





 本文详细介绍了使用Excel进行数据分析的过程,包括明确分析目标、理解数据字段、数据清洗(如隐藏不需要的列、去重、处理缺失值)、数据转换(如使用函数进行数值计算、字符串操作)以及数据可视化。通过数据透视表展示了如何按工作年限和薪水进行统计分析,还讨论了日期数据的处理方法,如按月和周进行统计。此外,提到了VLOOKUP函数在不同表格间数据查询的应用。
本文详细介绍了使用Excel进行数据分析的过程,包括明确分析目标、理解数据字段、数据清洗(如隐藏不需要的列、去重、处理缺失值)、数据转换(如使用函数进行数值计算、字符串操作)以及数据可视化。通过数据透视表展示了如何按工作年限和薪水进行统计分析,还讨论了日期数据的处理方法,如按月和周进行统计。此外,提到了VLOOKUP函数在不同表格间数据查询的应用。
第一步:明确问题,数据分析的目的是什么
第二步:理解数据,数据的可靠性,字段的意义等等
第三步:清洗数据,对脏数据进行清洗,清洗为我们想要的数据样式,方便后期的分析
第四步:数据分析过程或者构建模型
第五步:数据可视化,展示
第一步:明确问题,我们拿到的数据分析职位的招聘信息,
想知道数据分析的薪资水平,年限要求,教育要求等等
第二步:理解数据,即理解各个字段的意义,其中职位id是唯一id
第三步:清洗数据:
显示全部数据:全选所有数据,在开始的地方,选择自动换行
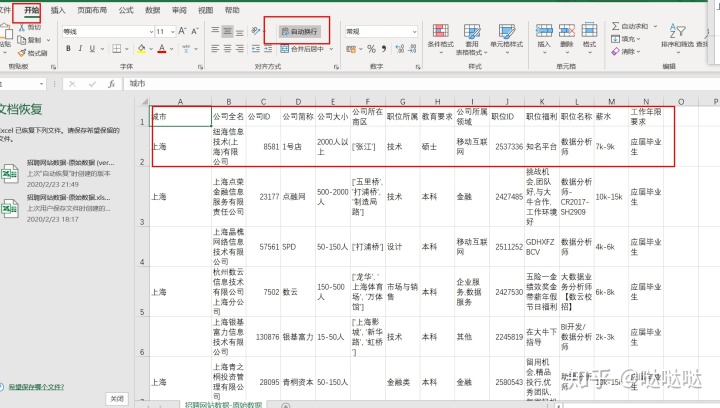
所有的数据就显示全了
excle中数据类型:
总的来说。分为字符串类型,数值类型,和逻辑类型
清洗过程:1,选择数据集合,(就是选择子集)
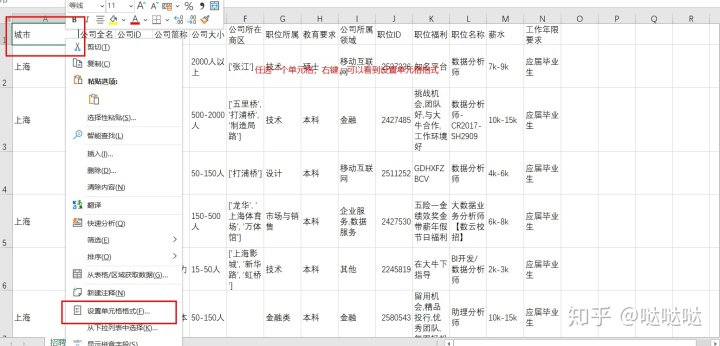
公司id,简称这俩字段用不着,不需要,为了不改变原有数据,可以对这俩列进行隐藏,

选择隐藏的列,右键,点击隐藏
如果需要取消隐藏,

修改字段:双击字段就可以修改
删除重复项:
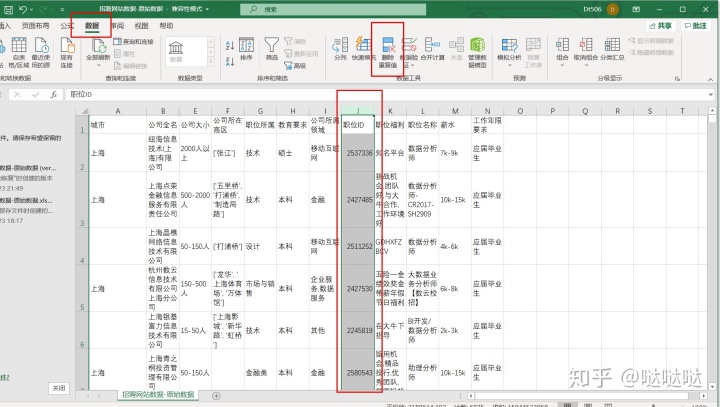
选择按那个字段进行去重,在数据下选择删除重复项即可
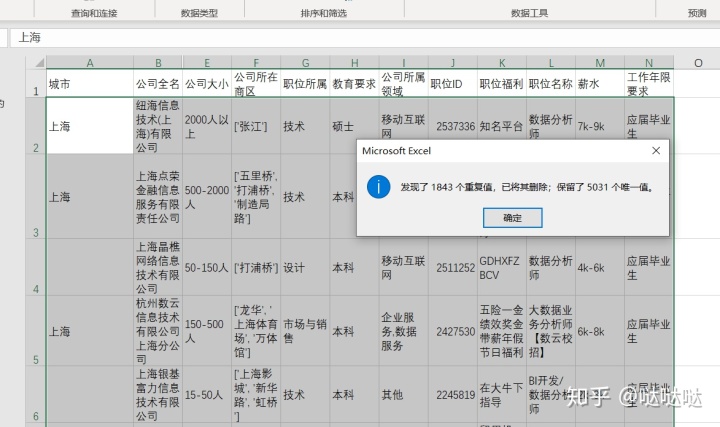
