







## 什么是分布式事务?
### 什么是事务
**事务是关系型数据库对数据的一系列操作的集合,他可以从以下4个特征是否达到来描述**
* 原子性
> 原子性要求,事务是一个不可分割的执行单元,事务中的所有操作要么全都执行,要么全都不执行。
* 一致性
> 一致性要求,事务在开始前和结束后,数据库的完整性约束没有被破坏。
* 隔离性
> 事务的执行是相互独立的,它们不会相互干扰,一个事务不会看到另一个正在运行过程中的事务的数据。
* 持久性
> 持久性要求,一个事务完成之后,事务的执行结果必须是持久化保存的。即使数据库发生崩溃,在数据库恢复后事务提交的结果仍然不会丢失。
### 什么是分布式事务
**分布式事务,是分布式环境下,对数据一系列操作的集合,通过以下三个特征是否实现来表述**
* 一致性(Consistency) : 客户端知道一系列的操作都会同时发生(生效)
* 可用性(Availability) : 每个操作都必须以可预期的响应结束
* 分区容错性(Partition tolerance) : 即使出现单个组件无法可用,操作依然可以完成
## 分布式环境下的两大理论
### Cap理论 (设计中的限制)
> Cap告诉你,分布式事务的三条性质,你的系统里同时只能实现两条。如在实现分区容错性的条件下,数据A,存在分区P1和P2中,某个时间P1中的数据A发生了变化,这个时候为了满足分区一致,你得把数据传输到P2,而你又不希望客户端看到两个版本的数据A(一致性),那么你选择不让客户端看到数据(牺牲了可用性)。
### Base理论 (设计中的取舍)
* Basically Available(基本可用)
* Soft state(软状态)
* Eventually consistent(最终一致性)
> BASE理论是对CAP中的一致性和可用性进行一个权衡的结果,理论的核心思想就是:我们无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)。
## 分布式事务的解决方案
* DTP模型
* 基于可靠消息服务的分布式事务 [保证上下游两个操作组成的事务的一致性]
* 最大努力通知 [保证上下游两个操作组成的事务的一致性]
* TCC
* DogTCC
#### DTP模型的定义
> DTP只是一套实现分布式事务的规范,并没有定义具体如何实现分布式事务,TM可以采用2PC、3PC、Paxos等协议实现分布式事务。
##### 模型的三个角色
* AP:Application 应用系统
它就是我们开发的业务系统,在我们开发的过程中,可以使用资源管理器提供的事务接口来实现分布式事务。
* TM:Transaction Manager 事务管理器
分布式事务的实现由事务管理器来完成,它会提供分布式事务的操作接口供我们的业务系统调用。这些接口称为TX接口。
