





我们学过的最经典的估计线性模型的系数的方法,叫做“最小二乘法”。除了“最小二乘法”,其实还有其他方法可以用于模型系数的拟合,这些方法是对于简单线性模型的改进。这一章主要讨论的有三类重要的方法:
- 子集选择(最优子集选择、逐步模型选择):假设我们原来的模型一共有
个变量,那么我将从这
个变量中选出与响应变量相关的
个变量形成子集,再对这
个变量使用最小二乘法。子集选择的重点在于如何选出“相关”的这
个变量。
- 压缩估计(岭回归、LASSO):这个方法通过将估计系数往0的方向进行压缩,也就是你可以看到某些
近乎为0,从而达到变量选择的目的。
- 降维(主成分回归、偏最小二乘) : 这个方法将p维预测变量投影至
维子空间中,
。这个通常通过计算这
个变量的
线性组合或者投影来实现。种不同的
子集选择
最优子集选择
为了选择最优子集,我们对
模型筛选的步骤如下:

第二步中的a是将一共
为了选择一个最好的模型,我们必须从这
逐步筛选
逐步筛选可以分为向前逐步筛选、向后逐步筛选、以及交叉方法。
1.向前逐步筛选
筛选的过程从0个解释变量开始,然后逐一向模型中添加解释变量。每一次,都选择加入能够给予模型最大提升度的变量。但是向前逐步筛选并不能保证能够找到最好的模型,因为如果仅含一个变量时最好的模型是

2.向后逐步筛选
筛选的过程从

向后逐步筛选需要保证样本量
3.交叉方法
这是以上两种方法的结合,相当于向前逐步筛选的过程中,每加入一个变量,就有一个对模型提升没有用处的变量被剔除。
选择最优模型
这里我们针对的是以上给出的算法中的第三步的选择规则。
一般来说,包含所有解释变量的模型总是有最小的
为了估计测试误差,我们有两种常用的方法:
- 通过修正过拟合的偏误利用训练误差间接估计
- 利用交叉验证或其他方法进行直接估计
下边会罗列关于第一种方法常用的规则。
之前我们有介绍过,训练集的
在这个式子中,
AIC是为一大类利用极大似然估计的模型而生的。对于最小二乘模型,
BIC则来源于贝叶斯的观点,但它长得与
通过对
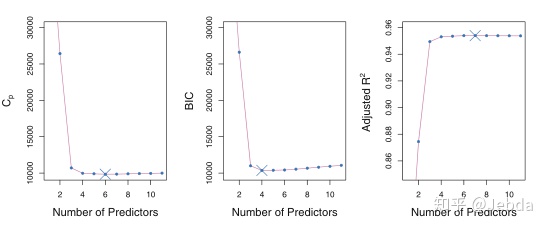
压缩方法
关于岭回归与LASSO方法的原理我们已经在之前介绍过了,这里就不再叙述了。
https://zhuanlan.zhihu.com/p/166065526zhuanlan.zhihu.com
岭回归和Lasso的贝叶斯解释
从贝叶斯角度去看岭回归和Lasso回归,对于回归,贝叶斯理论假设回归系数向量
形式如下:
这里的比例服从贝叶斯定理,并且上边的等式在
假设普通线性模型为
- 如果
是高斯分布,均值为零,标准差为
, 那么给定数据,
后验形式最可能是岭回归得到的结果。
- 如果
是双指数分布,均值为零,尺度参数为
,那么它的后验形式最可能是lasso的结果。
降维方法
降维是指将估计
假设我们原始预测变量的
可以用最小二乘拟合线性回归模型
通常选择线性组合的方法有两种:
- 主成分回归(PCA与PCR)
- 偏最小二乘(PLS)
PCA
主成分分析是在做这样一件事情:首先寻找所有原始变量的线性组合中方差最大的作为第一主成分,然后寻找所有与第一主成分无关的原始变量的线性组合中方差最大的作为第二主成分,以此类推。
主成分分析只是在寻找主成分。
主成份分析的目的是用尽量少的主成份代表众多的变量,因此它们所包含的信息量不应该损失太多。数据的方差大小代表了所包含的信息量,主成份的方差等于相关矩阵的特征值,而特征值的加和等于变量的个数
具体的推导细节我们已经在多元回归分析中学过了,这里不再叙述。
PCR
有了主成分,我们就可以利用构造的前
在主成分回归里,主成分数量
需要注意的是,在应用主成分回归时,通常建议在构造主成分之前,先对某一个变量进行标准化处理,从而保证所有变量在相同尺度上。如果不做标准化,方差较大的变量将在主成分中占主导地位,变量的尺度将最终影响主成分回归模型。
PLS
偏最小二乘也是将原始变量的
一般来说,能用主成分分析就能用偏最小二乘。偏最小二乘集成了主成分分析、典型相关分析、线性回归分析的优点。
偏最小二乘的大致思路如下:
假设有个因变量
和
个自变量
。为了研究因变量和自变量的统计关系,我们观测了
个样本点,由此构成了
对因变量与自变量,我们将因变量的矩阵记为
,自变量的矩阵记为
。偏最小二乘回归分别从
与
中提取出成分
与
,
为
的线性组合,
为
的线性组合。但这里要求:
-
与
应当尽可能大地携带他们各自数据表中的变异信息
-
与
的相关程度能够达到最大
在成分与
被提取后,偏最小二乘回归分别实施
对
的回归以及
对
的回归。如果回归方程已经达到了令人满意的精度,那么算法终止;否则将利用
被
解释后的残余信息以及
被
解释后的残余信息进行第二轮的成分提取。如此往复,直到达到一个令人满意的精度。
最后,如果对一共提取了
个成分
,偏最小二乘回归将通过实施
对
的回归,再将
表达成
的回归方程。

















 3280
3280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









