






 本文通过TensorFlow强化学习算法示例,详细解释PPO如何解决连续动作问题,涉及N步更新、重要性采样及网络更新。以Pendulum-v0环境为例,探讨PPO算法在连续控制问题中的应用,同时讲解了 kl散度在限制策略分布变化中的作用。
本文通过TensorFlow强化学习算法示例,详细解释PPO如何解决连续动作问题,涉及N步更新、重要性采样及网络更新。以Pendulum-v0环境为例,探讨PPO算法在连续控制问题中的应用,同时讲解了 kl散度在限制策略分布变化中的作用。

在上一篇文章中,我们已经说了PPO三个重点:
- 用网络求解连续动作型问题;
- 进行N步更新;
- 重要性采样及PPO网络的更新学习。
本篇将会解释的示例代码,同样会以这三个为重点。
如果对原理有所疑问,可以翻看上一篇专栏:
张斯俊:如何直观理解PPO算法?[理论篇]zhuanlan.zhihu.com
这一篇,我们以tensorflow给出的强化学习算法示例代码为例子,看看PPO应该如何实现。
https://github.com/tensorlayer/tensorlayer/blob/master/examples/reinforcement_learning/tutorial_PPO.pygithub.com如果一时间看代码有困难,可以看我的带注释版本。希望能帮助到你。
https://github.com/louisnino/RLcode/blob/master/tutorial_PPO.pygithub.comPendulum-v0 说明
在开始解释算法前,先对这次我们要征服的游戏做一个简单的说明。
Pendulum-v0是一个简单的环境,如图。
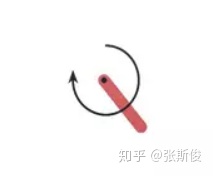
图中的杆围绕A点转动,我们的任务是,让智能体学会给杆子施加一定的“力”,让杆子立起来。
这里的“力”用了带箭头的圆环表示,圆环越大,表示用的“力”越大。
这里的“力”之所以用双引号括起来,是这个游戏并不完全遵从我们现实世界的物理规则。它只是一个游戏而已。
正如我们之前说到,这个“力”并不是开关,是有大小之别;因此,这是一个连续型控制的问题。
我们主要关心还是三要素,state,action,reward
我们输入的state特征有三个
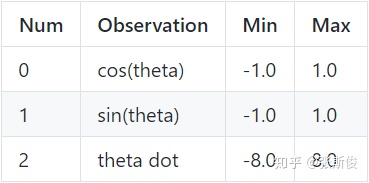
输入的action是[-2.0,2.0]范围内的数值
奖励的计算: -(theta^2 + 0.1 theta_dt^2 + 0.001 action^2)
由此,我们可以知道,reward的最小值是-16.273 最大值是0。获得最大值时,就是杆子正正树立的时候。我们的任务就调整输入的“力”的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 336
336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