事务管理器还管理着所有的资源管理器,通过它们提供的XA接口来同一调度这些资源管理器,以实现分布式事务。
* RM:Resource Manager 资源管理器
能够提供数据服务的对象都可以是资源管理器,比如:数据库、消息中间件、缓存等。大部分场景下,数据库即为分布式事务中的资源管理器。
资源管理器能够提供单数据库的事务能力,它们通过XA接口,将本数据库的提交、回滚等能力提供给事务管理器调用,以帮助事务管理器实现分布式的事务管理。XA是DTP模型定义的接口,用于向事务管理器提供该资源管理器(该数据库)的提交、回滚等能力。DTP只是一套实现分布式事务的规范,RM具体的实现是由数据库厂商来完成的。
##### DTP模型接口的定义
* XA , 资源管理器实现的接口
* TM , 事务管理器实现的接口
> DTP只定义了这两个接口,未定义这两个接口需要实现的内容
####DTP模型的实现 (三个角色,不同的接口)
##### mysql实现的XA接口
##### JTA
##### 2PC
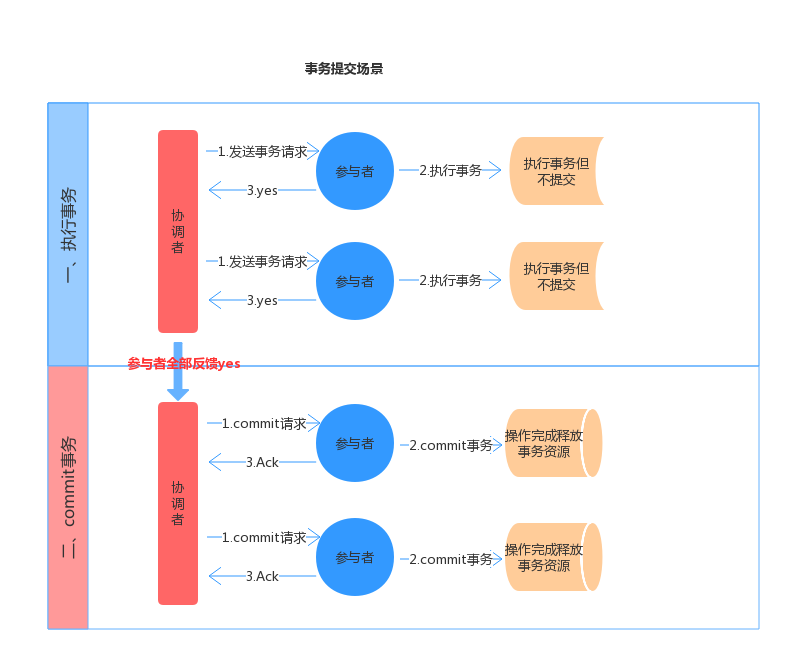
* 第一阶段:
协调者会问所有的参与者结点,是否可以执行提交操作。
各个参与者开始事务执行的准备工作:如:为资源上锁,预留资源,写undo/redo log……
参与者响应协调者,如果事务的准备工作成功,则回应“可以提交”,否则回应“拒绝提交”。
* 第二阶段:
如果所有的参与者都回应“可以提交”,那么,协调者向所有的参与者发送“正式提交”的命令。参与者完成正式提交,并释放所有资源,然后回应“完成”,协调者收集各结点的“完成”回应后结束这个Global Transaction。
如果有一个参与者回应“拒绝提交”,那么,协调者向所有的参与者发送“回滚操作”,并释放所有资源,然后回应“回滚完成”,协调者收集各结点的“回滚”回应后,取消这个Global Transaction。
> 缺点: 阻塞 脑裂 单点故障
###### 3PC
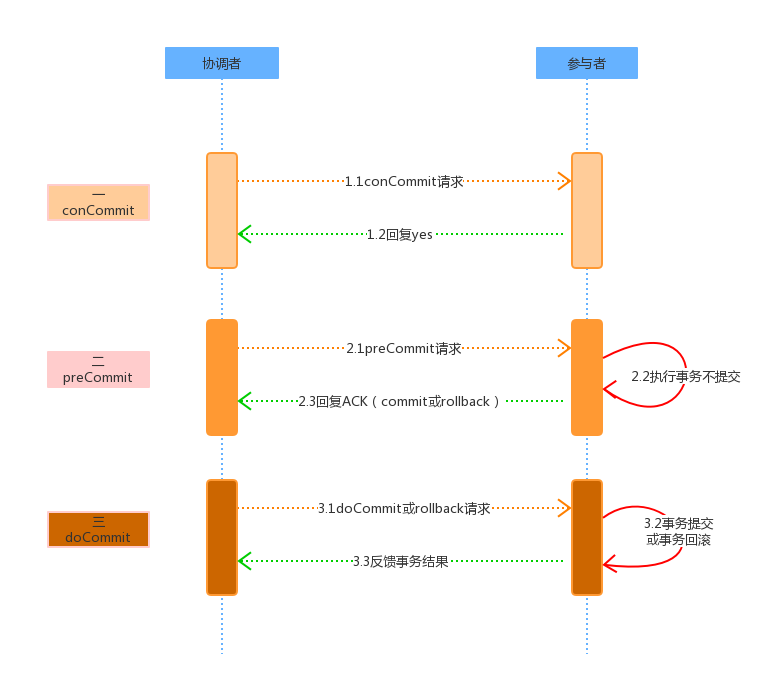
* 相对于2PC,3PC主要解决的单点故障问题,并减少阻塞,因为一旦参与者无法及时收到来自协调者的信息之后,他会默认执行commit。而不会一直持有事务资源并处于阻塞状态。但是这种机制也会导致数据一致性问题,因为,由于网络原因,协调者发送的abort响应没有及时被参与者接收到,那么参与者在等待超时之后执行了commit操作。这样就和其他接到abort命令并执行回滚的参与者之间存在数据不一致的情况。
#### 基于可靠消息服务的分布式事务
* 这种实现分布式事务的方式需要通过消息中间件来实现。假设有A和B两个系统,分别可以处理任务A和任务B。此时系统A中存在**一个业务流程,需要将任务A和任务B在同一个事务中处理**。

