





第1节 第二个halcon程序
2.3.1 第二个halcon程序:字符识别
写这一章的时候距离第一章写完已经有2周之久了。为什么隔了这么久呢,因为我偷懒了,没有坚持下来。。。结果现在激情大不如写第一节的时候,好在我复习了第一节的最后一段话!瞬间满血复活!
话不多说我们言归正传。上一节我们学会了一些简单的图像处理,这一节我们来学习怎么实现对字符的识别!老规矩,先直接上代码(2-3-1-1)和图片(2-3-1-2):

图 2-3-1-1

图 2-3-1-2
图片下载链接:群共享文件。
对的,就是我随便照的一张办公室墙上的贴图。我们的目的是识别上面的"HAPPY NEW YEAR",汉字还不行,因为没有库,需要自己训练。到了这一节的小伙伴应该对halcon的思路有了一定的了解了,我就不粗鲁的直接分析代码了。先说下字符识别的思路吧:首先通过图像处理找到图片中字符区域,然后依次一个字母一个字母的识别,最后输出。(首先...然后...最后...这格式。果然还是小时候学的东西是最牢固的)。
首先当然是读取图片了,然后把3通道图片分成单通道的,这个你都会了的。
read_image (Image, 'F:/work/newbook/字符识别.jpg')
decompose3 (Image, Image1, Image2, Image3)
接下来这一步:
gen_rectangle1 (ROI_0, 560.594, 483.602, 647.781, 688.539):生成一个1型的矩形,1型就是绝对水平的矩形,halcon里面还有2型的就是带角度的。确定一个1型矩形你给一个左上角的点和一个右下角的点就可以了,所以后面的4个参数就是这两个点的横纵坐标。第一参数是图标输出的矩形了,当然这个矩形是一个region(与本算子相关的知识点,详见本节TIPS 1,2)。
直接输入两个点的横纵坐标是方便,但是有的时候也不方便,比如我这个时候,我就不知道该生成多大的矩形。为什么要生成一个矩形?是这样的,我要找到字符的区域,按照常规的我得通过图像的分析处理最后得到那几个英文字母,但是我要介绍功能嘛,所以用了一招自画ROI的方法:
图 2-3-1-3
如上图(2-3-1-3),单击图像窗口上画圆的按钮,弹出下面的矩形框,然后点击"绘制"按钮,里面选择绘制"轴平行矩形",当然工具栏下面的一行各个铅笔下面加圆形矩形的是快捷按钮,直接点击就可以画了。(这里面的按键比较少,个人建议你有空都点开看一看。)
如下图(2-3-1-4)画出一个矩形,刚好覆盖了英文字母,自己可以学着稍微调整一下细节部分。
图 2-3-1-4
reduce_domain (Image3, ROI_0, ImageReduced):这一算子相信大家都已经很熟悉了,毕竟上一节已经用了两次了,这儿再强调下,它输出的是一个目标区域的图像。用了这一招,可以立马去掉旁边所有的干扰,实在是好。如下左图(2-3-1-5)。
