






作者 | Denis Antyukhov
来源 | Medium
编辑 | 代码医生团队
基于神经概率语言模型的特征提取器,例如与多种下游NLP任务相关的BERT提取特征。因此它们有时被称为自然语言理解(NLU)模块。
这些特征还可以用于基于实例的学习,其依赖于计算查询与训练样本的相似性。为了证明这一点,将使用BERT特征提取为文本构建最近邻搜索引擎。
这个实验的计划是:
获得预先训练的BERT模型检查点
提取针对推理优化的子图
使用tf.Estimator创建特征提取器
用T-SNE和嵌入式投影仪探索向量空间
实现最近邻搜索引擎
用数学加速最近邻查询
示例:构建电影推荐系统
问题和解答
本指南中包含哪些内容?
本指南包含两个实现:BERT文本特征提取器和最近邻居搜索引擎。
这个指南是谁?
本指南对于有兴趣使用BERT进行自然语言理解任务的研究人员非常有用。它也可以作为与tf.Estimator API接口的工作示例。
需要做些什么?
对于熟悉TensorFlow的读者来说,完成本指南大约需要30分钟。
相关代码
这个实验的代码可以在Colab中找到。另外,查看为BERT实验设置的存储库:它包含奖励内容。
https://colab.research.google.com/drive/1ra7zPFnB2nWtoAc0U5bLp0rWuPWb6vu4
https://github.com/gaphex/bert_experimental
第1步:获得预先训练的模型
从预先训练的BERT检查点开始。出于演示目的,将使用由Google工程师预先训练的无框架英语模型。
为了配置和优化图形以进行推理,将使用令人敬畏的bert-as-a-service存储库。此存储库允许通过TCP为远程客户端提供BERT模型。
拥有远程BERT服务器在多主机环境中是有益的。但是在实验的这一部分中,将专注于创建一个本地 (进程中)特征提取器。如果希望避免客户端 - 服务器体系结构引入的额外延迟和潜在故障模式,这将非常有用。
现在下载模型并安装包。
!wget https://storage.googleapis.com/bert_models/2019_05_30/wwm_uncased_L-24_H-1024_A-16.zip!unzip wwm_uncased_L-24_H-1024_A-16.zip!pip install bert-serving-server --no-deps第2步:优化推理图
通常要修改模型图,必须进行一些低级TensorFlow编程。但是由于bert-as-a-service,可以使用简单的CLI界面配置推理图。
import osimport tensorflow as tf from bert_serving.server.graph import optimize_graphfrom bert_serving.server.helper import get_args_parser MODEL_DIR = '/content/wwm_uncased_L-24_H-1024_A-16/' #@param {type:"string"}GRAPH_DIR = '/content/graph/' #@param {type:"string"}GRAPH_OUT = 'extractor.pbtxt' #@param {type:"string"}GPU_MFRAC = 0.2 #@param {type:"string"} POOL_STRAT = 'REDUCE_MEAN' #@param {type:"string"}POOL_LAYER = "-2" #@param {type:"string"}SEQ_LEN = "64" #@param {type:"string"} tf.gfile.MkDir(GRAPH_DIR) parser = get_args_parser()carg = parser.parse_args(args=['-model_dir', MODEL_DIR, "-graph_tmp_dir", GRAPH_DIR, '-max_seq_len', str(SEQ_LEN), '-pooling_layer', str(POOL_LAYER), '-pooling_strategy', POOL_STRAT, '-gpu_memory_fraction', str(GPU_MFRAC)]) tmpfi_name, config = optimize_graph(carg)graph_fout = os.path.join(GRAPH_DIR, GRAPH_OUT) tf.gfile.Rename( tmpfi_name, graph_fout, overwrite=True)print("Serialized graph to {}".format(graph_fout))有几个参数需要注意。
对于每个文本样本,BERT编码层输出一个形状的张量[ sequence_len,encoder_dim ],每个标记有一个向量。如果要获得固定的表示,需要应用某种池。
POOL_STRAT参数定义应用于编码层编号POOL_LAYER的池策略。默认值' REDUCE_MEAN '平均序列中所有标记的向量。当模型未经过微调时,此策略最适用于大多数句子级别的任务。另一个选项是NONE,在这种情况下根本不应用池。这对于命名实体识别或POS标记等单词级任务非常有用。有关这些选项的详细讨论,请查看韩晓的博文。
https://hanxiao.github.io/2019/01/02/Serving-Google-BERT-in-Production-using-Tensorflow-and-ZeroMQ/
SEQ_LEN影响模型处理的序列的最大长度。较小的值将几乎线性地增加模型推理速度。
运行上述命令将把模型图和权重成GraphDef将被序列化到一个对象pbtxt在文件GRAPH_OUT。该文件通常小于预先训练的模型,因为将删除训练所需的节点和变量。这导致了一个非常便携的解决方案:例如序列化后英语模型只需要380 MB。
