







上篇:电商用户行为分析项目 第3节 更换Kafka 作为数据源
1、模块创建和数据准备
在UserBehaviorAnalysis下新建一个 maven module作为子项目,命名为NetworkTrafficAnalysis。在这个子模块中,我们同样并没有引入更多的依赖,所以也不需要改动pom文件。
在src/main/目录下,将默认源文件目录java改名为scala。将apache服务器的日志文件apache.log复制到资源文件目录src/main/resources下,我们将从这里读取数据。
2、创建子模块(NetworkTrafficAnalysis)
(1)创建工程步骤:
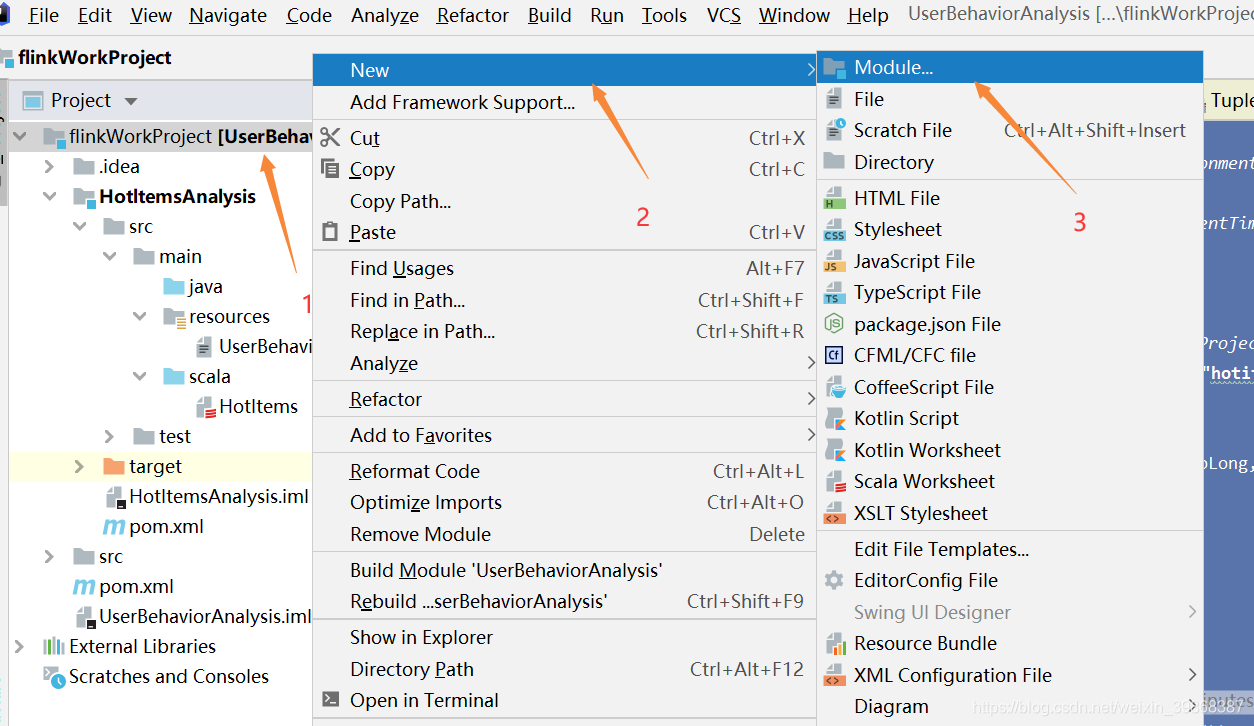
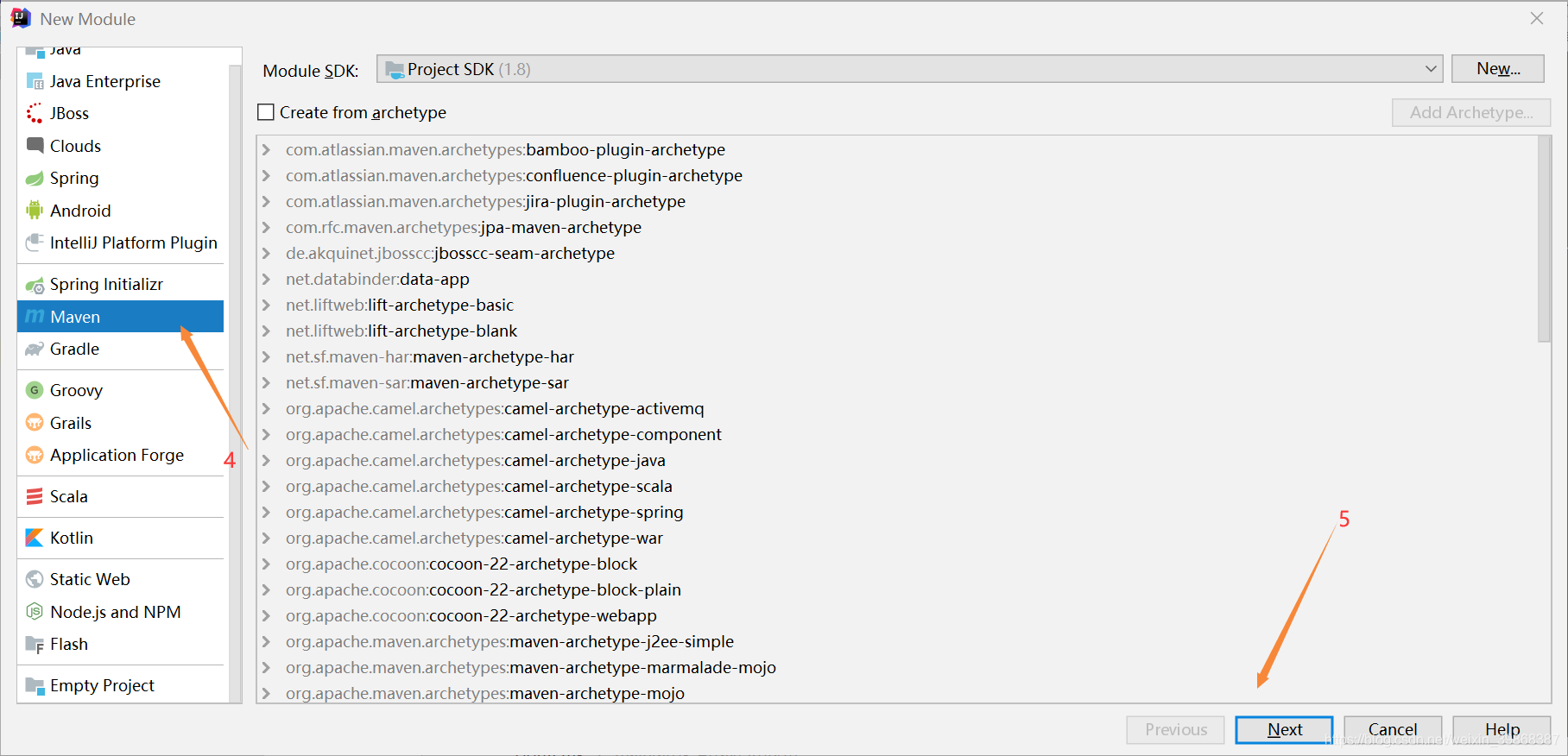