查找缺失,选择id列,在右下角又显示数据条数,同样的方法可以查看任一列的条数
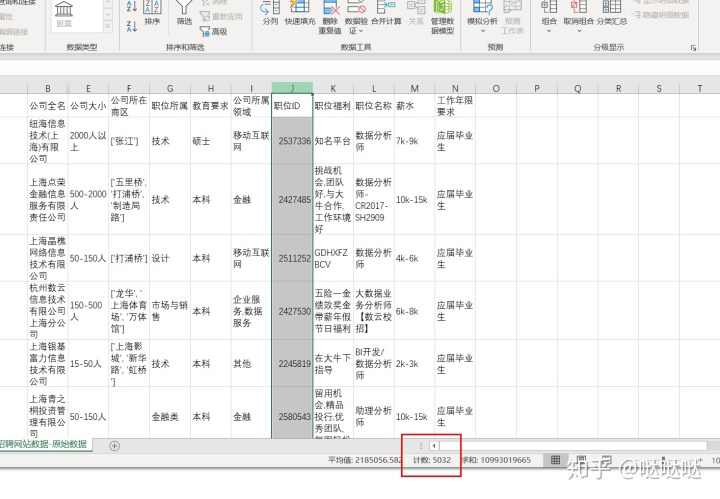
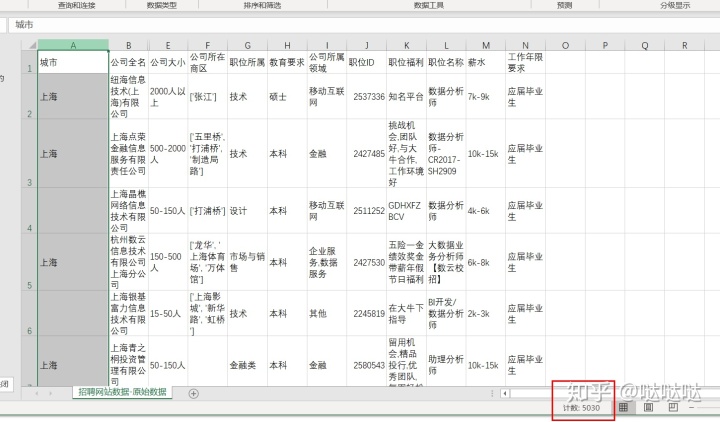
城市这一列缺少了2条数据,找到缺失数据,处理缺失值
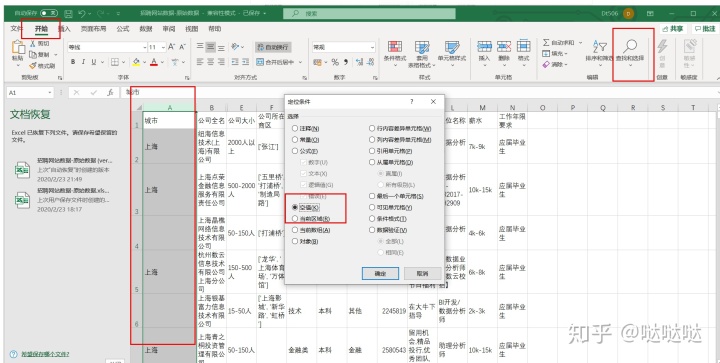
在查找中选择定位条件,条件为空值

在一个输入上海,按ctrl + enter 即空值位置都填充为了上海
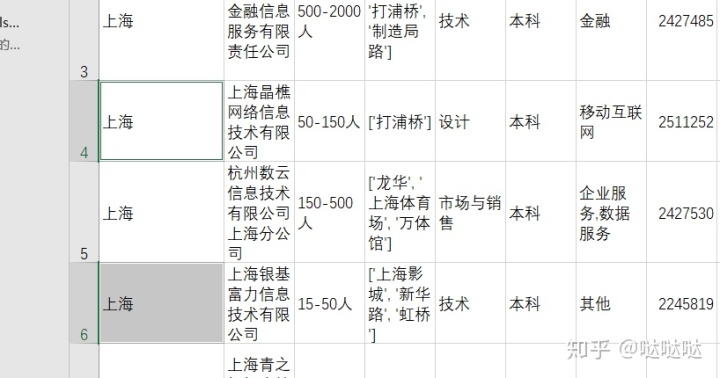
一致化处理:就是将数据格式化为同样的格式,在公式所属领域中,有多个领域,需要拆分
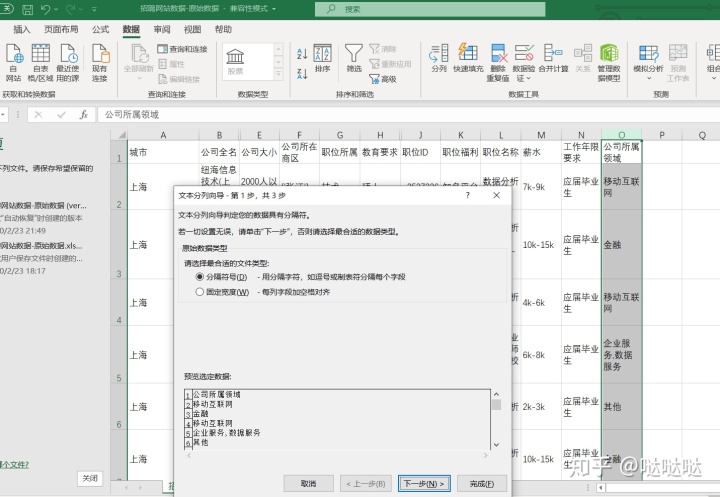
选择这一列,在数据选项卡中,选择拆分,按分割符号拆分,
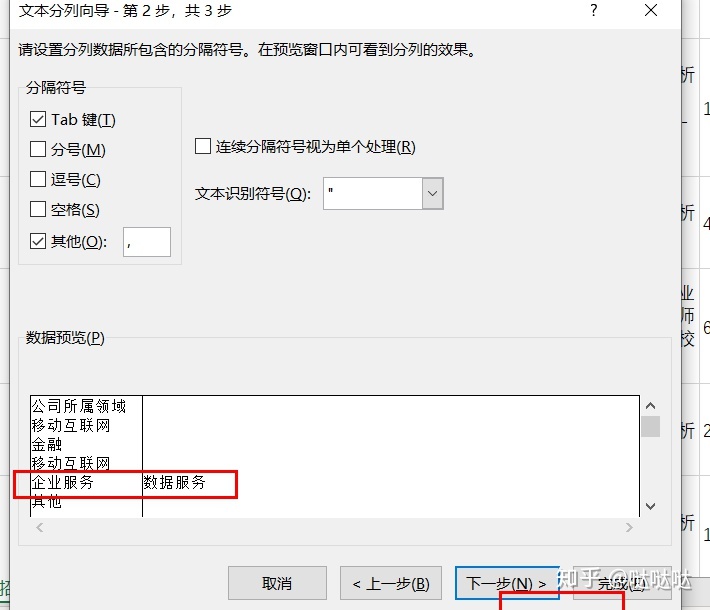
默认的分割符号中,选择其他,,将我们要拆分的分割符号输入

EXCLE常用的函数:
平均值。everage
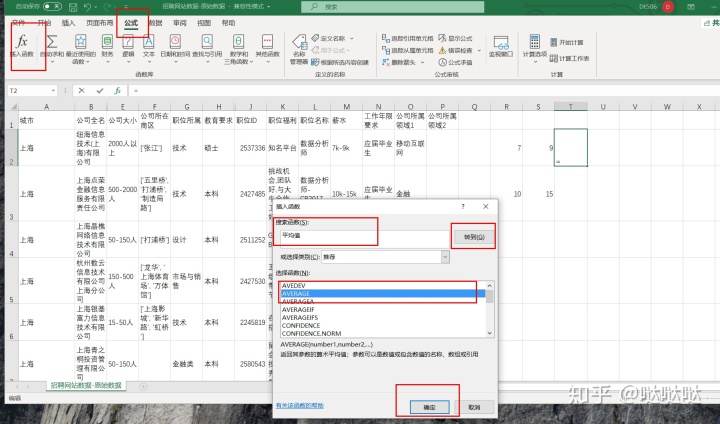
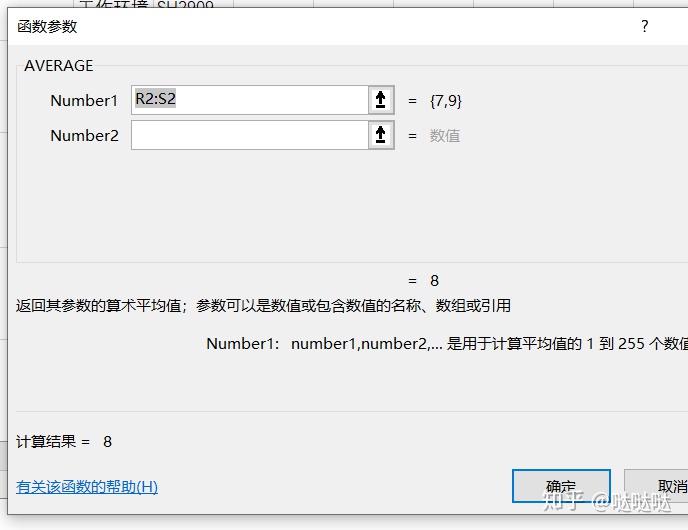
number1是第一个必须参数,选择需要求值的单元格,number2是可选参数,附加的值

在右下角变为+。双击之后将这个公式应用在这一列
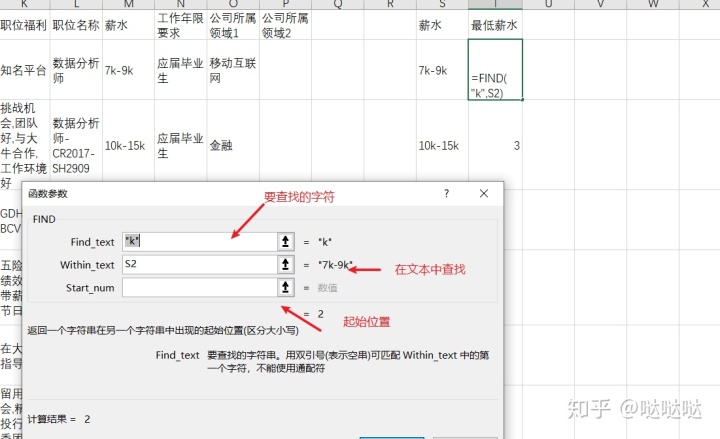
find函数,find(要查找的字符串,字符串所在单元格位置),
用途:查找一个字符串在另一个字符串中出现的起始位置
常配合left,right,mid使用
tleft:,right,mid用途:截取字符串
left(字符串所在单元格位置,从左边开始xx位置进行截取(位置))
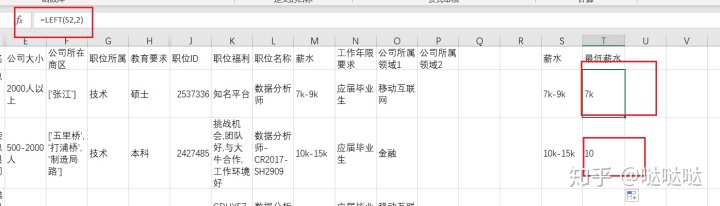
上面就出现了一个问题,如果num_chars是固定的,那就可能截取的是错误的,
这个时候配合find函数一起使用
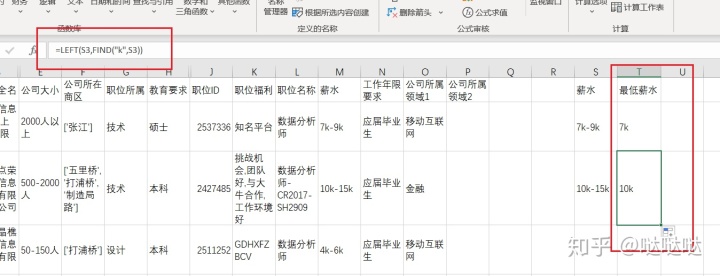
