





二、merge:通过键拼接列
类似于关系型数据库的连接方式,可以根据一个或多个键将不同的DatFrame连接起来。
该函数的典型应用场景是,针对同一个主键存在两张不同字段的表,根据主键整合到一张表里面。
merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False)
参数介绍:
left和right:两个不同的DataFrame;
how:连接方式,有inner、left、right、outer,默认为inner;
on:指的是用于连接的列索引名称,必须存在于左右两个DataFrame中,如果没有指定且其他参数也没有指定,则以两个DataFrame列名交集作为连接键;
left_on:左侧DataFrame中用于连接键的列名,这个参数左右列名不同但代表的含义相同时非常的有用;
right_on:右侧DataFrame中用于连接键的列名;
left_index:使用左侧DataFrame中的行索引作为连接键;
right_index:使用右侧DataFrame中的行索引作为连接键;
sort:默认为True,将合并的数据进行排序,设置为False可以提高性能;
suffixes:字符串值组成的元组,用于指定当左右DataFrame存在相同列名时在列名后面附加的后缀名称,默认为('_x', '_y');
copy:默认为True,总是将数据复制到数据结构中,设置为False可以提高性能;
indicator:显示合并数据中数据的来源情况
案例1
importpandas as pdimportnumpy as np
random= np.random.RandomState(0) #随机数种子,相同种子下每次运行生成的随机数相同
df1=pd.DataFrame(random.randn(3,4),columns=['a','b','c','d'])
df1

random =np.random.RandomState(0)
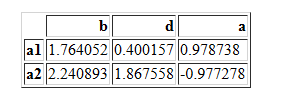
df2=pd.DataFrame(random.randn(2,3),columns=['b','d','a'],index=["a1","a2"])
df2
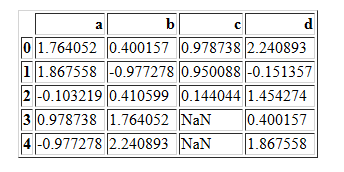
pd.merge(df1,df2)

pd.merge(df1,df2,how="outer")
案例2 默认按相同的列名键join
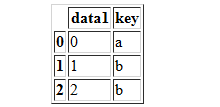
df3=pd.DataFrame({'key':['a','b','b'],'data1':range(3)})
df3
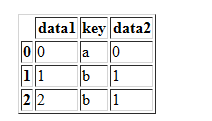
df4=pd.DataFrame({'key':['a','b','c'],'data2':range(3)})
df4

pd.merge(df3,df4)
案例三
df1 = pd.DataFrame({'lkey': ['foo', 'bar', 'baz', 'foo'],'value': [1, 2, 3, 5]})
df1

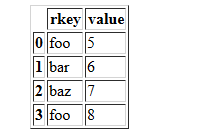
df2 = pd.DataFrame({'rkey': ['foo', 'bar', 'baz', 'foo'],'value': [5, 6, 7, 8]})
df2
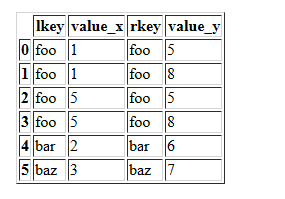
df1.merge(df2)

Merge df1 and df2 on the lkey and rkey columns. The value columns have the default suffixes, _x and _y,
df1.merge(df2,left_on="lkey",right_on="rkey")
>>> df1.merge(df2, left_on='lkey', right_on='rkey', suffixes=(False, False))
Traceback (most recent call last):
...
ValueError: columns overlap but no suffix specified:
Index(['value'], dtype='object')















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









