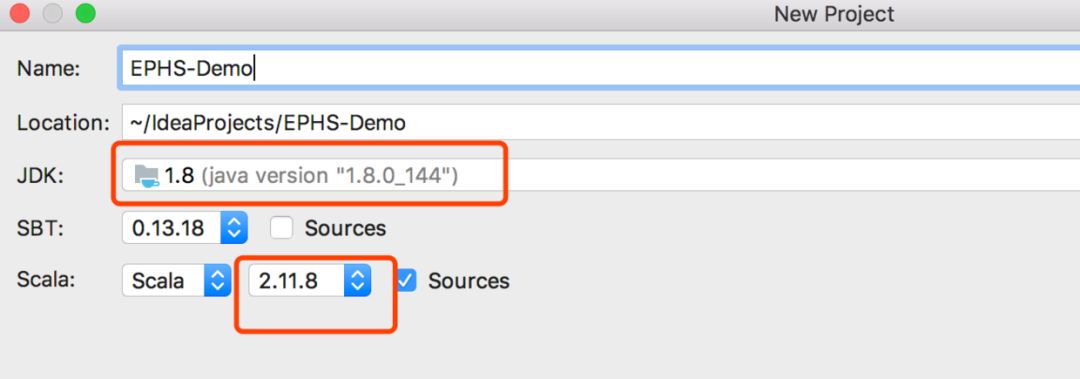
配置scala的版本和JDK的版本:
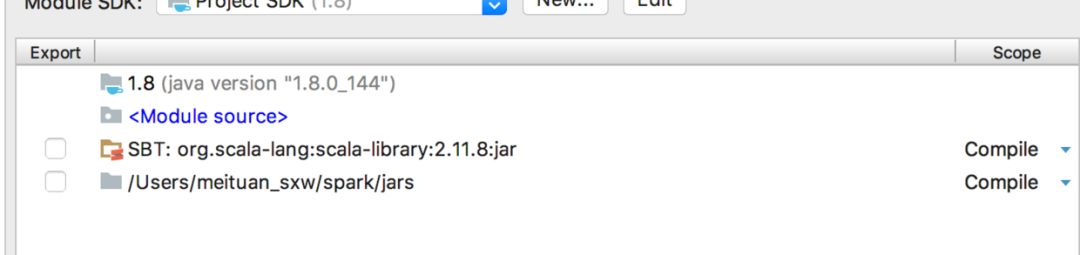
工程建好后,已经有scala和java的相关jar包了,咱们还得把spark相关的包进行导入:
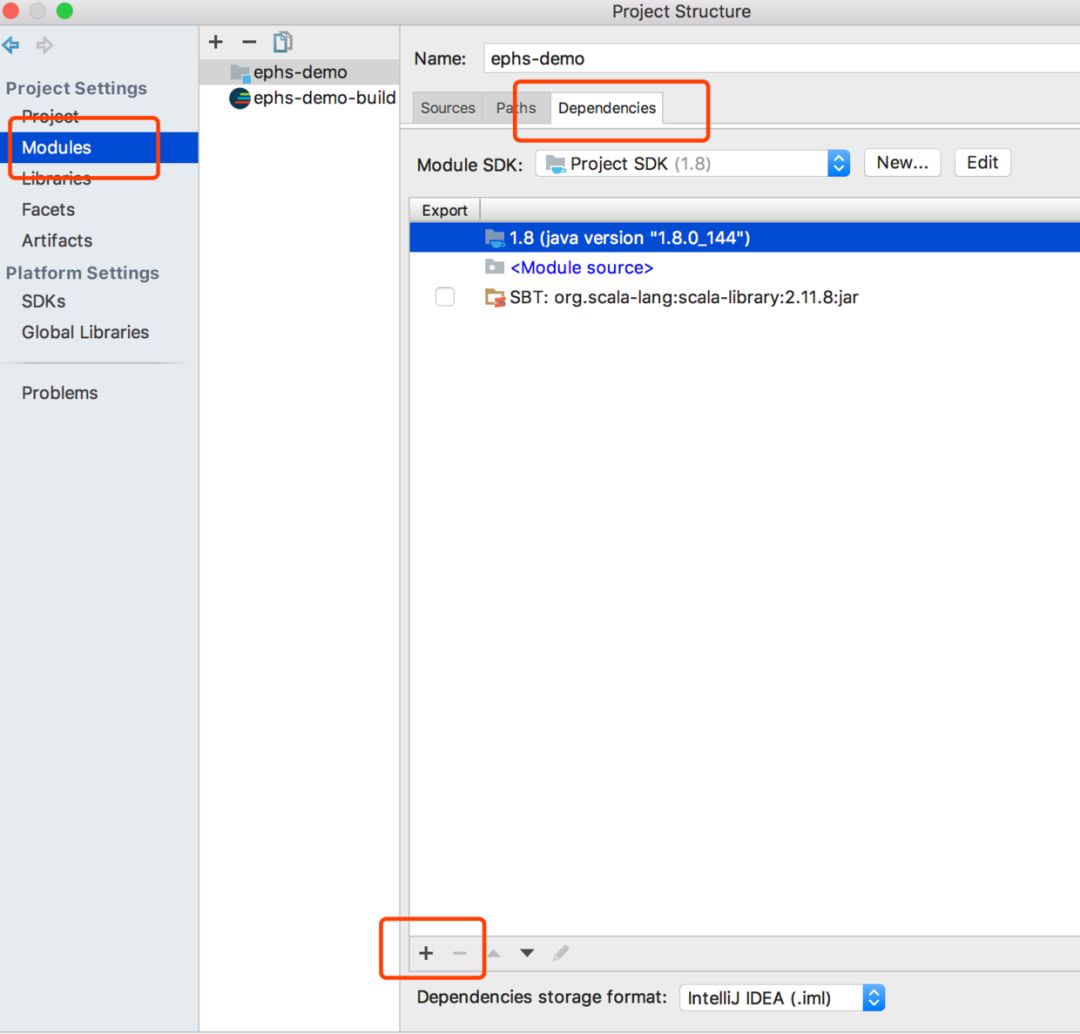
点击+号后,选择spark解压路径下jars文件夹即可:
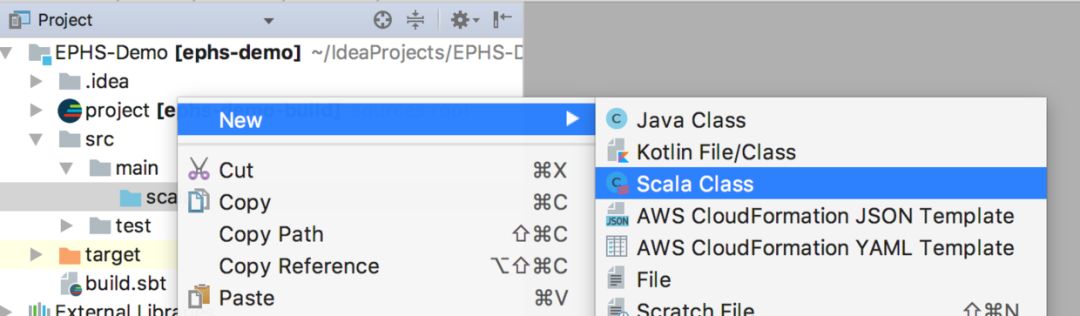
此时,新建一个Scala的Object:
测试一下sparkSession能否创建成功(spark2.x统一使用SparkSession),编写如下代码
import org.apache.spark.sql.SparkSession
object DemoTest {
def main(args:Array[String]): Unit= {
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
// .enableHiveSupport()
.config("spark.some.config.option", "some-value")
.getOrCreate()
import spark.implicits._
}
}
直接右键点击run执行程序是不行的,会报错:

因此需要配置运行环境:
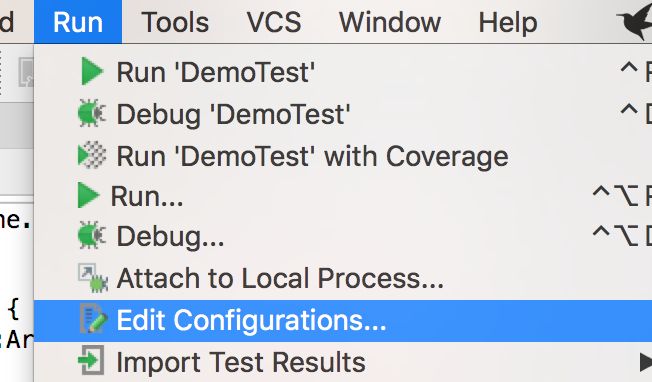
输入如下配置:
再次运行,执行成功,打印了一大堆日志,就不贴了。
上午被一个错误折腾了半天,给大家贴出来看看,如果你运行时发现如下错误:

这种的话一般是scala的包冲突了,找了半天,在jdk下面的包中,也有scala的包,把它删掉就好了:
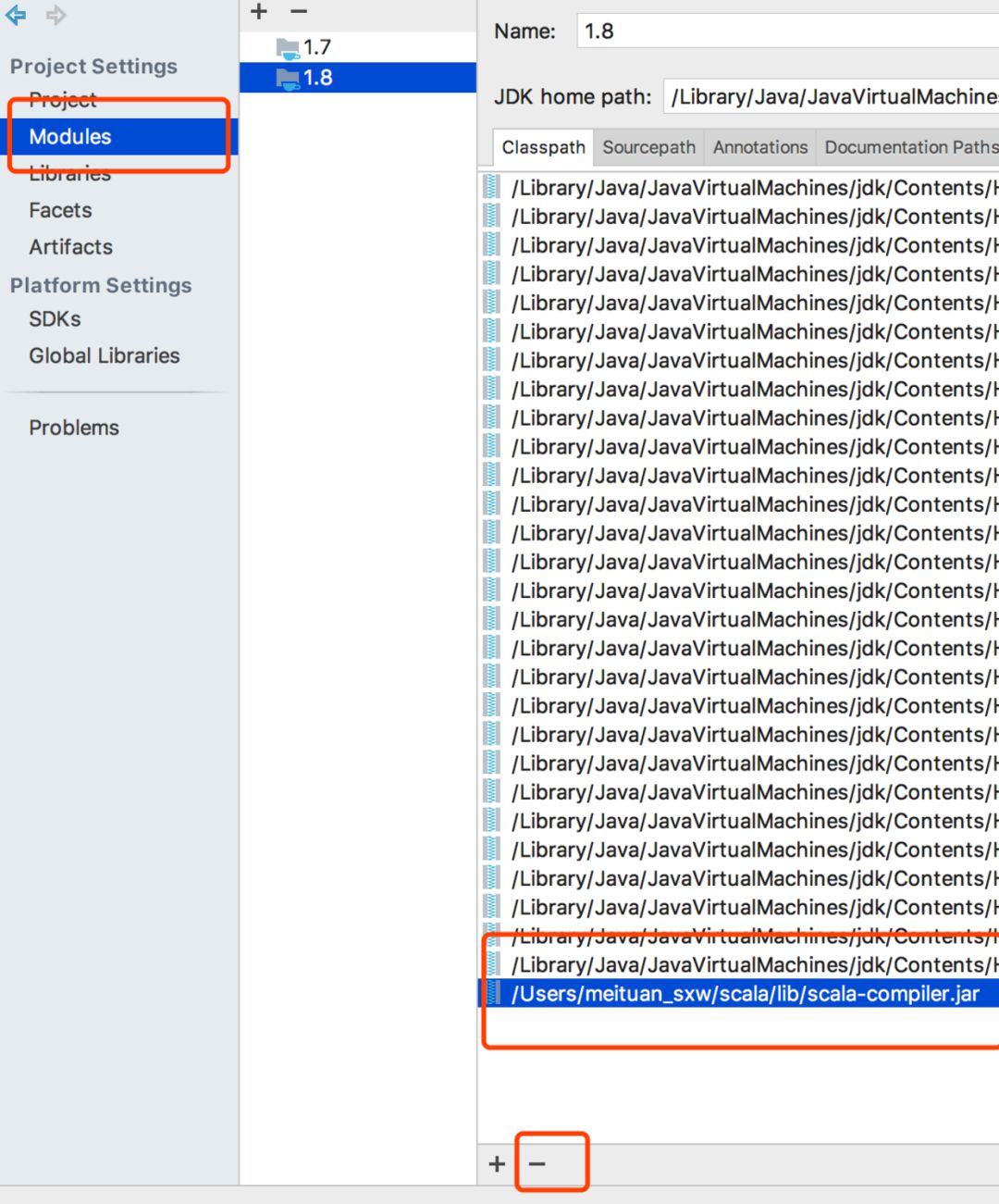
至此,spark安装及运行成功!