通过find返回位置,配合left函数截取
截取最高薪水不能用right
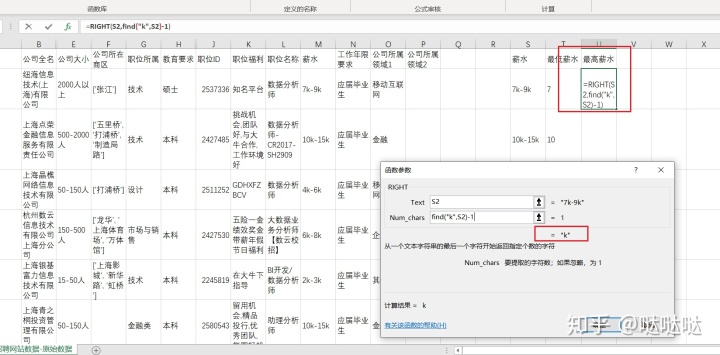
应为find返回的是k在字符串中的第一个位置,不能倒数,
那就只能用mid了、
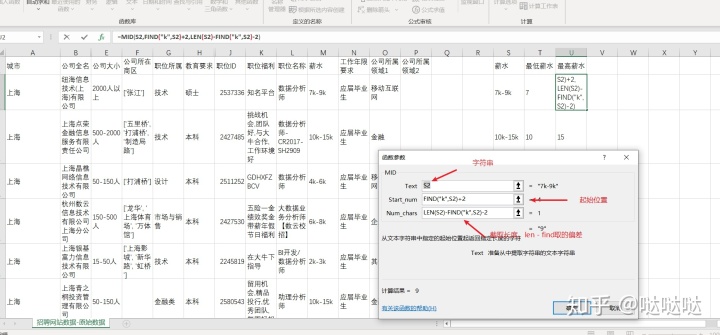
将字符串转换为数值类型
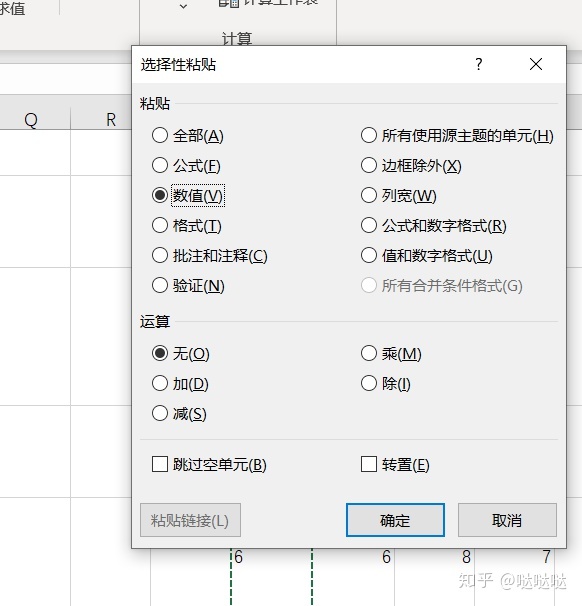
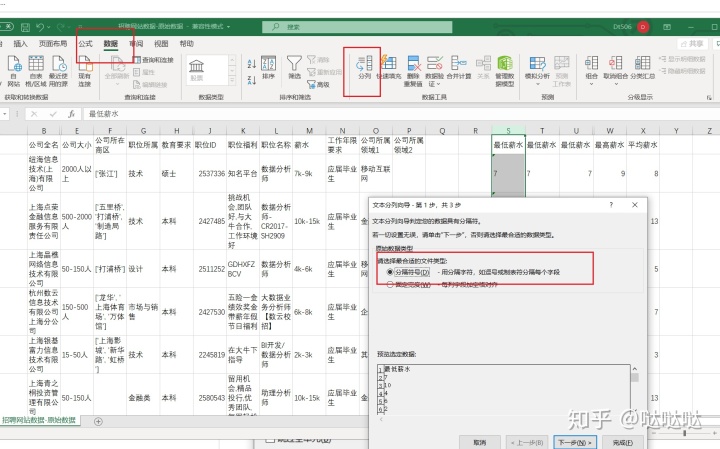
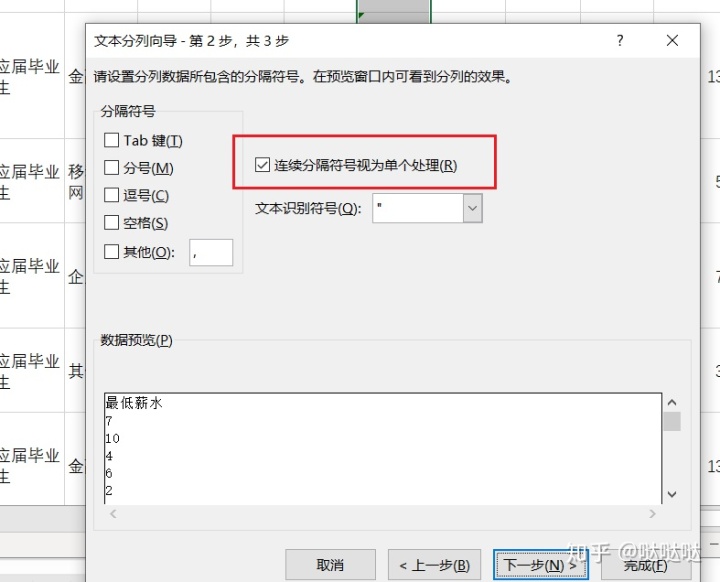
数据排序:
数据透视表的原理:1.数据分组,2,应用函数,3,组合结果
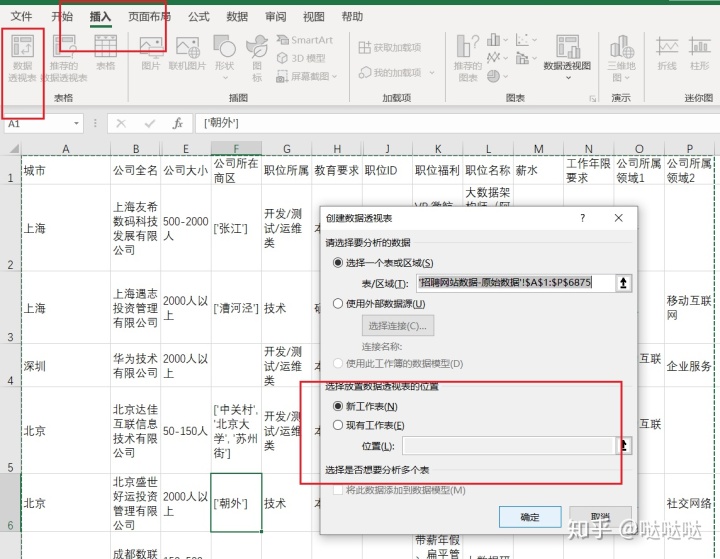
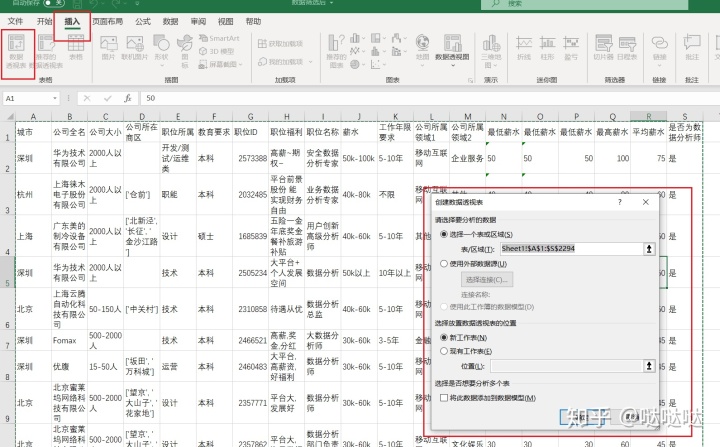
新建一个数据透视表,选择要分组的行
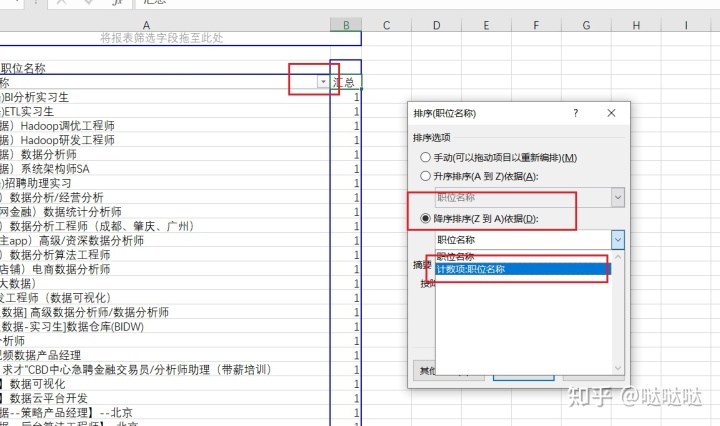
