





给想要了解spark sql底层解析原理的小伙伴们!
推荐阅读:spark sql解析过程中对tree的遍历(源码详解)
前言
Spark sql通过Analyzer中 定义的rule把Parsed Logical Plan解析成 Analyzed Logical Plan;
通过Optimizer定义的rule把 Analyzed Logical Plan 优化成 Optimized Logical Plan 。
下图是RuleExecutor类 的继承关系,Analyzer、Optimizer都继承了RuleExecutor。
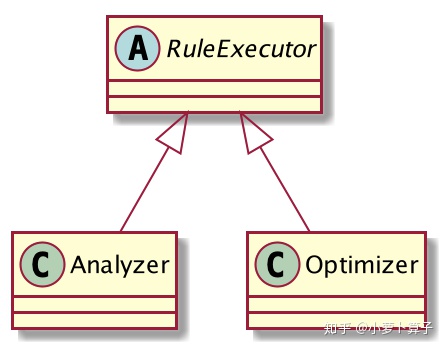
Analyzer、Optimizer定义了一系列 rule,而RuleExecutor 定义了一个 rules 执行框架,即怎么把一批批规则应用在一个 plan 上得到一个新的 plan。
规则是怎么执行的 ?
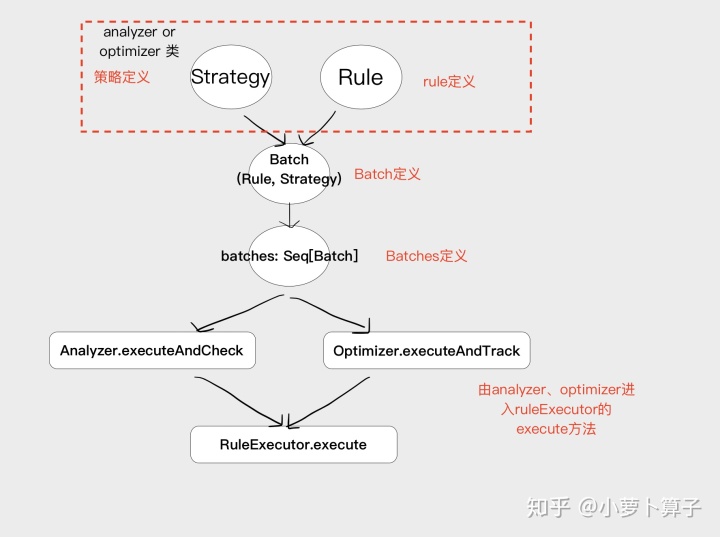
RuleExecutor包含以下主要对象
abstract Strategy
Strategy 定义了Rule处理的迭代策略,有些Rule只用执行一次,有些需要多次直到达到某种效果。
abstract Strategy有两个实现类 :Once、FixedPoint
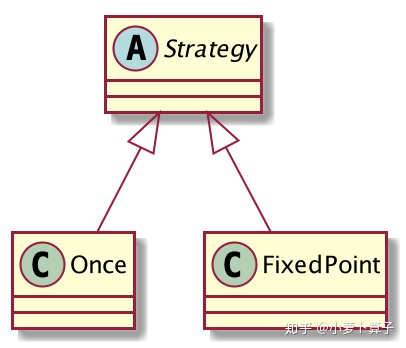
Once
once定义了只运行一次的规则,即maxIterations = 1的 Strategy
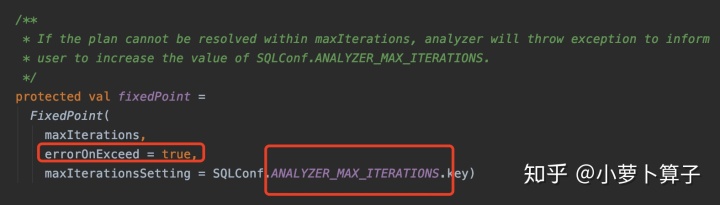
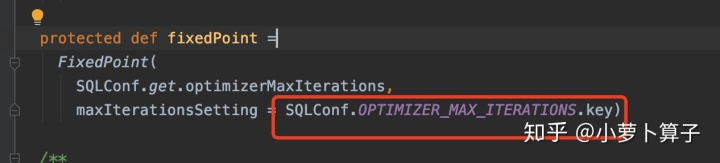
case FixedPoint
fixedPoint 定义多于1次的迭代策略,maxIterations 通过配置文件获取。
case Analyzer 和 Optimizer 中分 别定义自己的fixedPoint,最大迭代次数,分别从
spark.sql.analyzer.maxIterations or spark.sql.optimizer.maxIterations 这两个配置参数里获取,默认100
Batch(包含一个或多个Rule及一个策略)
Batch 用来表示一组同类的规则。
每个Batch的Rule使用相同的策略(执行一次 or 达到fixedPoint),便于管理
/** A batch of rules. */