图2-3-1-5
图2-3-1-6
binary_threshold(ImageReduced,Region,'max_separability','dark',UsedThreshold):
这个算子的目的跟threshold一样,我们就叫它二值化自动阈值吧。但是没有了threshold里面的阈值参数,这样对图像的亮暗要求就没有那么大了。第一个参数是输入图像,第二个参数是经过阈值处理后得到的区域,为输出。第三个参数是自动阈值的方法,有两种,一种是默认的,应该就是等同于threshold的一种分发,另外一种是对其直方图做平滑处理后再自动阈值。具体的我也没试过第二种,每次都用的第一种。。。所以建议正在入门的各位大佬也不要花时间在这个细节上了。第四个参数是二值化阈值分割后,你要输出暗的那一块,还是亮的那一块啊,总得告诉下halcon嘛,我们这个明显就是暗的部分啦,所以我选的'dark',最后一个参数就是它自动阈值也得有一个值嘛,halcon很自信的把它算出来的自动阈值的值告诉你了。有点狂……你有没有好奇它是怎么算出来的 ?它怎么就知道从哪里分割,哈哈,所以说"学好数理化,走遍天下都不怕"。如果你没有足够的数学知识,你就得自己根据图像来慢慢调整阈值threshold,如果你数学学得好,就可以自己算出这个值。看把我能的!哈哈~当然现在的你也没有必要知道,有兴趣的可以看一下,我写在本节TIPS 3里面。毕竟牛都吹完了,不写出来,怕你们以为我也不知道。
接下来就是去掉一些不是字符的部分,首先,求连通域:
connection (Region, ConnectedRegions):
select_shape (ConnectedRegions, SelectedRegions, 'area', 'and', 150, 99999):第一个算子就不用介绍啦,第二个我得说下:第一节里面用的是select_shape_std()算子,这个里面可以选择最大面积的,但是我们不是每次都只需要找出来最大面积的那个,比如这次,我们要找出来的是两排差不多大小的字符,那就要用到这个功能强大的算子了。这个算子第一个参数是需要筛选的region(大多数情况下都是connection之后的,因为选嘛,大多数情况都是在很多个里面选)。这中间有个小逻辑(详见本节TIPS 4)。回到这个算子,第二个参数就是选出来的region了,第三个参数是你根据什么特征来筛选,本例中是根据面积特征,那么对应的第四、第五个参数就是面积的上下限了,筛选面积在150到99999像素之间的区域。那个'and',是当你有好几个参数特征要选择的时候,是同时满足所有的特征还是只要满足其中之一就可以呢,就要选择一下是'and'还是'or'了,其它时候比如我这时候,只有一个面积特征,那就只需要默认"and"就可以了。(其实这个算子,还可以利用特征直方图来实现,详见本节TIPS 5)效果如下左图(2-3-1-7和2-3-1-8):