第3步:创建特征提取器
现在将使用序列化图形来使用tf.Estimator API构建特征提取器。需要定义两件事:input_fn和model_fn
input_fn管理将数据导入模型。这包括执行整个文本预处理管道和为BERT 准备feed_dict。
首先,将每个文本样本转换为包含INPUT_NAMES 中列出的必要功能的tf.Example实例。该bert_tokenizer对象包含WordPiece词汇和执行文本预处理。之后,示例将按照feed_dict中的功能名称进行重新分组。
INPUT_NAMES = ['input_ids', 'input_mask', 'input_type_ids']bert_tokenizer = FullTokenizer(VOCAB_PATH) def build_feed_dict(texts): text_features = list(convert_lst_to_features( texts, SEQ_LEN, SEQ_LEN, bert_tokenizer, log, False, False)) target_shape = (len(texts), -1) feed_dict = {} for iname in INPUT_NAMES: features_i = np.array([getattr(f, iname) for f in text_features]) features_i = features_i.reshape(target_shape) features_i = features_i.astype("int32") feed_dict[iname] = features_i return feed_dicttf.Estimators有一个有趣的功能,可以在每次调用预测函数时重建并重新初始化整个计算图。因此,为了避免开销,将生成器传递给预测函数,并且生成器将在永无止境的循环中为模型生成特征。
def build_input_fn(container): def gen(): while True: try: yield build_feed_dict(container.get()) except StopIteration: yield build_feed_dict(container.get()) def input_fn(): return tf.data.Dataset.from_generator( gen, output_types={iname: tf.int32 for iname in INPUT_NAMES}, output_shapes={iname: (None, None) for iname in INPUT_NAMES}) return input_fn class DataContainer: def __init__(self): self._texts = None def set(self, texts): if type(texts) is str: texts = [texts] self._texts = texts def get(self): return self._textsmodel_fn包含模型的规范。在例子中,它是从上一步中保存的pbtxt文件加载的。功能通过input_map显式映射到相应的输入节点。
def model_fn(features, mode): with tf.gfile.GFile(GRAPH_PATH, 'rb') as f: graph_def = tf.GraphDef() graph_def.ParseFromString(f.read()) output = tf.import_graph_def(graph_def, input_map={k + ':0': features[k] for k in INPUT_NAMES}, return_elements=['final_encodes:0']) return EstimatorSpec(mode=mode, predictions={'output': output[0]}) estimator = Estimator(model_fn=model_fn)现在几乎拥有了进行推理所需的一切。开工吧!
def batch(iterable, n=1): l = len(iterable) for ndx in range(0, l, n): yield iterable[ndx:min(ndx + n, l)] def build_vectorizer(_estimator, _input_fn_builder, batch_size=128): container = DataContainer() predict_fn = _estimator.predict(_input_fn_builder(container), yield_single_examples=False) def vectorize(text, verbose=False): x = [] bar = Progbar(len(text)) for text_batch in batch(text, batch_size): container.set(text_batch) x.append(next(predict_fn)['output']) if verbose: bar.add(len(text_batch)) r = np.vstack(x) return r return vectorize可以在存储库中找到上述功能提取器的独立版本。
https://github.com/gaphex/bert_experimental
>>> bert_vectorizer = build_vectorizer(estimator,build_input_fn)>>> bert_vectorizer(64 * ['sample text'])。shape (64,768 )第4步:使用Projector探索向量空间
现在是时候进行演示了!
