





Jupyter笔记本是数据科学项目中最常用的工具之一。 这是使用python开发软件的绝佳工具,并为此提供了强大的支持。 它也可以与spylon内核一起用于scala开发。 这是一个额外的内核,必须单独安装。
第一步:安装软件包
pip install spylon-kernel
第二步:创建内核规范
这将使我们能够在笔记本中选择scala内核。
python -m spylon_kernel install
第三步:启动Jupyter Notebook
ipython notebook
然后在笔记本中,选择New-> spylon-kernel。 这将启动我们的scala内核。
步骤4:测试笔记本
让我们写一些scala代码:
val x = 2val y = 3x+y

输出结果应与左图中的结果相似。 如您所见,它还会启动火花组件。 为此,请确保已设置SPARK_HOME。
现在我们甚至可以使用spark。 让我们通过创建数据集进行测试:
val data = Seq((1,2,3), (4,5,6), (6,7,8), (9,19,10))val ds = spark.createDataset(data)ds.show()这应该输出一个简单的数据框:
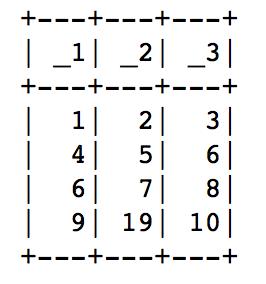
我们甚至可以使用%python命令在此内核中使用python:
%%pythonx=2print(x)有关更多信息,您可以访问spylon-kernel github页面。 具有上述代码的笔记本可在此处获得。
(本文翻译自Bogdan Cojocar的文章《How to run Scala and Spark in the Jupyter notebook》,参考:https://medium.com/@bogdan.cojocar/how-to-run-scala-and-spark-in-the-jupyter-notebook-328a80090b3b)















 2726
2726











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