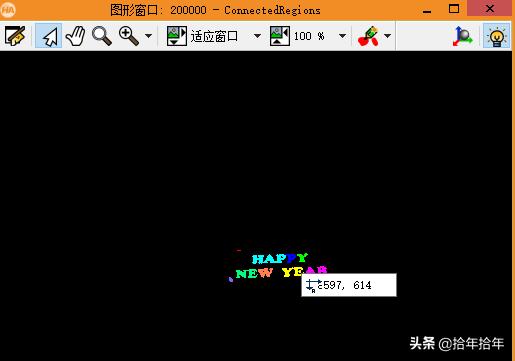
图 2-3-1-7
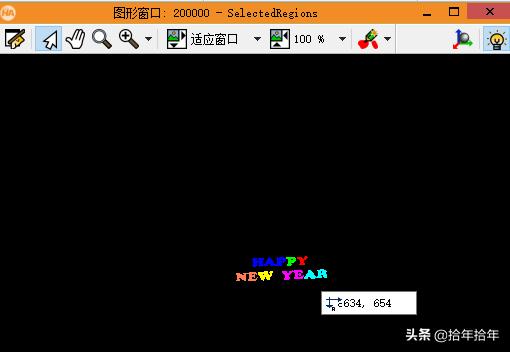
图2-3-1-8
根据上右图可以看到(2-3-1-8),我们已经筛选出来"happy new year"了,而且去掉了旁边的干扰的小区域。但是聪明的你同时肯定也发现了,"hap"、"ne"、"ye"、"ar"都被连在了一起,当成了一个区域,这就是项目上常遇到的情况。要是刚好都一个一个的那就简单了,谁都可以做视觉了。但是这样其实也不难,我这儿有一招对字符的分割常用的招式,其实有两招了,另一招以后再说,这儿用的是第一招:首先:
union1 (SelectedRegions, RegionUnion):懂英文的或者会查英汉字典的都知道这个算子的意思是联合,就是把很多个region合并成一个region,它跟connection可以算是一组逆运算了(既然有union1,那肯定就有union2了,union1和union2的区别是什么呢?详见本节 TIPS 6)。如下左图(2-3-1-9)。
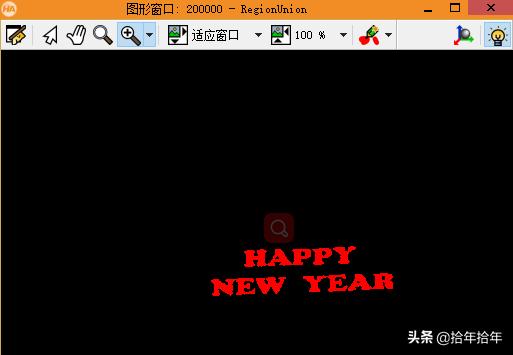
图 2-3-1-9
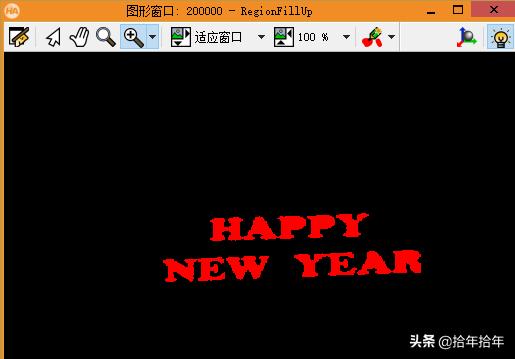
图2-3-1-10
接下来是填充:
fill_up (RegionUnion, RegionFillUp):这个算子没什么多说的了,见上右图(2-3-1-10),孔洞已经被填充了。
填充之后,再做开运算:
opening_rectangle1 (RegionFillUp, RegionOpening, 1, 3):这个算子意思为以1型矩形作为结构元素进行开运算。后面两个数字为矩形结构元素宽和高。可以这么说,任何图像处理软件都避免不了这两组算法:开闭运算和膨胀腐蚀运算。因为都有,所以这个理论我就不讲了,但是你必须要懂!你可以去百度下,有很详细的、很通俗易懂的解释。我若讲也是照着百度的来讲,还得重开一节,太有凑字数的嫌疑了。本人不屑于那么做,我都是堂堂正正的废话来凑字数!那么你先去百度下什么叫开闭运算,什么叫膨胀腐蚀吧^_^。(关于开闭运算的一些算子,详见本节TIPS 7)。
好,假设现在你已经知道了,我们继续讲解。像我们这种情况,用开运算,目的很明显:就是把粘连在一起的字符分开,方便接下来的字符识别。字符都是水平相连,而垂直方向没有相连的,所以,结构元我设计成公式中的参数,宽比高小,你们也可以试着调一下其它参数,感受下,别偷懒,感受下!听话~
你多试几下不同参数,就能理解为什么我要先fill_up再开运算了。因为英文字符常有孔洞,填充后再开运算效果会比较好。如下左图(2-3-1-11)。然后咱们再这些字符恢复原状,把填充的 孔洞重新露出来,怎么做呢?
