





【背景】:业务需求,如果需要知道聊天对话中哪些词语或者话题占比最高,就需要词云图的帮助了
【引用】:这几篇博主真的写的非常的清楚了,顺序按我放的顺序看即可~
- 结巴分词并生产词云图的详细代码

- 下面的链接是结巴的三种模式
【实例】:分成两个:1、生成词云图 2、词频统计并返回权重
- 生成词云图 :
1、生成词云图
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
import jieba
# 数据获取
with open("C:hhh.txt",'r', encoding='gbk')as f:
text=f.read()
# with open('dream is possible.txt','r',encoding='gbk')as f:
# text=f.read()
#图片获取
mask=np.array(Image.open("C:heart.png"))--这是词云的背景图形状
# 数据清洗
# 屏蔽45
# STOPWORDS.add('45')
font=r'C:WindowsFontssimhei.ttf'---(必须引用字体不然代码会报错)
sep_list=jieba.lcut_for_search(text,)---(结巴有三种方式,全模式、精确模式、搜索引擎模式见链接3)
sep_list=" ".join(sep_list)
wc=WordCloud(
scale=4,#调整图片大小---(如果设置太小图会很模糊)
font_path=font,#使用的字体库
max_words=200, # 词云显示的最大词数
margin=2,#字体之间的间距
mask=mask,#背景图片
background_color='white', #背景颜色
max_font_size=200,
# min_font_size=1,
# stopwords=STOPWORDS, #屏蔽的内容
collocations=False, #避免重复单词
width=1600,height=1200 #图像宽高,字间距
)
wc.generate(sep_list) #制作词云
wc.to_file('词云.jpg') #保存到当地文件
# 图片展示
plt.figure(dpi=100) #通过这里可以放大或缩小
plt.imshow(wc,interpolation='catrom')
plt.axis('off')
plt.show()
【效果图1】:

2.词频统计并返回权重
2、词频统计并返回权重
from jieba.analyse import *
data = open("C:hhh.txt",'r', encoding='gbk').read()#读取文件
for keyword, weight in extract_tags(data, topK=30,withWeight=True,allowPOS=()):
#topK为返回几个TF/IDF权重最大的关键词,默认值为20
# withWeight为是否一并返回关键词权重值,默认值为False
# allowPOS仅包括指定词性的词,默认值为空,即不筛选
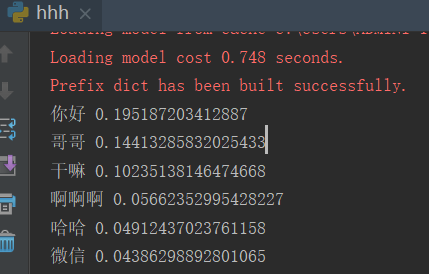
print('%s %s' % (keyword, weight))【效果图2】:
【问题】:写代码的时候中间遇到的问题
- UTF-8编码报错:我就试了一下gbk ,就可以读取了,所以遇到这类问题,可以多试试编码类型
- 词云图有重复词语:最后发现自己忘记加collocations=False了
- 图片太模糊:因为之前设置的scale=1,调成4后就好了















 687
687











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









