





自然语言处理NLP相对来说,是比较火的方向,分词模型很多,选起来容易眼花缭乱,我最开始使用过结巴分词,简单易用。后来又看到了hanLP,介绍上说,它是用《人民日报》语料库训练的,深得我心,于是拿来用用。
hanLP的git连接:https://github.com/hankcs/HanLP/
hanLP的官网:https://www.hanlp.com/
一、anaconda安装Python3.6
因为hanlp依赖TensorFlow,但TensorFlow不支持Python3.6以上版本,所以我们需要先有一个Python3.6的环境。
但社区版pycharm不支持直接从conda直接创建Python环境,所以干脆直接安装一个anaconda吧!
我们在镜像网址,下载一个版本号吻合的anaconda:
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
我选择的安装文件是:Anaconda3-5.2.0-Windows-x86_64.exe,适合Python3.6版本。
打开exe,一直next,直到安装,仔细观察进度条,会发现上面有Extract:Python-3.6.5的标识,说明我们安装的这个anaconda是Python3.6的。
安装的过程中,记住安装路径。
安装会比较慢,耐心等待即可。
到后面会提示Install Microsoft VSCode,因为我们使用的是pycharm,所以点击skip就行。
最后点击finsh就行,两个learn的复选框,可以取消勾选。

二、pycharm配置Python3.6
我们已经安装完anaconda,并自带的Python3.6了,现在只要把它们配置到pycharm里就行了。
打开pycharm,+New Project,新建一个工程fenci。

File——Settings,快捷键ctrl+alt+s。打开Settings配置。
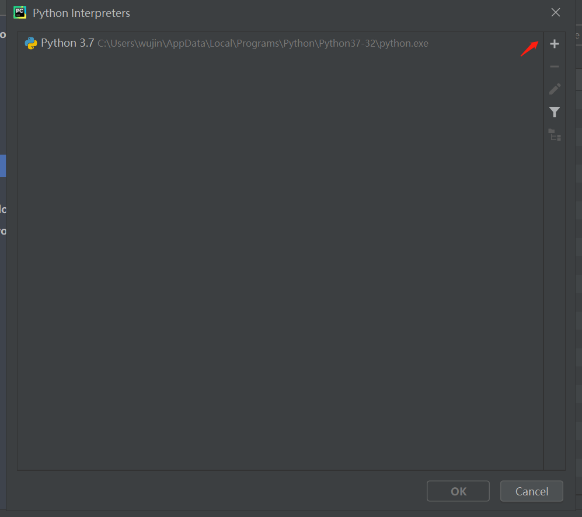
在Settings对话框,Project:fenci中的Python Interpreter中,点击show All。