工程创建ok

(2)创建scala文件目录:

(3)apachetest.log文件拷贝到resource文件

3、分析代码实现步骤说明
(1)代码实现
我们现在要实现的模块是 “实时流量统计”。对于一个电商平台而言,用户登录的入口流量、不同页面的访问流量都是值得分析的重要数据,而这些数据,可以简单地从web服务器的日志中提取出来。我们在这里实现最基本的“页面浏览数”的统计,也就是读取服务器日志中的每一行log,统计在一段时间内用户访问url的次数。
具体做法为:每隔5秒,输出最近10分钟内访问量最多的前N个URL。可以看出,这个需求与之前“实时热门商品统计”非常类似,所以我们完全可以借鉴此前的代码。
在src/main/scala下创建TrafficAnalysis.scala文件,新建一个单例对象。定义样例类ApacheLogEvent,这是输入的日志数据流;另外还有UrlViewCount,这是窗口操作统计的输出数据类型。在main函数中创建StreamExecutionEnvironment 并做配置,然后从apache.log文件中读取数据,并包装成ApacheLogEvent类型。
需要注意的是,原始日志中的时间是“dd/MM/yyyy:HH:mm:ss”的形式,需要定义一个DateTimeFormat将其转换为我们需要的时间戳格式:
.map(line => {
val linearray = line.split(" ")
val sdf = new SimpleDateFormat("dd/MM/yyyy:HH:mm:ss")
val timestamp = sdf.parse(linearray(3)).getTime
ApacheLogEvent(linearray(0), linearray(2), timestamp,
linearray(5), linearray(6))
})
4、完整代码
NetworkTraffic.scala
package com.study.NetworkTrafficAnalysis
import java.sql.Timestamp
import java.text.SimpleDateFormat
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.api.common.state.{
ListState, ListStateDescriptor}
import org.apache.flink.streaming.api 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3067
3067











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