图 2-3-1-11
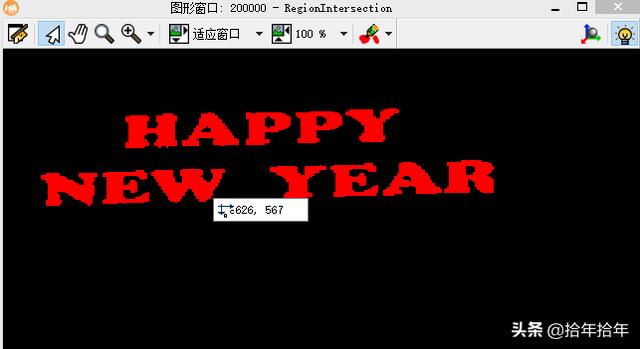
图2-3-1-12
intersection (RegionOpening, RegionUnion, RegionIntersection):说实话,学halcon以来我学了不少单词,比如这个intersection:交集。那就很简单了,求交集,三个参数的意思就是A∩B=C,看单词也差不多知道。本例中就是把开运算过后的RegionOpening和没有开运算,但是也没有填充过的RegionUnion求交集,就可以得到想要的既不粘连,又没有孔洞的RegionInersection了!如上右图(2-3-1-12)。然后再求个连通域就可以得到一个一个分开的字符了(其实分开字符可以有很多种方法,详见本节TIPS 8)。也就是:
connection (RegionIntersection, ConnectedRegions1):如下左图(2-3-1-13):
图 2-3-1-13
图2-3-1-14
到这一节,connection算子之后,可以说众所周知,我们获得了一个region的集合ConnectedRegions1,里面有每个字母的region。但是顺序呢?这些字母的顺序是怎样的呢?本例中是从左到右的两排,还算规整,要是region是无序乱排列的呢?它们在集合ConnectedRegions1里面的顺序是什么呢?这就用到下面这个算子了:
sort_region (ConnectedRegions1, SortedRegions, 'character', 'true', 'row'):这是个知识点了,它的功能是给一堆region排序。第一个参数是扔进来要排序的一堆region,第二个是输出的排好序的region,第三个参数是排序的规则,按F1可以看到,有按照左上角的点来排序,有按照右下角的点等等。对于字符,一般都是我上面用到的方法'character',排序一定是从小到大吗?不一定哦,除非你的第四个参数选择的是'true',这个参数的意思是是否为升序排列,如果是'false',就是降序排列啦。单词是水平的最后一个参数就是'row',反之则'column'。
(排完序之后,该怎么检查是否是按照自己的意愿排序的呢?详见本节TIPS 9)。字符分开了,也排好序了。一般预处理也就到此为止了。可以进行字符的识别了。字符识别的灵魂代码主要是下面两行:
read_ocr_class_mlp ('Document_0-9A-Z_NoRej.omc', OCRHandle):从文件中读取一个OCR分类器;
do_ocr_multi_class_mlp (SortedRegions, ImageReduced, OCRHandle, Class, Confidence):用OCR分类器对多个字符进行分类。
字符的识别其实很简单,也就上面的两步,我就放一起讲了。就像警察抓到嫌疑人,要识别下他是不是在逃的罪犯,首先,警察得有一本在逃罪犯的资料手测,有相片、身高、体重等资料。我们要识别这个字符是什么,也得有一本这样的资料。这本资料halcon为你准备好了。当然它只准备了A到Z,0到9这36个。所以用这本资料就可以识别字符和数字了。拿到这本资料的算子就是上面的第一个read_ocr_class_mlp(),你选中这个算子,按F1后,就能在下面的参数栏里面找到这本资料,对的,它有很多本,你看着选。。。(见下图2-3-1-15)然后halcon需要把资料存到句柄OCRHandle里面。这样我们就可以进行第二步识别了,也就是第二的算子。第一个参数放的你要识别的字符region,第二个是这些region属于哪张图片(这个得是单通道的),第三个参数就是存资料的句柄了。有了这三个就可以读出来了,读完后那些字符以数组的形式保存在Class里面,同时它还反馈给你一个自信度数组Confidence,向你反馈它对自己识别的每个字符的自信程度。也算是给你一个自动筛选的参数,这儿我们用不着,其它情况下可能用得着。大多数情况下都得0.95以上才能算是准的吧。