4、Hadoop安装及配置
先去官网下载安装包:https://hadoop.apache.org/releases.html,我下载了一个相对新的版本:
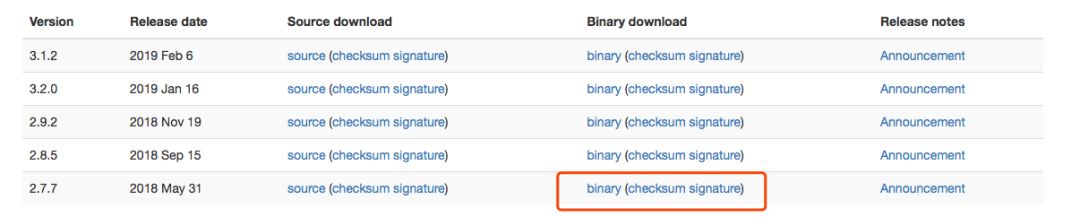
下载之后还是放到指定的位置解压并重命名:
tar -zxvf hadoop-2.7.7.tar
mv hadoop-2.7.7 hadoop
修改/etc/hadoop下的配置文件:
修改/etc/hadoop/core-site.xml
第二项的路径需要根据你的电脑实际路径进行配置。
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://localhost:9000value>
<description>The name of the default file system.description>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/Users/meituan_sxw/hadoop/tmpvalue>
<description>A base for other temporary directories.description>
property>
<property>
<name>io.native.lib.availablename>
<value>falsevalue>
<description>default value is true:Should native hadoop libraries, if present, be used.description>
property>
configuration>
修改hdfs-site.xml
<property>
<name>dfs.replicationname>
<value>1value>
property>
修改yarn-site.xml
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
修改mapred-site.xml
首先执行下面的命令,创建mapred-site.xml:
cp mapred-site.xml.template mapred-site.xml
随后进行修改:
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
<final>truefinal>
property>
修改完之后,将Hadoop添加至环境变量中:
vim ~/.bash_profile
添加如下内容:
export HADOOP_HOME=/Users/meituan_sxw/hadoop
export HADOOP_PREFIX=$HADOOP_HOME
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
当然还需要让修改的环境变量生效:
source ~/.bash_profile
接下来,就是启动Hadoop了,首先对NameNode进行格式化:
hadoop namenode -format
在这里,报错了:

原因就是core-site.xml中的hadoop.tmp.dir属性我没有修改,这里要修改为自己电脑的路径,同时创建相应的文件夹,并赋予777的权限:
sudo chmod -R a+w /Users/meituan_sxw/hadoop
然后进行格式化:
hadoop namenode -format
成功格式化:
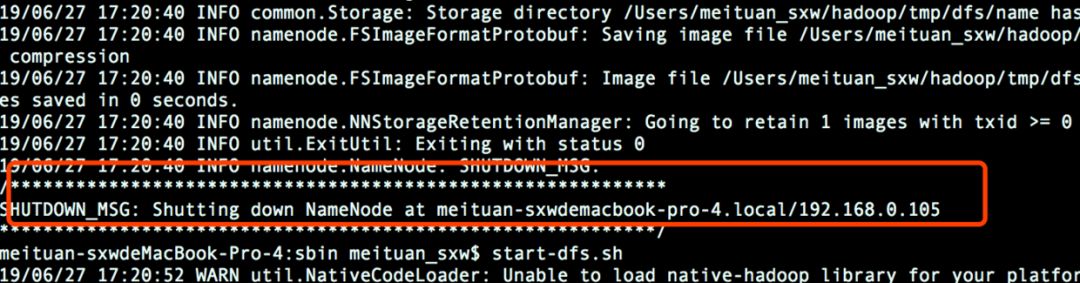
接下来,在sbin目录下启动hdfs和yarn:
start-dfs.sh
start-yarn.sh
使用jps命令查看是否启动成功:
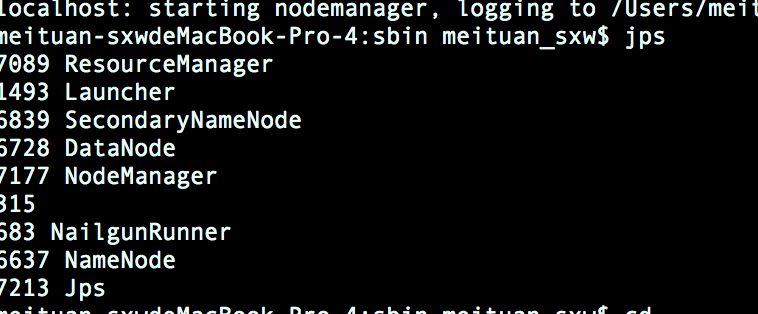
关闭hadoop,同样在sbin路径下执行:
stop-hdfs.sh
stop-yarn.sh
每次想要重新启动hadoop的时候,需要先关闭hadoop,再清除hadoop.tmp.dir下的文件,随后格式化namenode,最后再启动hdfs和yarn,少一步都有可能导致启动失败。这里小编踩过的坑就是没有清除hadoop.tmp.dir下的文件,导致每次启动时datanode没有启动成功。
5、Hive安装及配置
还是去官网下载一个Hive吧:https://hive.apache.org/downloads.html,一路点点点:
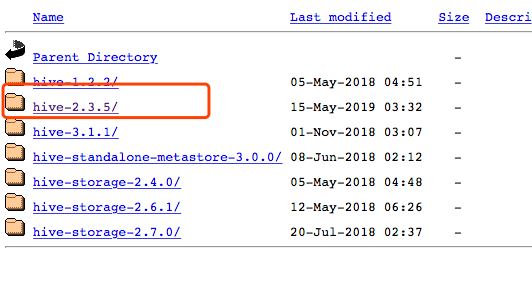
下载后还是先解压再重命名:
tar -zxvf apache-hive-2.3.5-bin.tar
