






K-means是一种无监督学习,对未标记的数据(即没有定义类别或组的数据)进行分类。 该算法的目标是在数据中找到由变量K标记的组。该算法迭代地工作基于所提供的特征,将每个数据点分配给K个组中的一个。 基于特征相似性对数据点进行聚类。 K均值聚类算法的结果是:
1.K簇的质心,可用于标记新数据
2.训练数据的标签(每个数据点分配给一个集群)
一、k-means简述
1、聚类
“类”指的是具有相似性的集合,聚类是指将数据集划分为若干类,使得各个类之内的数据最为相似,而各个类之间的数据相似度差别尽可能的大。对数据集进行聚类划分,属于无监督学习。聚类分析就是以相似性为基础,在一个聚类中的模式之间比不在同一个聚类中的模式之间具有更多的相似性。
2、K-Means
对样本集D = {x1,x2,…,xm}.K-Means算法就是针对聚类划分C = {C1,C2,…,Ck}最小化平方误差;
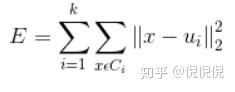
其中
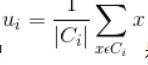
是是簇Ci的均值向量。从上述公
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4411
4411











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