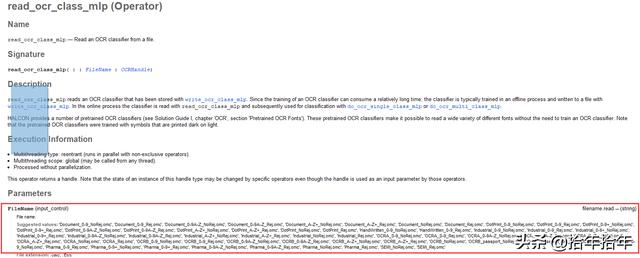
图 2-3-1-15
这两步执行完,人生也成功了一大半了。额不,这个程序也完成了一大半了。。。咳咳。。。接下来就是显示了。在哪显示?怎么显示?这两个既是问题也是思路。首先是显示的位置,我们就近原则就在这几个字符的上方,一个一个按照照片中字符的相对位置显示。
area_center (SortedRegions, Area, Row, Column):获得区域的面积和中心坐标。所以通过这个算子先获得照片中每个字符的位置,这一步简单,你都会了的(这句是我同事的口头禅)。
接下来我们利用一个for循环,逐个输出字母:
for i:=0 to |Area|-1 by 1
disp_message (200000, Class[i], 'image', Row[i]-150, Column[i], 'black', 'true')
endfor
i从0开始,到数组Area的个数-1为止。每次循环i+1。循环执行的disp_message就是显示消息的意思了。里面第一个参数是在哪个窗口显示,第二个参数是要显示的内容,第三个参数就是两个坐标你是要按照图像的坐标系来,还是按照窗口的坐标系来,第四个,第五个参数就是你要显示的位置的横纵坐标了。毕竟一个800 X 600的窗口是可以显示一张1024 X 800的图片的,那坐标肯定是有一定缩放的对吧?我这里用的就是按照图像的坐标来。第六个参数就是字体的颜色了,第七个参数是字符要不要后面加个背景颜色,true就是加,我是这么理解的,其实也差不多就是这个意思。这个算子虽然简单,参数还挺多,不过好在都是一些简单的参数。那我上面一个for循环的意思就是在每个图像字符中心位置的上方150个像素处依次显示我识别出来的字符。虽然说了这么多话,但是"言语从来没能将我的情意表达千万分之一",还是看图吧(2-3-1-16)!
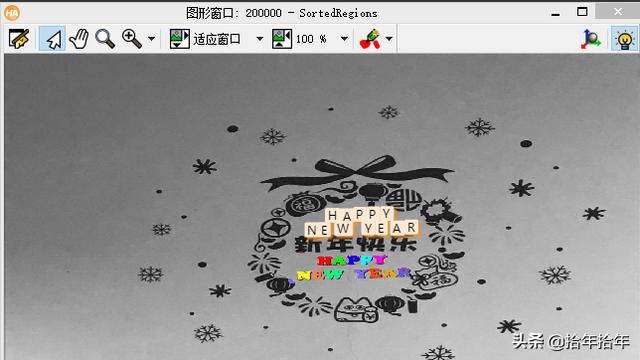
图 2-3-1-16
这就是简单的字符识别了。每个字符按照相对位置依次排列,后面的浅色背景就是我上面第七个参数选择了'true'的结果,你可以试试改'false'再看看效果。
按照惯例:我们再回忆下总体的思路吧!先是拍一张含有字符的图片,(还是提醒下吧,尽量正对着拍,不要倾斜太多角度,那样你得旋转到正面才行,但是我又没教你怎么旋转。。。)第二步,形态学图像处理,找到字符的区域,并分割好它们,确保一个字符一个region;第三步排好顺序,找到资料本,读取;第四步显示出来。
老实说,这一节内容还是很简单的,但是不可否认知识点也是特别多。这一章其实还可以很扩展。比如车牌识别,车牌识别就涉及到车牌前面的汉字识别。这些我原计划都说说的。后来觉得越扯越多,你们越容易记不住。就忍住了。这儿我就给那些比较厉害的学生一些思路吧:车牌识别可以有很多种方法,你最好自己先尝试下,然后再百度网上找例程。汉字的识别例子网上会比较少,但是halcon是可以训练的,就是说你可以自己弄个小资料本里面记载了34个汉字的信息,主要步骤也就5步。我学halcon第一年琢磨了1周多弄会,至今没用到过。这也是我决定不在这本书讲解的原因。
最后,一起来复习下本节学到的新算子。本节新内容有点多:
1)gen_rectangle1 (ROI_0, 560.594, 483.602, 647.781, 688.539):
2)binary_threshold(ImageReduced,Region,'max_separability','dark',UsedThreshold):
3)select_shape (ConnectedRegions, SelectedRegions, 'area', 'and', 150, 99999):
4)union1 (SelectedRegions, RegionUnion):