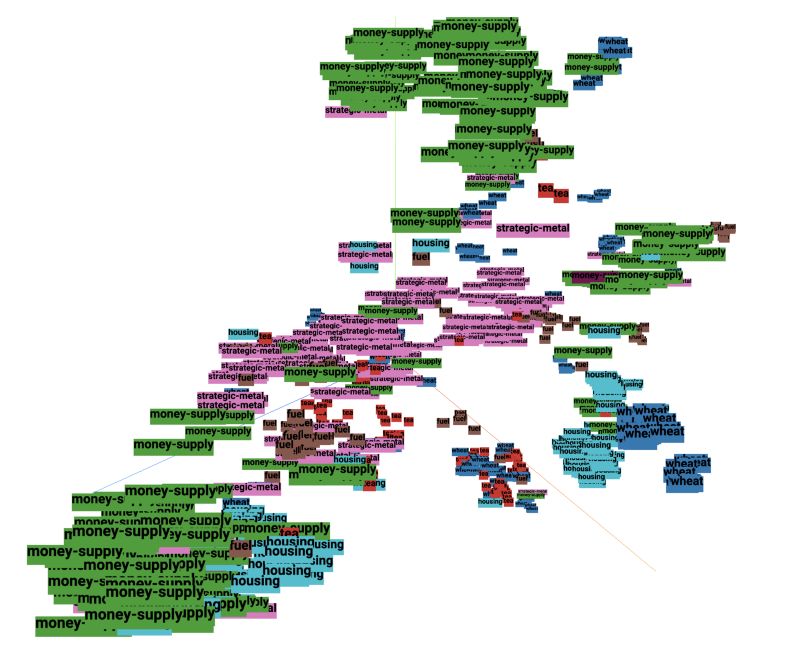
使用矢量化器,将为Reuters-21578基准语料库中的文章生成嵌入。
为了在3D中可视化和探索嵌入向量空间,将使用称为T-SNE的降维技术。
先来看一下嵌入文章吧。
from nltk.corpus import reuters nltk.download("reuters")nltk.download("punkt") max_samples = 256categories = ['wheat', 'tea', 'strategic-metal', 'housing', 'money-supply', 'fuel'] S, X, Y = [], [], [] for category in categories: print(category) sents = reuters.sents(categories=category) sents = [' '.join(sent) for sent in sents][:max_samples] X.append(bert_vectorizer(sents, verbose=True)) Y += [category] * len(sents) S += sents X = np.vstack(X) X.shape嵌入式投影仪可以使用生成的嵌入的交互式可视化。
可以自己运行T-SNE或使用右下角的书签加载检查点(加载仅适用于Chrome)。
第5步:构建搜索引擎
现在,假设拥有50k文本样本的知识库,需要快速回答基于此数据的查询。如何从文本数据库中检索与查询最相似的样本?答案是最近邻搜索。
在形式上,将解决搜索问题定义如下:
给定一组点的小号在向量空间中号,并查询点Q ∈ 中号,发现在最近点小号到Q。有多种方法可以在向量空间中定义“最接近”,将使用欧几里德距离。
因此要为文本构建搜索引擎,将遵循以下步骤:
矢量化来自知识库的所有样本 - 得到S
向量化查询 - 给出Q.
计算Q和S之间的欧氏距离D.
按升序排序D - 提供最相似样本的索引
从知识库中检索所述样本的标签
为了简单地实现这一点将在纯TensorFlow中实现。
首先,为Q和S创建占位符
dim = 1024graph = tf.Graph()sess = tf.InteractiveSession(graph=graph) Q = tf.placeholder("float", [dim])S = tf.placeholder("float", [None, dim])定义欧氏距离计算
squared_distance = tf.reduce_sum(tf.pow(Q - S, 2), reduction_indices=1)distance = tf.sqrt(squared_distance)最后,获得最相似的样本索引
top_k = 3 top_neg_dists, top_indices = tf.math.top_k(tf.negative(distance), k=top_k)top_dists = tf.negative(top_neg_dists)第6步:用数学加速搜索
现在已经设置了基本的检索算法,问题是:
可以让它运行得更快吗?通过一点点数学可以的。
对于一对向量p和q,欧氏距离定义如下:
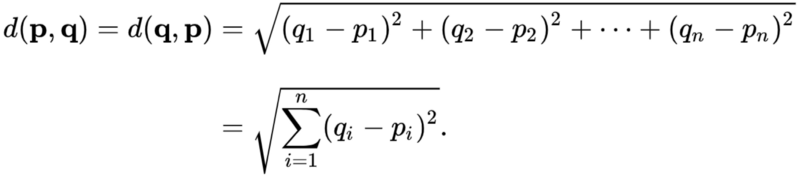
这正是在第4步中计算它的方式。
但是,由于p和q是向量,可以扩展并重写它:
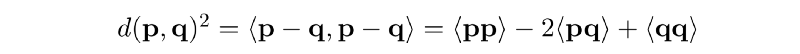
其中⟨...⟩表示内在产品。
在TensorFlow中,这可以写成如下:
Q = tf.placeholder("float", [dim])S = tf.placeholder("float", [None, dim]) Qr = tf.reshape(Q, (1, -1)) PP = tf.keras.backend.batch_dot(S, S, axes=1)QQ = tf.matmul(Qr, tf.transpose(Qr))PQ = tf.matmul(S, tf.transpose(Qr)) distance = PP - 2 * PQ + QQdistance = tf.sqrt(tf.reshape(distance, (-1,))) top_neg_dists, top_indices = tf.math.top_k(tf.negative(distance), k=top_k)由于矩阵乘法运算是高度优化的,因此该实现的工作速度比前一个略快。
顺便说一下,在上面的公式中,PP和QQ实际上是各个向量的L2范数的平方。如果两个向量都是L2归一化的,则PP = QQ = 1.这给出了内积与欧氏距离之间的有趣关系:
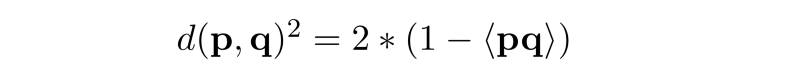
然而,进行L2归一化会丢弃关于矢量幅度的信息,这在很多情况下是不合需要的。
相反,可能会注意到,只要知识库没有改变,PP,其平方向量范数也保持不变。因此,不是每次重新计算它,而是使用预先计算的结果,进一步加速距离计算。
现在把它们放在一起。
class L2Retriever: def __init__(self, dim, top_k=3, use_norm=False, use_gpu=True): self.dim = dim self.top_k = top_k self.use_norm = use_norm config = tf.ConfigProto( device_count={'GPU': (1 if use_gpu else 0)} ) config.gpu_options.allow_growth = True self.session = tf.Session(config=config) self.norm = None self.query = tf.placeholder("float", [self.dim]) self.kbase = tf.placeholder("float", [None, self.dim]) self.build_graph() def build_graph(self): if self.use_norm: self.norm = tf.placeholder("float", [None, 1]) distance = dot_l2_distances(self.kbase, self.query, self.norm) top_neg_dists, top_indices = tf.math.top_k(tf.negative(distance), k=self.top_k) top_dists = tf.negative(top_neg_dists) self.top_distances = top_dists self.top_indices = top_indices def predict(self, kbase, query, norm=None): query = np.squeeze(query) feed_dict = {self.query: query, self.kbase: kbase} if self.use_norm: feed_dict[self.norm] = norm I, D = self.session.run([self.top_indices, self.top_distances], feed_dict=feed_dict) return I, D def dot_l2_distances(kbase, query, norm=None): query = tf.reshape(query, (1, -1)) if norm is None: XX = tf.keras.backend.batch_dot(kbase, kbase, axes=1) else: XX = norm YY = tf.matmul(query, tf.transpose(query)) XY = tf.matmul(kbase, tf.transpose(query)) distance = XX - 2 * XY + YY distance = tf.sqrt(tf.reshape(distance, (-1,))) return distance示例:电影推荐系统
对于此示例,将使用IMDB中的电影摘要数据集。使用NLU和Retriever模块,将构建一个电影推荐系统,用于建议具有类似绘图功能的电影。
首先,下载并准备IMDB数据集。
http://www.cs.cmu.edu/~ark/personas/
import pandas as pdimport json !wget http://www.cs.cmu.edu/~ark/personas/data/MovieSummaries.tar.gz!tar -xvzf MovieSummaries.tar.gz plots_df = pd.read_csv('MovieSummaries/plot_summaries.txt', sep='\t', header=None)meta_df = pd.read_csv('MovieSummaries/movie.metadata.tsv', sep='\t', header=None) plot = {}metadata = {}movie_data = {} for movie_id, movie_plot in plots_df.values: plot[movie_id] = movie_plot for movie_id, movie_name, movie_genre in meta_df[[0,2,8]].values: genre = list(json.loads(movie_genre).values()) if len(genre): metadata[movie_id] = {"name": movie_name, "genre": genre} for movie_id in set(plot.keys())&set(metadata.keys()): movie_data[metadata[movie_id]['name']] = {"genre": metadata[movie_id]['genre'], "plot": plot[movie_id]} X, Y, names = [], [], [] for movie_name, movie_meta in movie_data.items(): X.append(movie_meta['plot']) Y.append(movie_meta['genre']) names.append(movie_name)使用BERT NLU模块矢量化电影情节:
X_vect = bert_vectorizer(X, verbose=True)最后,使用L2Retriever,找到与查询电影最相似的绘图向量的电影,并将其返回给用户。
def buildMovieRecommender(movie_names, vectorized_plots, top_k=10): retriever = L2Retriever(vectorized_plots.shape[1], use_norm=True, top_k=top_k, use_gpu=False) vectorized_norm = np.sum(vectorized_plots**2, axis=1).reshape((-1,1)) def recommend(query): try: idx = retriever.predict(vectorized_plots, vectorized_plots[movie_names.index(query)], vectorized_norm)[0][1:] for i in idx: print(names[i]) except ValueError: print("{} not found in movie db. Suggestions:") for i, name in enumerate(movie_names): if query.lower() in name.lower(): print(i, name) return recommend来看看!
>>> recommend = buildMovieRecommender(names, X_vect)>>> recommend("The Matrix")Impostor Immortel Saturn 3 Terminator Salvation The Terminator Logan's Run Genesis II Tron: Legacy Blade Runner即使没有监督,该模型也可以在几个分类和检索任务中充分执行。虽然使用监督数据可以进一步提高性能,但所描述的文本特征提取方法为下游NLP解决方案提供了坚实的基线。
以上是使用BERT和TensorFlow构建搜索引擎的指南。
推荐阅读
哈工大讯飞联合实验室发布基于全词覆盖的中文BERT预训练模型















 4738
4738











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









