








学习如何通过剪枝来使你的模型变得更小
剪枝是一种模型优化技术,这种技术可以消除权重张量中不必要的值。这将会得到更小的模型,并且模型精度非常接近标准模型。
在本文中,我们将通过一个例子来观察剪枝技术对最终模型大小和预测误差的影响。
导入常见问题
我们的第一步导入一些工具、包:
- Os和Zipfile可以帮助我们评估模型的大小。
- tensorflow_model_optimization用来修剪模型。
- load_model用于加载保存的模型。
- 当然还有tensorflow和keras。
最后,初始化TensorBoard,这样就可以将模型可视化:
import os
import zipfile
import tensorflow as tf
import tensorflow_model_optimization as tfmot
from tensorflow.keras.models import load_model
from tensorflow import keras
%load_ext tensorboard
数据集生成
在这个实验中,我们将使用scikit-learn生成一个回归数据集。之后,我们将数据集分解为训练集和测试集:
from sklearn.datasets import make_friedman1
X, y = make_friedman1(n_samples=10000, n_features=10, random_state=0)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
没有应用剪枝技术的模型
我们将创建一个简单的神经网络来预测目标变量y,然后检查均值平方误差。在此之后,我们将把它与修剪过的整个模型进行比较,然后只与修剪过的Dense层进行比较。
接下来,在30个训练轮次之后,一旦模型停止改进,我们就使用回调来停止训练它。
early_stop = keras.callbacks.EarlyStopping(monitor=’val_loss’, patience=30)
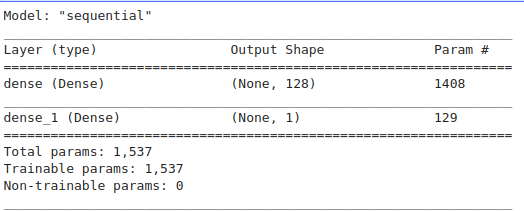
我们打印出模型概述,以便与运用剪枝技术的模型概述进行比较。
model = setup_model()
model.summary()
让我们编译模型并训练它。
tf.keras.utils.plot_model(
model,
to_file=”model.png”,
show_shapes=True,
show_layer_names=True,
rankdir=”TB”,
expand_nested=True,
dpi=96,
)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 379
379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