**当上游系统执行完任务并向消息中间件提交了Commit指令后,便可以处理其他任务了,此时它可以认为事务已经完成,接下来消息中间件一定会保证消息被下游系统成功消费掉!那么这是怎么做到的呢?这由消息中间件的投递流程来保证。**
消息中间件向下游系统投递完消息后便进入阻塞等待状态,下游系统便立即进行任务的处理,任务处理完成后便向消息中间件返回应答。消息中间件收到确认应答后便认为该事务处理完毕!
如果消息在投递过程中丢失,或消息的确认应答在返回途中丢失,那么消息中间件在等待确认应答超时之后就会重新投递,直到下游消费者返回消费成功响应为止。当然,一般消息中间件可以设置消息重试的次数和时间间隔,比如:当第一次投递失败后,每隔五分钟重试一次,一共重试3次。如果重试3次之后仍然投递失败,那么这条消息就需要人工干预。
#### 最大努力通知

对于基于可靠消息服务的分布式事务,是一个理想化的过程,但在实际场景中,往往会出现如下几种意外情况:
消息中间件向下游系统投递消息失败
上游系统向消息中间件发送消息失败
对于第一种情况,消息中间件具有重试机制,我们可以在消息中间件中设置消息的重试次数和重试时间间隔,对于网络不稳定导致的消息投递失败的情况,往往重试几次后消息便可以成功投递,如果超过了重试的上限仍然投递失败,那么消息中间件不再投递该消息,而是记录在失败消息表中,消息中间件需要提供失败消息的查询接口,下游系统会定期查询失败消息,并将其消费,这就是所谓的“定期校对”。
如果重复投递和定期校对都不能解决问题,往往是因为下游系统出现了严重的错误,此时就需要人工干预。
对于第二种情况,需要在上游系统中建立消息重发机制。可以在上游系统建立一张本地消息表,并将 任务处理过程 和 向本地消息表中插入消息 这两个步骤放在一个本地事务中完成。如果向本地消息表插入消息失败,那么就会触发回滚,之前的任务处理结果就会被取消。如果这量步都执行成功,那么该本地事务就完成了。接下来会有一个专门的消息发送者不断地发送本地消息表中的消息,如果发送失败它会返回重试。当然,也要给消息发送者设置重试的上限,一般而言,达到重试上限仍然发送失败,那就意味着消息中间件出现严重的问题,此时也只有人工干预才能解决问题。
对于不支持事务型消息的消息中间件,如果要实现分布式事务的话,就可以采用这种方式。它能够通过重试机制+定期校对实现分布式事务,但相比于第二种方案,它达到数据一致性的周期较长,而且还需要在上游系统中实现消息重试发布机制,以确保消息成功发布给消息中间件,这无疑增加了业务系统的开发成本,使得业务系统不够纯粹,并且这些额外的业务逻辑无疑会占用业务系统的硬件资源,从而影响性能。
### TCC模式

#### TCC模式系统构成
* 上图我们可以看到以下几个组件
事务发起方(MainService)
事务管理器(TransactionManager)
事务服务方(Server)
* 以下几个过程
prepare -> try
commit -> confirm
rollback -> cancel
#### TCC执行流程
1. 事务发起方向事务管理器注册服务
2. 事务发起方向服务方发起prepare命令
3. 事务服务方执行try操作
4. 事务发起方将执行结果告诉事务管理器
5. 事务管理器根据事务执行结果,向事务服务发送Confirm或者Cancel
### 现有系统存在的问题
* 2PC,3PC 的问题 : 数据不一致
* 最大努力通知的问题: 对系统侵入性太强
* 传统TCC系统存在的问题
1. 需要自己实现事务管理器的集群。
2. 链式调用延迟,可以想象,如果服务方又是事务发起方,那么对他的调用中,又将涉及新事务产生。事务的Confirm和Cancel怎么设计,将是对系统的挑战。
> 假设A调用B(B调用E,F)和C。对于B来说,如果不存在链式调用,E,F中有一个失败,另外一个回滚即可。而现在现在情况变了,在这个假设里,E,F服务的Confirm或Cancel还取决于C服务。这就大大增加了系统的复杂性,如果C服务有是链式调用,那么更加复杂,多级的等待将使系统变的不可用。另外链式调用中,事务的不断创建也是对性能的损耗。
### DogTCC
> 一个易用的开源分布式TCC事务框架
* DogTCC在传统TCC的基础上,将事务注入业务的消息流中链式传输,各个消息链中的服务无需和调用方保持连接,调用方可通过原有的消息返回通道获取返回结果,去掉了发起方和被调用发try操作的确认流程,大大提升了性能。
* 因为事务的链式传输,使得逻辑上在一个事务中的调用自然的变成了一个事务,而非传统DogTCC会出现的多层次树状调用,解决了链式调用的问题。
* 事务发起方和事务服务方间无链接,并且都为无状态服务,更容易并发。

源码地址: https://github.com/sunpengChina/dog















 793
793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