对统计后的结果进行排序,选择按计数项进行排序
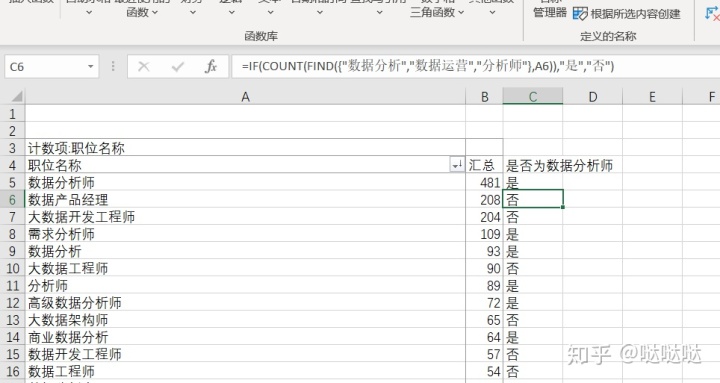
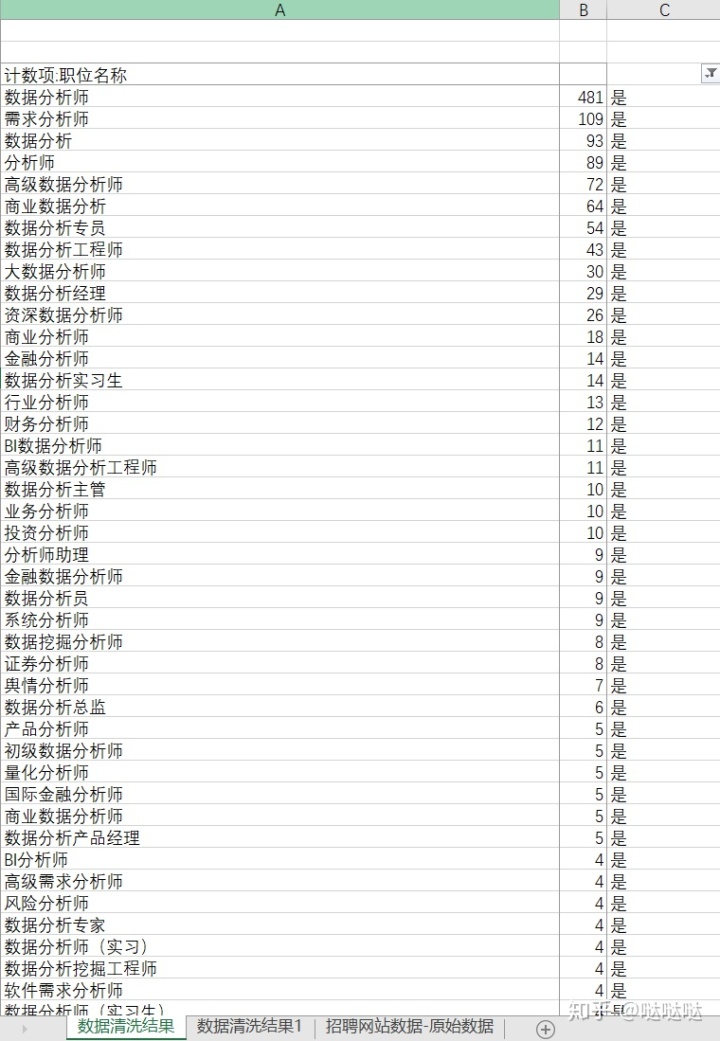
我们需要的是数据分析这个职位的,选择我们需要的岗位
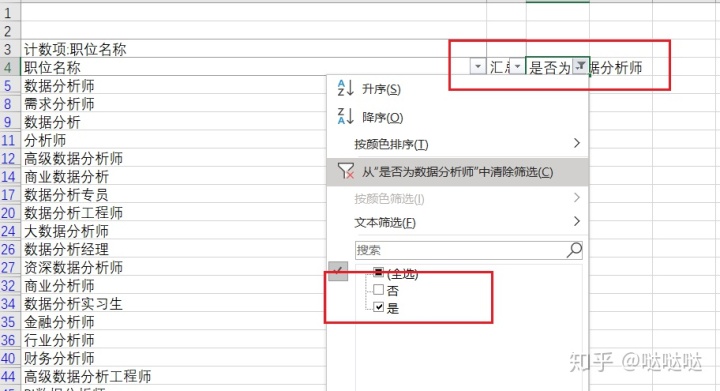
选择我们需要的是的结果,保存
数据分析:主要是利用数据透视表来进行
练习:工作年限的不同,薪水师怎样变化的
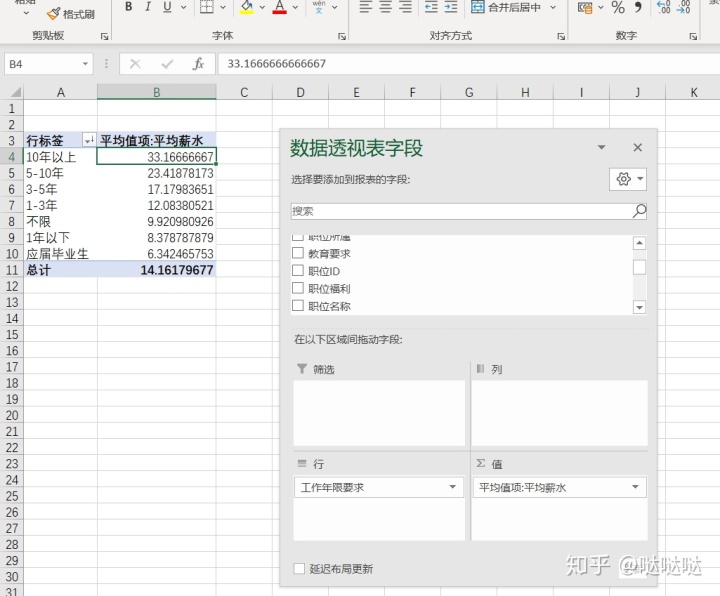
行选择工作年限要求,列选择平均薪水,由于默认值是求和,需要在球的值右键,选择统计的方式。即可,上面可知,工作年限越久,平均薪水越高
日期数据如何处理
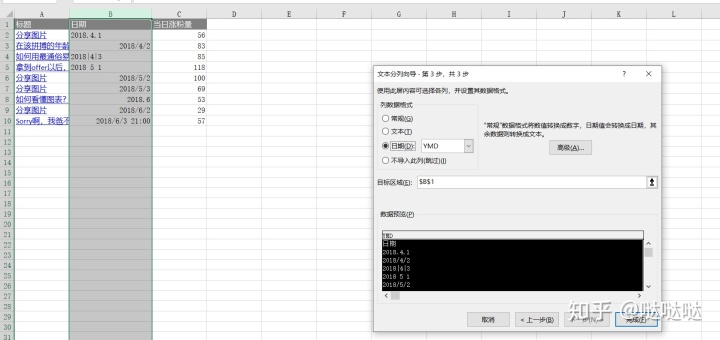
分列。按日期格式进行分列,可对大部分格式进行分列
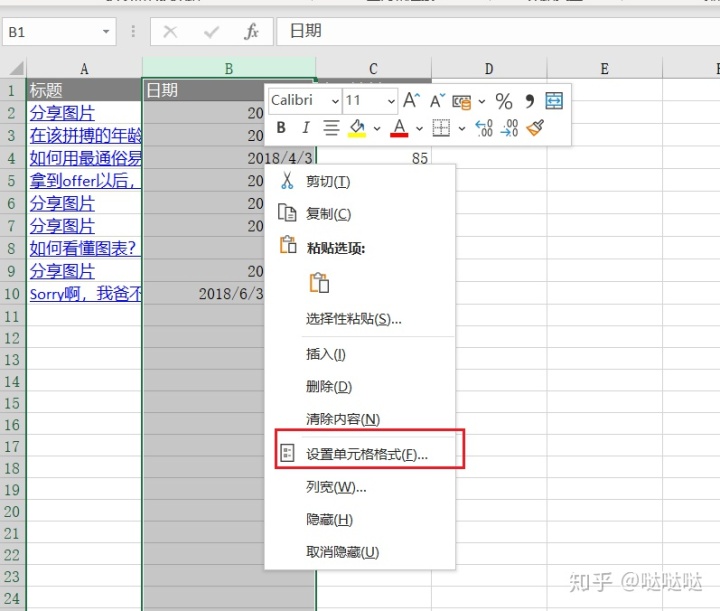
