





如今,在人工智能和机器学习风潮的影响之下,Python语言的受欢迎程度急速攀升,很多人都表达出想要学习python的愿望,来丰富自己的职业技能,而由于各种各样的原因,很大一部分人中途放弃,我也是从这个阶段过来的。那么我们应该怎样学习一门新技能而不至于「从入门到放弃」呢?我联想到之前看过的一句话「Start With Why」,这句话来自于西蒙.斯涅克,他是一名作家,同时也是一家营销顾问公司的创始人。

这本书讲了一个黄金法则:做事之前首先想为什么(why),其次想如何做(how),最后再想做什么(what),我们学习爬虫也是一样,首先要想我能用爬虫做什么,其次再想怎么做,简单点说就是:带着问题去学习。

最近我的一个教师朋友找打我,说想要学习爬虫,原因是最近各个地区刚刚考完二模,他想把网上的卷子爬下来,给他的学生们练习。你看,他的目的很明确,就是爬卷子。于是,我花了一天的时间教会了他,他花了两天的时间完成了这个项目,下面我们一起看一下,虽然还有很多需要完善的地方,但基本已经解决了问题。
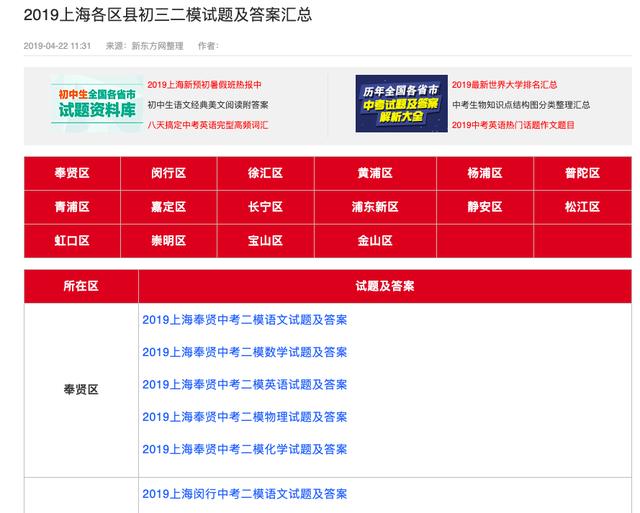
这个网站是新东方的网站,里面很清晰的整理了每一年各个地区的二模试卷,首先数据源就有了。接着我们来想怎么爬(what),我们首先要把每个区所有试题的链接拿下来,每一个链接点进去是这样的:
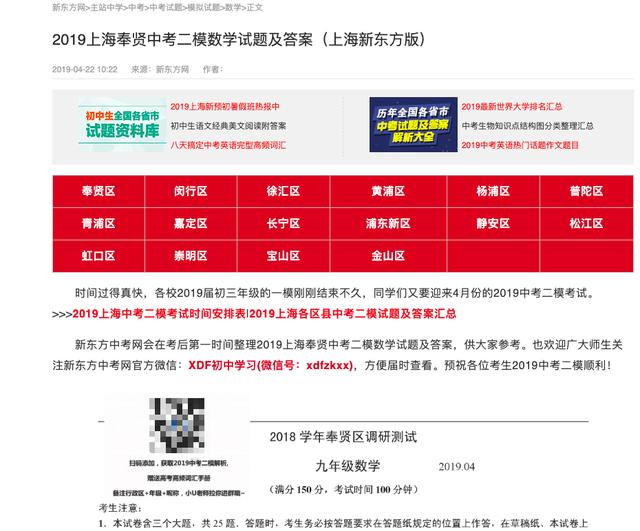
试卷的正文页面包含了试卷标题和正文,正文是由图片组成的,那么我们还需要把每一个试卷的所有图片拿出来,最终组合成一张完整的试卷
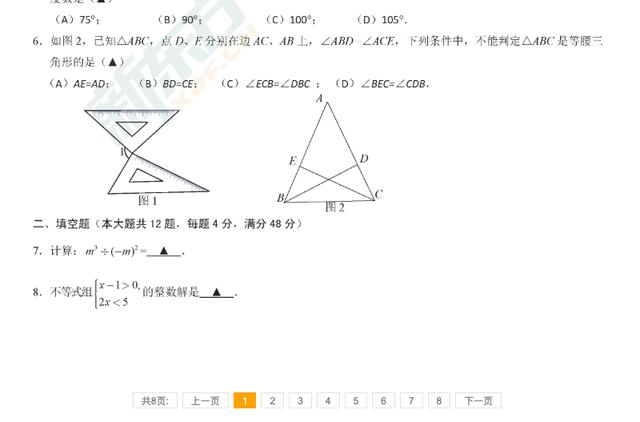
最终一个例子的结果是下面这样的,我们要做的就是把各个地区的各个科目都按照这样的方式整理出来。听说我的那位朋友不仅仅把自己所教的数学试卷全部拿了下来,还把其他各个学科的试卷都拿了下来,现在在学校里面很受其他老师欢迎呢。

下面我们就一步步来实现这个小项目。
这个项目很简单,只需要用到3个基本的Python库就能完成:
import requestsimport osfrom lxml import etree第一步需要拿出所有试卷的链接,并且最终返回一个url的列表(list):
def get_paper_url(): url = 'http://zhongkao.xdf.cn/201904/10891103.html' r = requests.get(url=url) r.encoding = 'utf-8' html = etree.HTML(r.text) url_contend = html.xpath('//div[@class="air_con f-f0"]/table/tbody/tr/td/p/a/@href') return url_contend第二步,获得每一张试卷的名称和所有的图片链接:
def get_image_url(): url_list = [] url = 'http://zhongkao.xdf.cn/201904/10891174.html' url_list.append(url) r = requests.get(url=url) r.encoding = 'utf-8' html = etree.HTML(r.text) title = html.xpath('//p[@class="title1 f-f0"]/text()')[0] print(url) main_url = url.replace('.html', '') # 计算总共有多少页面 uls = html.xpath('//div[@class="ch_conpage hdd"]/ul/li') page_num = len(uls) - 5 for page in range(page_num-1): page_url = main_url + '_' + str(page+2) + '.html' url_list.append(page_url) return title, url_list第三步,根据之前获得的图片链接,下载这些图片:
def get_image(): title, url_list = get_image_url() img_num = 1 for url in url_list: r = requests.get(url=url) r.encoding = 'utf-8' html = etree.HTML(r.text) img_url = html.xpath('//div[@class="air_con f-f0"]//img/@src')[0] save_img(img_url, title, img_num) img_num += 1 print('hahah')第四步,把下载的图片,按照不同的试卷类型,分类保存到文件夹下:
def save_img(img_url, file_name, img_num): img_response = requests.get(url=img_url) now_path = os.getcwd() img_path = os.path.join(now_path, 'tupian') if not os.path.exists(img_path): os.makedirs(img_path) img_path = os.path.join(img_path, file_name) if not os.path.exists(img_path): os.makedirs(img_path) path = img_path + '/' + str(img_num) + '.jpg' with open(path, "wb") as f: # 保存的文件名 保存的方式(wb 二进制 w 字符串) f.write(img_response.content) print('ok')你看,短短的四部分,50行简短的代码就能获取到几乎所有的试卷,对于一个老师来说,这项技能所节省的时间超乎想象,你可以试想一下,以后他的学生几乎再也不需要买试卷,这种人无论在哪里,领导怎么会不喜欢呢?希望大家也能结合自己的工作场景,真正把学到的内容用起来。

之后我会陆续给大家介绍爬虫在各行各业中的应用,并且带领大家一起学习,敬请期待。















 1262
1262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