mv apache-hive-2.3.5-bin hive
配置环境变量:
export HIVE_HOME=/Users/meituan_sxw/hive
export PATH=$HIVE_HOME/bin:$PATH
接下来修改Hive的配置文件,在conf路径下:
cp hive-env.sh.template hive-env.sh
cp hive-default.xml.template hive-site.xml
修改 hive-env.sh
HADOOP_HOME=/Users/meituan_sxw/hadoop
export HIVE_CONF_DIR=/Users/meituan_sxw/hive/conf
export HIVE_AUX_JARS_PATH=/Users/meituan_sxw/hive/lib
修改hive-site.xml
首先,将所有的${system:java.io.tmpdir} 和 ${system:user.name}替换,这里随便换一下就好,如果不换,会报如下的错误:

随后,根据name找到如下四项,进行修改(注意这里是修改,而不是追加,即根据name找到对应的位置,再把value进行替换),后面两项是你本地的mysql用户名和密码:
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=falsevalue>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>123456value>
property>
接下来,需要下载一个mysql包放到hive的lib路径下,下载地址为:https://mvnrepository.com/artifact/mysql/mysql-connector-java
我这里下载的一个低版本的:

随后,为hive创建HDFS目录:
hdfs dfs -mkdir -p /usr/hive/warehouse
hdfs dfs -mkdir -p /usr/hive/tmp
hdfs dfs -mkdir -p /usr/hive/log
hdfs dfs -chmod -R 777 /usr/hive
可以查看有没有创建成功,每次重启hadoop都需要重新创建:

接下来,在hive中的bin路径下,初始化数据库:
schematool -initSchema -dbType mysql
登陆mysql中查看:
mysql -u root -p
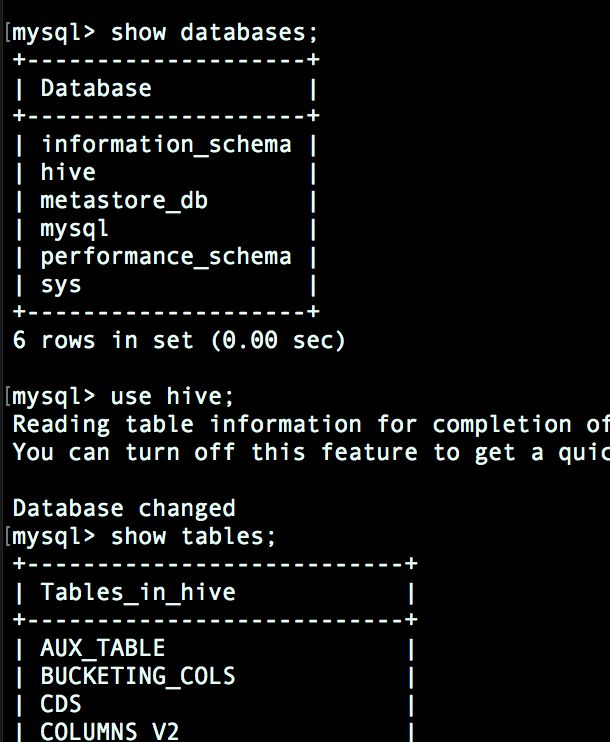
退出mysql,输入hive,启动成功:

我们可以写一个简单的建表语句测试一下:
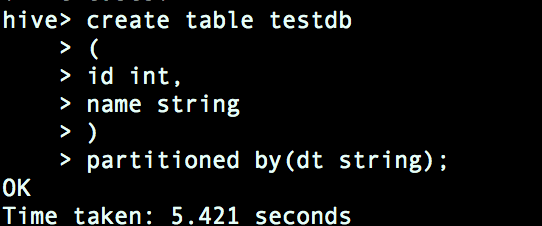
可以发现,成功创建:

6、Spark和Hive连通
万事俱备,只欠东风!最后一步,我们来将spark和hive进行联通!
首先,我们需要在刚才创建的project的resources路径下添加hive-site.xml文件。如果有resources路径的话直接添加即可,如果没有resources路径的话,创建一个resources文件夹,并选择将其作为resources路径:
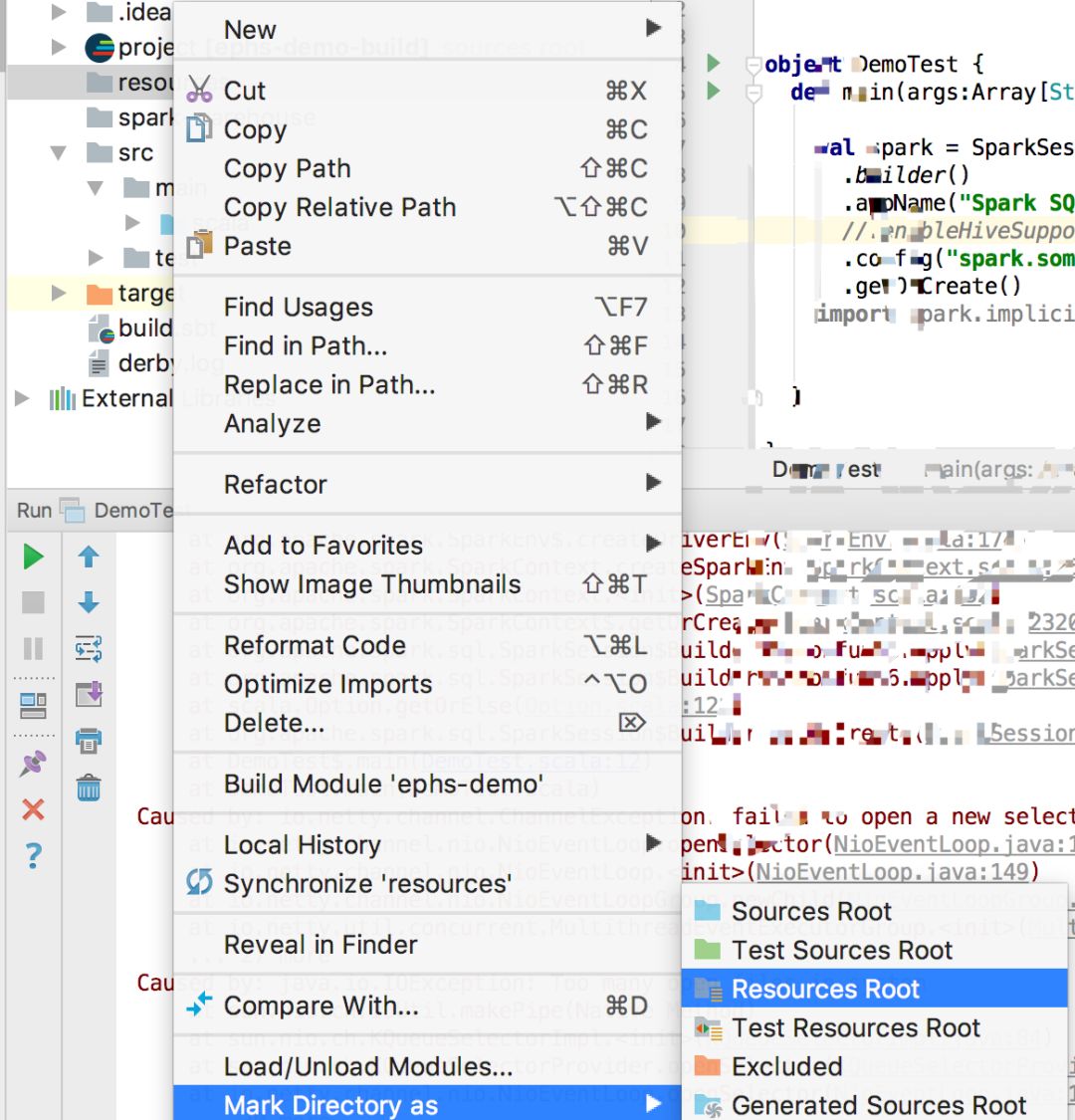
在hive-site.xml中添加跟刚才一样的内容:
xml version="1.0"?>
xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=falsevalue>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>0845value>
property>
configuration>
接下来,将刚才下载的mysql的jar包也添加到项目中来:
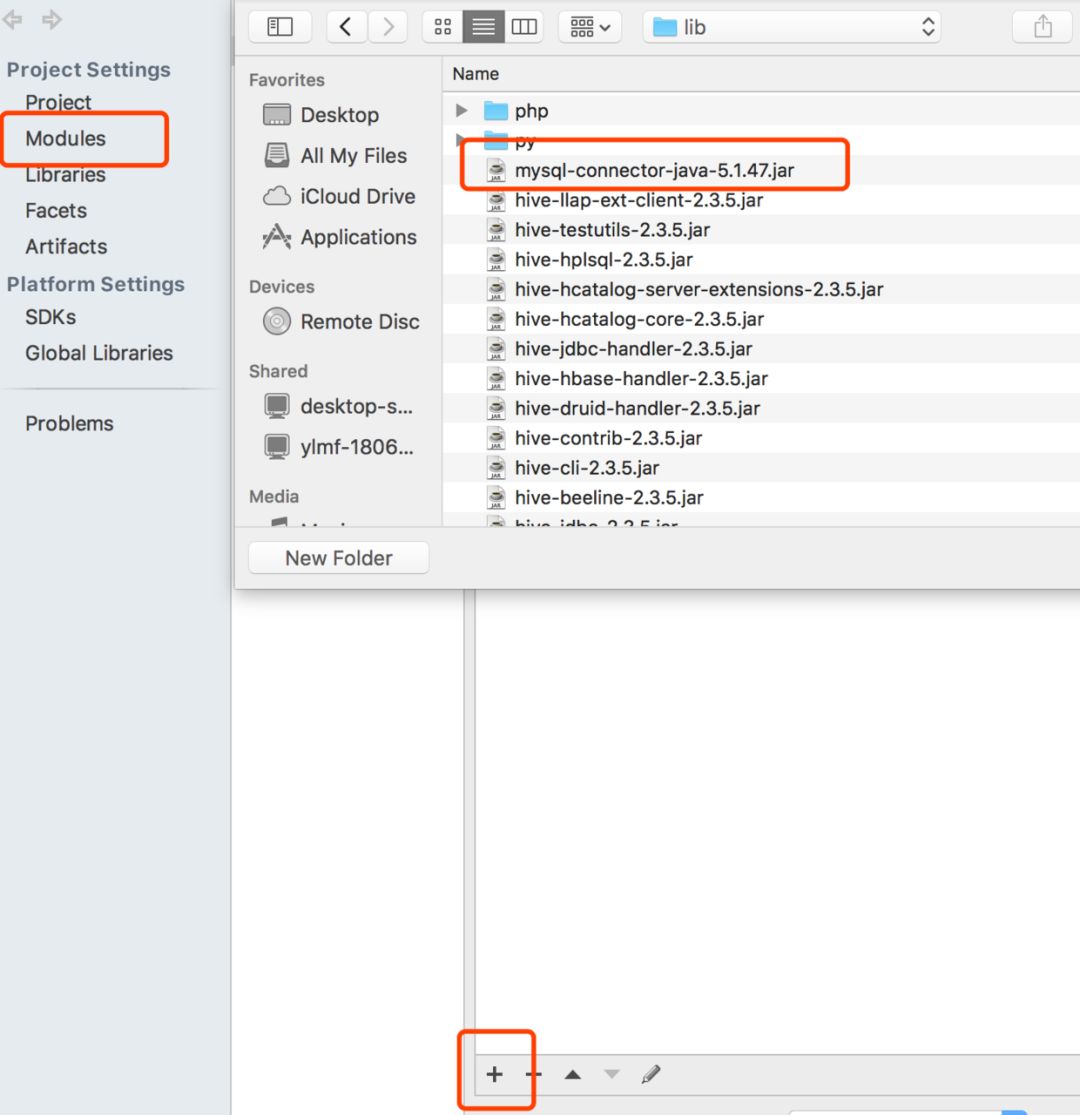
接下来咱们在spark sql代码中创建一个数据表,并插入两行数据:
def main(args:Array[String]): Unit= {
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.enableHiveSupport()
.config("spark.some.config.option", "some-value")
.getOrCreate()
import spark.implicits._
spark.sql(
s"""
CREATE TABLE IF NOT EXISTS usersdb1(
user_id int,
user_name string
)
PARTITIONED BY (dt string)