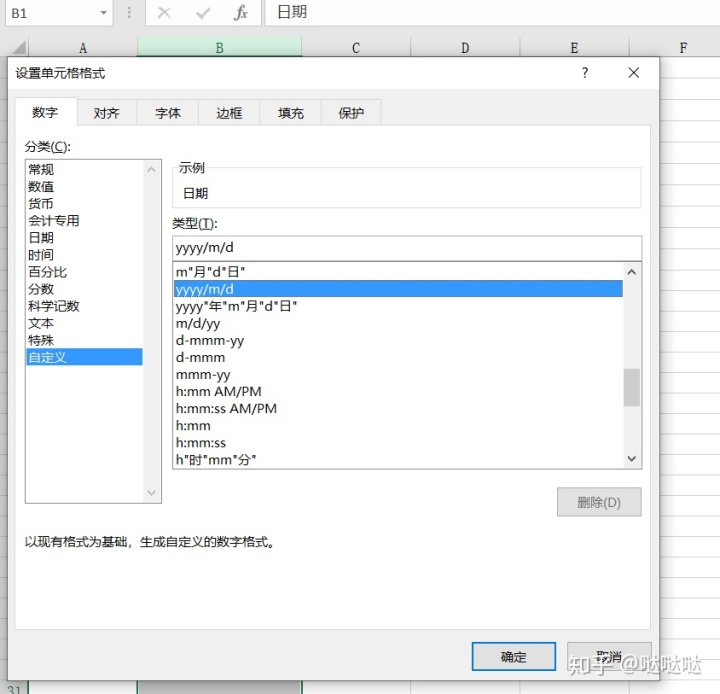
然后自定义日期格式。即可
如何按月统计,使用数据透视表来实现
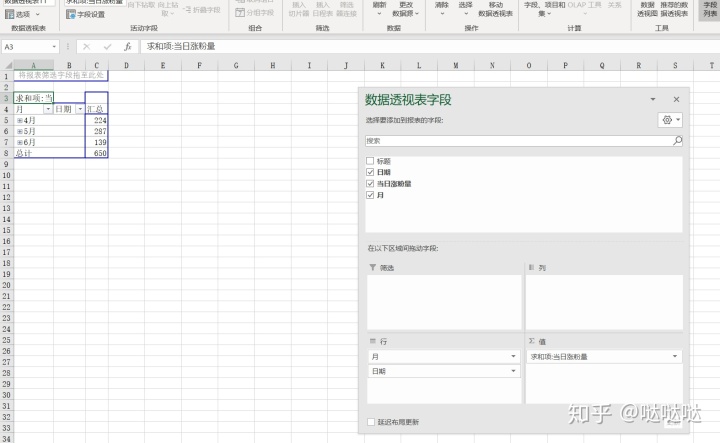
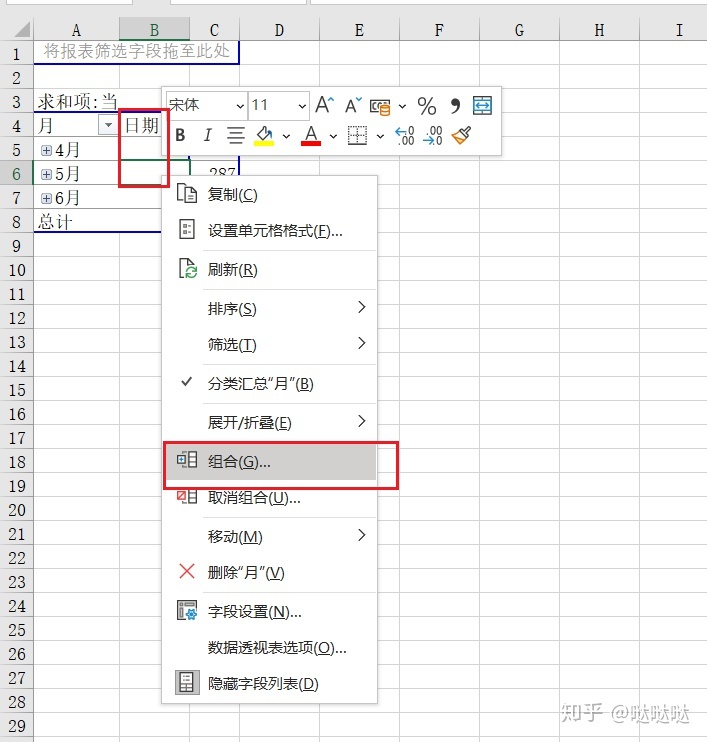
在日期列随便右键,选择组合,选择年月
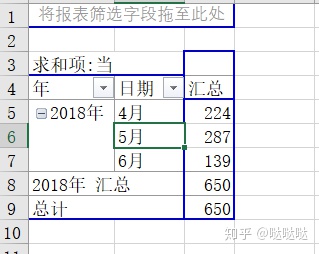
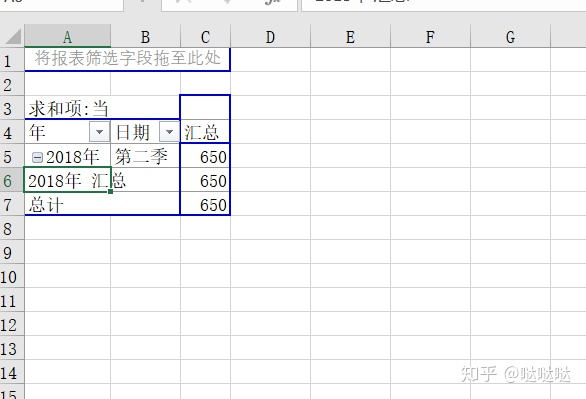
当然也可选择季度
如何按周进行统计
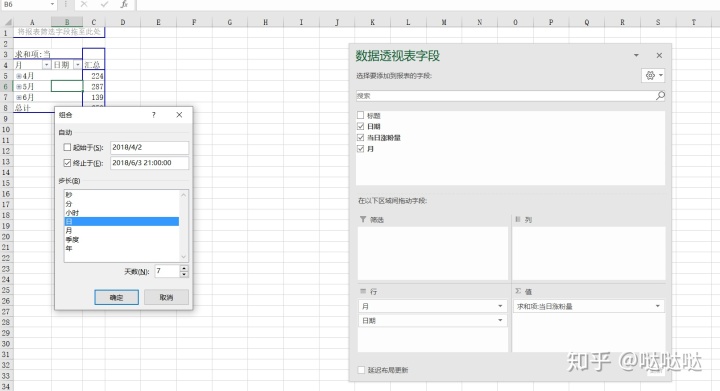
在组合中,选择日,天数选择7天,起始日期设置为实际的起始日期
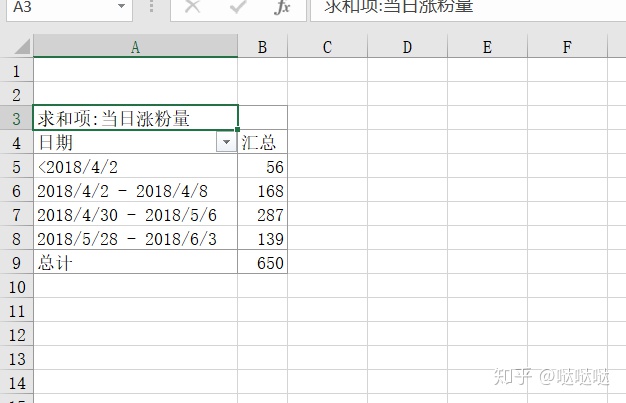
如果不是求和项,可以设置最大值等等
vlookup的使用:一个表和另外一个表之间的连接查询,类似sql中的连接查询
语法:vlookup(找什么,在哪找,第几列,是准确找还是模糊找)
