






本文目录:
1.字典与哈希表
2.hash构造方法
3.hash冲突及解决
4.冲突解决:开放定址法
5.如何避免冲突:小的装填因子和好的散列函数
1.字典与哈希表
字典的内部结构是怎样的呢?PyDictObject对象就是dict的内部实现。
(1)哈希表 (hash tables)
哈希表(也叫散列表),根据关键值对(Key-value)而直接进行访问的数据结构。它通过把key和value映射到表中一个位置来访问记录,这种查询速度非常快,更新也快。而这个映射函数叫做哈希函数,存放值的数组叫做哈希表。 哈希函数的实现方式决定了哈希表的搜索效率。具体操作过程是:
- 数据添加:把key通过哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。
- 数据查询:再次使用哈希函数将key转换为对应的数组下标,并定位到数组的位置获取value。
但是,对key进行hash的时候,不同的key可能hash出来的结果是一样的,尤其是数据量增多的时候,这个问题叫做哈希冲突。如果解决这种冲突情况呢?通常的做法有两种,一种是链接法,另一种是开放寻址法,Python选择后者。
(2)开放寻址法(open addressing)
开放寻址法中,所有的元素都存放在散列表里,当产生哈希冲突时,通过一个探测函数计算出下一个候选位置,如果下一个获选位置还是有冲突,那么不断通过探测函数往下找,直到找个一个空槽来存放待插入元素。
set集合和dict一样也是基于散列表的,只是他的表元只包含值的引用而没有对键的引用,其他的和dict基本上是一致的,所以在此就不再多说了。
>>>hash('test') # 字符串
2314058222102390712
>>> hash(1) # 数字
1
>>> hash(str([1,2,3])) # 集合
1335416675971793195
>>> hash(str(sorted({'1':1}))) # 字典
7666464346782421378
>>>(3)字典dict操作
>>> dict1 = {'a': 1, 'b': 2, 'b': '3'}
>>> dict1['b'] # 根据key取出值value
'3'
>>> dict1
{'a': 1, 'b': '3'}
>>>list(dict1 .keys())[list(dict1 .values()).index(1)] #
'a' # 根据value去除key
>>> dict1['d']=4 #增加新的元素
>>> del dict1['d'] #删除元素
>>> dict1.keys() # 以列表返回一个字典所有的键
>>> dict1.values() # 以列表返回字典中的所有值
>>> dict1.items() # 以列表返回可遍历的(键, 值) 元组数组2.hash构造方法
除留余数法最为常用:
1. 直接寻址法:取关键字或关键字的某个线性函数值为散列地址。即H(key)=key或H(key) = a?key + b,其中a和b为常数(这种散列函数叫做自身函数)
2. 数字分析法:分析一组数据,比如一组员工的出生年月日,这时我们发现出生年月日的前几位数字大体相同,这样的话,出现冲突的几率就会很大,但是我们发现年月日的后几位表示月份和具体日期的数字差别很大,如果用后面的数字来构成散列地址,则冲突的几率会明显降低。因此数字分析法就是找出数字的规律,尽可能利用这些数据来构造冲突几率较低的散列地址。