5)opening_rectangle1 (RegionFillUp, RegionOpening, 1, 3):
6)intersection (RegionOpening, RegionUnion, RegionIntersection):
7)sort_region (ConnectedRegions1, SortedRegions, 'character', 'true', 'row'):
8)read_ocr_class_mlp ('Document_0-9A-Z_NoRej.omc', OCRHandle):
9)do_ocr_multi_class_mlp (SortedRegions, ImageReduced, OCRHandle, Class, Confidence):
10)area_center (SortedRegions, Area, Row, Column):
本节TIPS:
1)2型矩形就是带角度的矩形,比1型矩形多了一个角度,同时参数表达方式也变了,是中心点的横纵坐标和角度外加矩形长宽的一半。你可以F1进入帮助,然后找到gen_rectangle2()看看参数说明。
2) halcon里面以"gen_"开头的算子都是"生成……"的意思,从无到有。所以你以后你想生成什么,不妨试试F1里面搜索下gen,然后找找看,比如生成一个圆形,一个椭圆,一条线,一个点,一个3D模型……不过,也不是所有的生成都是"gen_"开头哦。
3) 设自动阈值的值为t1,自己定一个精度n=1
第一步:将图像按照灰度值0-t1,t1-255分为两个部分,然后分别求出两部分的灰度平均值G1,G2;
第二步:t2=abs(G2-G1);
第三步:若abs(t2-t1)>n,则t1=t2(把t2赋值给t1),返回第一步;若<=n,则t1为自动阈值的值。
厉害了吧?哼哼!
4) 什么逻辑呢?就是halcon有很多算子,近2000个了,这就像很多武功的招式一样,招式多了就有连招,halcon的很多算子也是,经常有些小套路,好几个算子连用,就可以达到某个目的。那这些小套路作为新手的你怎么才能知道呢?所以说这本书还是没买亏,我来告诉你吧:比如咱们这个算子select_shape(),它的上一招在下图的位置(2-3-1-17):

图 2-3-1-17
下一招就是图片里面的后继函数啦,有时候你新学一个算子,怎么用都报错的时候,可以看看它的前趋函数,说不定你前面漏了什么。同样,有时候你新学一个算子,不知道用了之后有什么用的时候,也可以看看它的后继函数!学到了吗?嘿嘿。。。
5) 如下图(2-3-1-18)红框框处,点击:

图 2-3-1-18
就会弹出下图(2-3-1-19)的特征直方图:
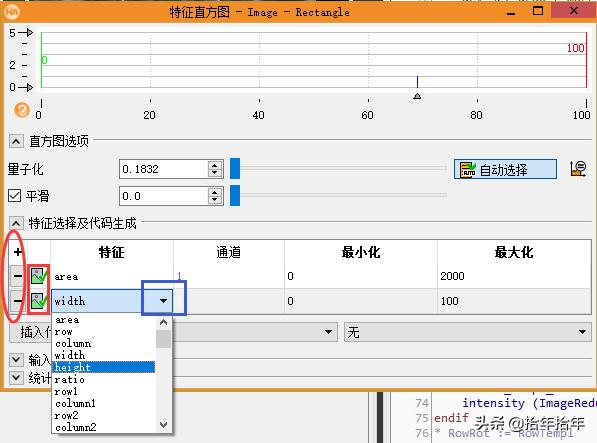
图 2-3-1-19
什么叫特征直方图?就是用直方图来反应特征呗。对吧?相对于正文中教的灰度直方图,就是用直方图来反应灰度值信息了,所以灰度直方图是针对图片的,而特征直方图是针对region的!但是halcon里面region也可以有很多特征的,这个就需要在特征栏进行选择。刚弹出来的这个表在图中矩形框内是一个叉号,你要点击一下才能把它变成我这儿的对勾。特征后面三列第一列暂时别管,后面是这个特征的最小最大值,比如我图中特征第一行,选择的是area,最小化下面是0,最大化下面是2000,就是筛选面积在0到2000之间的region。有时候一个面积特征还不够,咱们还需要多一些特征,就可以我画的椭圆里面进行增删特征,点加号就是再添加一个特征筛选了。可是添加的还是默认是area,再在我画的蓝色矩形处点击向下箭头(这个向下箭头要点击一下才会出来的哦)。就可以在里面找到自己想要的特征来进行筛选了。而最大最小值的设定方法,可以直接在列表里面赋值,也可以通过拉动直方图上的红线绿线,对照直方图进行选定。选好后,点击"插入代码",就可以自动生成select_shape()代码了!