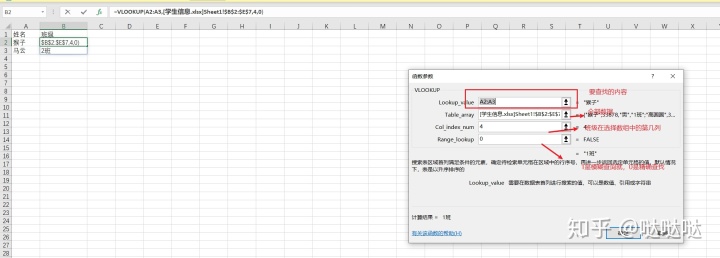
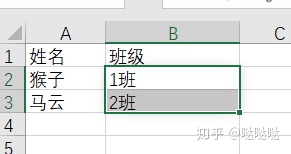
由于是精确查找,找到第一个符合条件之后就直接返回,重复的值不会返回,那入股想要所有的都找到呢,综上可知,得将查找的内容设置为唯一的值,刚好id是唯一的。将内容和id合并后构建一个新的id来进行查找就可以了
三种引用:
相对引用A1,绝对引用$A$1。混合引用$A1 A$1
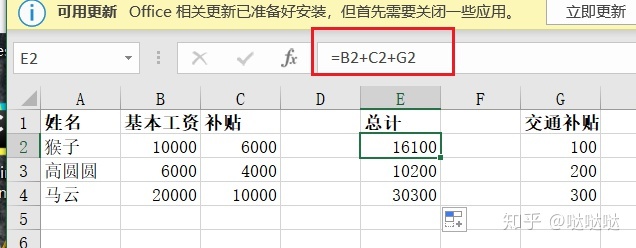
相对引用,默认。单元格会跟随变化变化
绝对引用
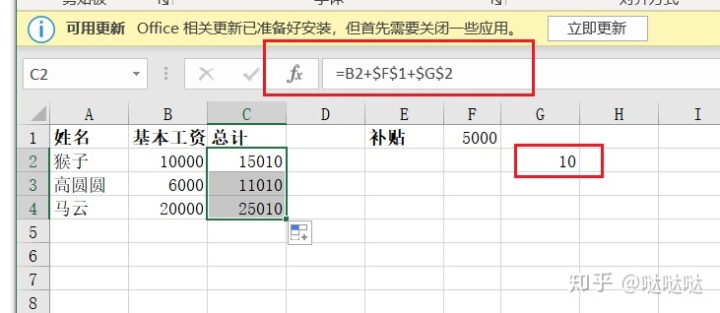
单元格不会相对改变。固定一个单元格
混合引用
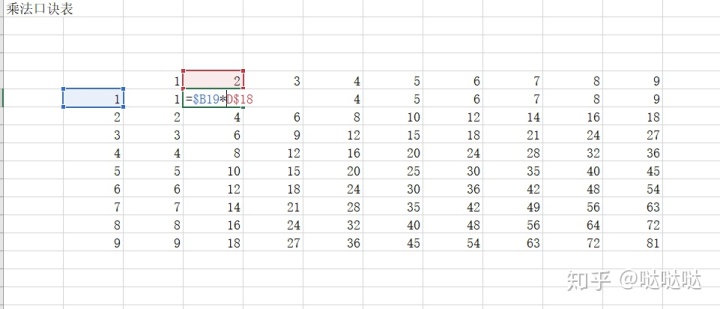
有点难理解。还需深入理解















 1067
1067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