""")
val df = Seq(
(1, "First Value","20190627"),
(2, "Second Value", "20190628")
).toDF("user_id","user_name","dt")
df.show()
df.createOrReplaceTempView("outputdata")
spark.sql("select * from outputdata").show()
spark.sql("set hive.exec.dynamic.partition.mode=nonstrict")
spark.sql(
s"""
|insert overwrite table usersdb1 PARTITION (dt)
|select
| user_id,
| user_name,
| dt
|from
| outputdata
""".stripMargin)
spark.sql(
"""
|select * from usersdb1 where dt=20190627
""".stripMargin).show()
}
在hive下查看下数据有没有写入:

成功!不过还是再说明两点,一是sparkSession创建时.enableHiveSupport()一定要打开,而是插入数据库时,最好 指定spark.sql("set hive.exec.dynamic.partition.mode=nonstrict"),至于为什么,咱们后面再说,一下子说这么多我怕你也撑不住,哈哈。
虽然折腾了一天,不过终于配置成功了!下一篇咱们先来讲讲数据的导入,主要是spark sql如何创建dataframe,期待一下吧!
专注于数据科学领域的知识分享
欢迎在文章下方留言与交流
推荐阅读
阿里P10、腾讯T4、华为18,互联网公司职级、薪资、股权大揭秘
高考志愿怎么报?582个专业,1281个本科院校,你会如何选择?
揭秘程序员在「外包」、「技术导向型」和「业务驱动型」公司的日常生活
干货 | 17个机器学习的常用算法!
Kaggle大牛小姐姐自述:我是怎么成为竞赛中Top 0.3%的?
















 4616
4616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