3. 平方取中法:取关键字平方后的中间几位作为散列地址。
4. 折叠法:将关键字分割成位数相同的几部分,最后一部分位数可以不同,然后取这几部分的叠加和(去除进位)作为散列地址。
5. 随机数法:选择一随机函数,取关键字的随机值作为散列地址,通常用于关键字长度不同的场合。
6. 除留余数法:取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。即 H(key) = key MOD p, p<=m。不仅可以对关键字直接取模,也可在折叠、平方取中等运算之后取模。对p的选择很重要,一般取素数或m,若p选的不好,容易产生同义词。
3.hash冲突及解决
hash冲突在所难免,解决冲突是一个复杂问题。冲突主要取决于:
(1)与散列函数有关,一个好的散列函数的值应尽可能平均分布。
(2)与解决冲突的哈希冲突函数有关。
(3)与负载因子的大小。太大不一定就好,而且浪费空间严重,负载因子和散列函数是联动的。
解决冲突的办法:
(1)开放定址法:线性探查法、平方探查法、伪随机序列法、双哈希函数法。
(2)拉链法:把所有同义词,即hash值相同的记录,用单链表连接起来。最简单的办法如下:如果两个键映射到了同一个位置,就在这个位置存储一个链表。链表短还行,查找不慢;但链表很长就悲剧了
(1)冲突解决:开放定址法
当一个关键字和另一个关键字发生冲突时,使用某种探测技术在Hash表中形成一个探测序列,然后沿着这个探测序列依次查找下去,当碰到一个空的单元时,则插入其中。基本公式为:hash(key) = (hash(key)+di)mod TableSize。其中di为增量序列,TableSize为表长。根据di的不同我们又可以分为线性探测,平方(二次)探测,双散列探测。
1)线性探测
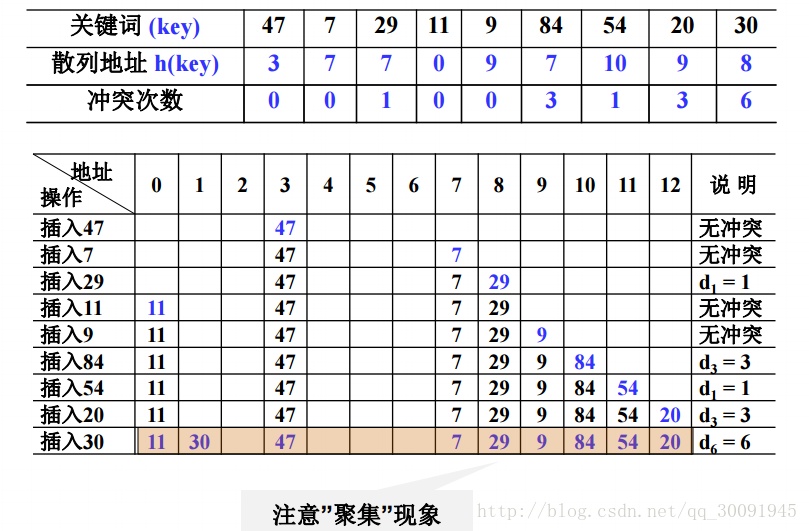
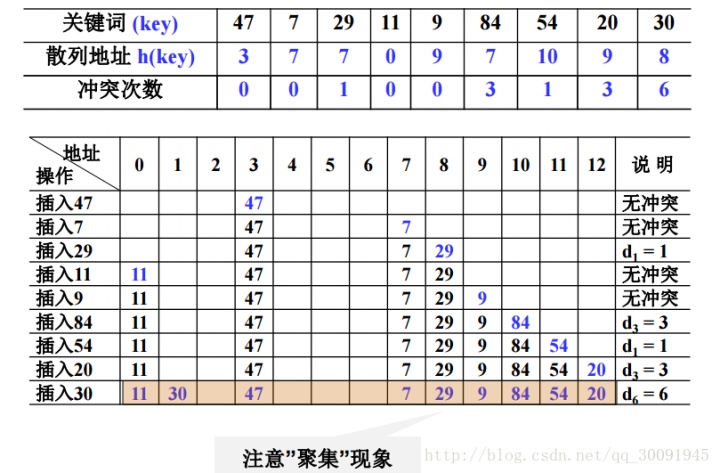
以增量序列 1,2,……,(TableSize -1)循环试探下一个存储地址,即di = i。如果table[index+di]为空则进行插入,反之试探下一个增量。但是线性探测也有弊端,就是会造成元素聚集现象,降低查找效率。具体例子如下图: (这个例子中是除以11)
2)平方探测
以增量序列1,-1,4,-4…且q ≤ TableSize/2 循环试探下一个存储地址。
3)双散列探测
di 为i*h2(key),h2(key)是另一个散列函数。探测序列成:h2(key),2h2(key),3h2(key),……。对任意的key,h2(key) ≠ 0 !探测序列还应该保证所有的散列存储单元都应该能够被探测到。选择以下形式有良好的效果:
h2(key) = p - (key mod p)
其中:p < TableSize,p、TableSize都是素数。
(2)如何避免冲突
(1)较低的装填因子:即已占用的位置/总的位置数,一旦填装因子超过0.7,就该调整散列表的长度。
(2)良好的散列函数:良好的散列函数让数组中的值呈均匀分布。糟糕的散列函数让值扎堆,导致大量的冲突。
什么样的散列函数是良好的呢?你根本不用操心——天塌下来有高个子顶着。如果你好奇,可研究一下SHA函数。你可将它用作散列函数














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