6) union1一个输入参数,把一个参数表示的一堆region合并成一个;union2两个输入参数,把两个参数表示的两个单region合并成一个。
7) 打渔方法:F1进入帮助页面,在左上角搜索栏输入opening,如下图(2-3-1-20)
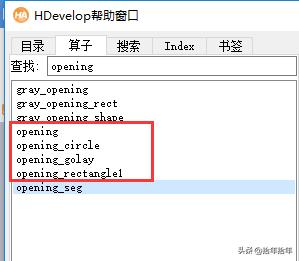
图 2-3-1-20
红框里面的4个算子,第一个算子是用已知的(也就是可以自定义形状的)结构元进行开运算,但是你在用之前,要先生成这个结构元,也就是一个region而已;第二个算子是用圆形结构元来进行开运算;第三个算子是用一个字母来做结构元开运算(说实话这个算子我从来没用过);第四个算子是用1型矩形进行开运算,就是这一节我们用到的。
同样对于闭运算肯定也有这4个。再同样,腐蚀膨胀也有对应的好几个,你会F1就能找到比我解释更详尽的解释。目前阶段我给的建议是:看得懂的几个算子就记小本本上,看不懂的就放那别理它。
8) 一千种图像,可以说有一千种方式分割出字符都不为过。但是程序永远只需要一种方法:最实用的那种!关于本例中的图像,我还可以用下面的方法来分割字符,也是常用的方法来实现:
erosion_rectangle1 (RegionUnion, RegionErosion, 0.5, 3)
dilation_rectangle1 (RegionErosion, RegionDilation, 0.5,3)
connection (RegionDilation, ConnectedRegions1)
先腐蚀再膨胀。刚好你可以复习下刚百度的这几个算子意思。这中间的数学意义,妙不可言。可惜不在我本书的讲解范围内,数学好的自己理解,差点的百度吧,应该也有。实在不行记住方法就够啦,谁管你懂不懂原理!
9) 怎么看到排序后的region是否按照自己意愿排序的?如下图,点击排完序的regions,然后在图像窗口点击每一个小region,就可以看到这个region的排序了。注意:halcon里面数组的序列号是从0开始,图像图形以及region的序列号是从1开始。如下图的"H"是第一个region不是第二个。
图 2-3-1-21
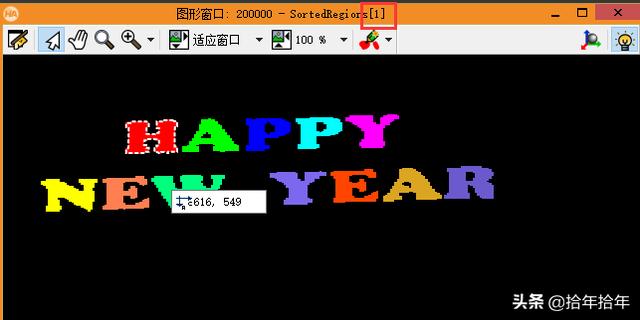
图 2-3-1-22















 447
447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