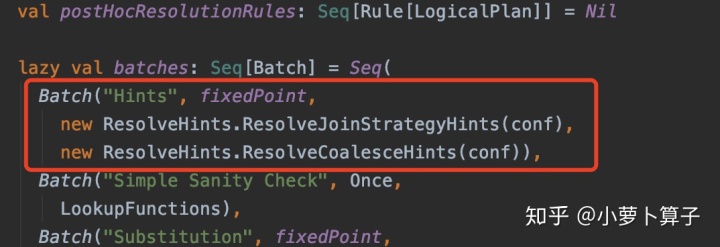
Analyzer 和 Optimizer 中分 别定义自己的batch,比如Analyzer中 定义的【Hints】,策略用的是FixedPoint,【Hints】中包含了两个与处理【hint】相关的rule:ResolveHints.ResolveJoinStrategyHints
ResolveHints.ResolveCoalesceHints
batches: Seq[Batch](Batch队列)
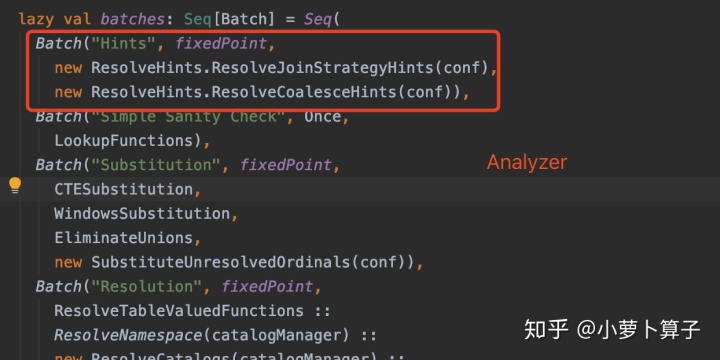
RuleExecutor 包含了一个 protected def batches: Seq[Batch] 方法,用来获取一系列 Batch(Batch队列),这些 Batch 都会在 execute 中执行。所有继承 RuleExecutor(Analyzer 和 Optimizer)都必须实现该方法,提供自己的 Seq[Batch]。
Analyzer 和 Optimizer 中 提供各自己的 batches:
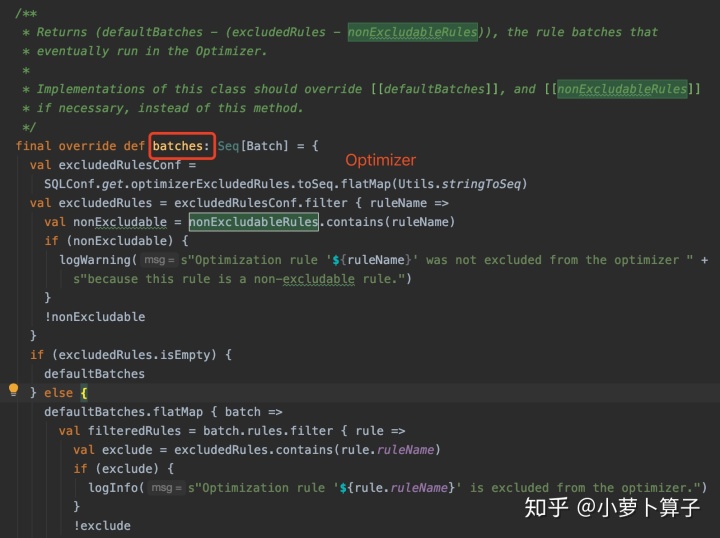
Optimizer 中的batches略显复杂,Optimizer定义了 三种batches:defaultBatches、excludedRules 、 nonExcludableRules
最终要被执行的batches为:defaultBatches - (excludedRules - nonExcludableRules)
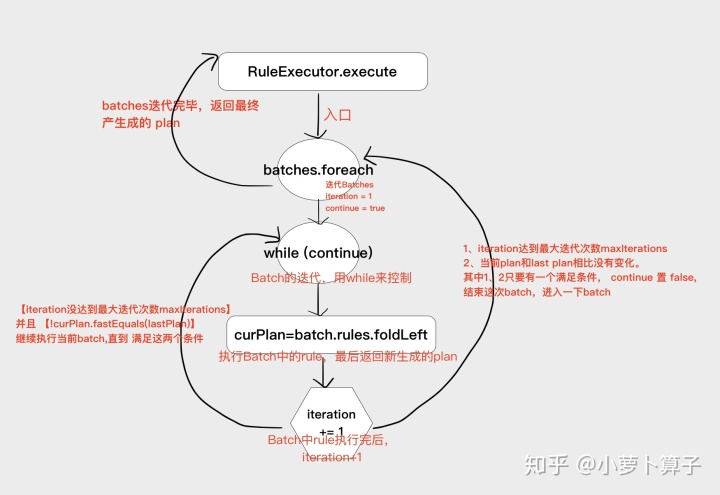
execute(核心方法)
execute方法遍历batches中的每个Batch,再用Batch中的每个Rule处理plan。
while (continue) 的终止条件:
达到最大迭代次数maxIterations 或者 当前plan和last plan相比没有变化
执行流程
源码详解
//传入参数plan是当前的执行计划
推荐阅读:
spark sql解析过程中对tree的遍历(源码详解)mp.weixin.qq.com
Hey!
我是小萝卜算子
欢迎扫码关注公众号
在成为最厉害最厉害最厉害的道路上
很高兴认识你















 2029
2029











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