在Python Interpreter中点击+。
在Add Python Interpreter中,选择Virtualenv Environment,勾选 Existing environment,Interpreter选择anaconda3安装目录下的python.exe。点击ok。
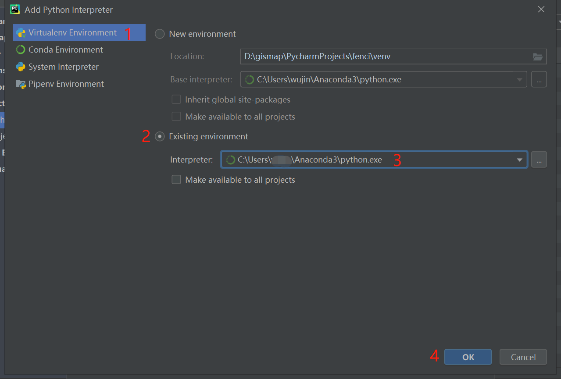
一路ok回去,能看到anaconda下的Python已经预装了好多包,这么多包,觉得自己还可以搞点别的事儿。
三、安装hanLP
安装hanlp的时候,就能直接把tensorflow安装上。
以管理员身份,打开cmd。
一路切换到anaconda3安装目录下的scripts文件夹,既pip所在的文件夹,如C:Users**Anaconda3Scripts。
输入pip install pyhanlp。
安装完成后,下载https://file.hankcs.com/hanlp/data-for-1.7.5.zip ,下载完成后,将data-for-1.7.5.zip重命名为data-for-1.7.8.zip,放在文件夹C:Users**Anaconda3Libsite-packagespyhanlpstatic。
(
我们安装的是hanlp1.x版本,因为电脑配置不够的话,安装hanlp2.x版本会失败。
但是hanlp1.x版本,依赖java环境。具体可参加:https://github.com/hankcs/pyhanlp
但如果电脑比较新,配置比较给力,尤其是ios或linux操作系统,可以安装hanlp2.x版本,pip install hanlp。
一次能安装成功,是运气。
如果安装不成功,遇到什么问题解决什么问题吧。
我遇到过的部分问题罗列如下:
1.没有wrapt:
报错:Cannot uninstall 'wrapt'. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall.
因为报这个错,安装就退出了,所以必须解决。
那就安装一个wrapt,--igonre-installed,是忽略已安装版本。
pip install wrapt --ignore-installed
2.升级pip
警告:You are using pip version 10.0.1, however version 20.3b1 is available.
升级pip:pip install --upgrade pip
3.没有msgpack
警告:distributed 1.21.8 requires msgpack, which is not installed.
安装msgback:pip install msgback
4.tensorflow没有Microsoft Visual C++环境
在Microsoft网站上下载vc的安装包,选择电脑操作系统版本相对应安装文件,点击next。
https://www.microsoft.com/zh-CN/download/details.aspx?id=53587

文件下载好了,直接安装即可。
如果安装失败,可能是有版本冲突,去控制面板——程序——程序和功能,将其他版本的Microsoft Visual C++都卸载掉,重新安装。
5.numpy版本高
卸载numpy,重新安装。
pip uninstall numpy
pip install numpy==1.16.0
6.header与library版本不统一
卸载h5py,重新安装。
pip uninstall h5py
pip install h5py
)
四、测试
官方的测试脚本:
from pyhanlp import *
print(HanLP.segment('你好,欢迎在Python中调用HanLP的API'))运行,在控制台上,会打印出:
[你好/vl, ,/w, 欢迎/v, 在/p, Python/nx, 中/f, 调用/v, HanLP/nx, 的/ude1, API/nx]
说明运行成功了。
文字后面的标签,是词性标注,词性标注可参见:
http://www.hankcs.com/nlp/part-of-speech-tagging.html#h2-8
五、房源描述属性词频统计
测试通过后,我们就要根据自己的需求进行脚本编写了。
我要做的是,统计房源描述的词频。
脚本如下:
from pyhanlp import *
f = open(r'beikefangyuanall.txt','r',encoding='utf-8')
flines = f.readlines()
result = {}
for idx,line in enumerate(flines):
# if idx>10:
# break
# 每条记录长这样: 朝阳 北京朝阳在售二手房 /ershoufang/chaoyang/ 芍药居北里 2003年商品房,小区中间,带电梯 https://bj.ke.com/ershoufang/101107773062.html 芍药居北里 https://bj.ke.com/xiaoqu/1111027379657/ 中楼层(共24层)|2003年建|2室1厅|91.69平米|西 706万 单价76998.6元/平米 44人关注/4月前发布 近地铁|VR看装修 116.435619 39.986142
segs = HanLP.segment(line.strip('n').split('t')[3])
for term in segs:
if not result.__contains__(term.word):
result[term.word] = 1
else:
result[term.word] += 1
result_sort = sorted(result.items(),key=lambda item:item[1],reverse=True)
fnew = open(r'cipin.txt','a',encoding='utf-8')
for r in result_sort:
fnew.write(r[0]+'t'+str(r[1])+'n')
f.close()
fnew.close()结果如下,对统计出来的词频进行了正序排列:

南北通透,满五唯一、好楼层,大概是最多的描述词汇了,跟我们的生活经验是相符的,很好。
六、总结
总的来说,脚本不难写,比较麻烦的是安装包、配环境,需要花些心思。
简单的词频统计,调包就行,但有定制化的需求,可能需要重新训练模型了。















 439
439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









