





1.1引言
1.2基本术语
按照课文给的实例,关于西瓜的数据。
数据集:整个所给的数据的集合称为数据集
样本/示例:一个事件或者对象,这里的是一个西瓜
属性/特征:事件或者对象的某方面的表现或性质,比如西瓜的色泽,根蒂,敲声
属性值:属性的取值,比如色泽属性可以取青绿、乌黑
属性空间/样本空间/输入空间:整个属性张成的空间,比如把上述的三个属性在一个三维坐标中表示出
一个西瓜的三位空间,每一个西瓜都可以在在这个空间中找到自己的位置。
特征向量:空间中的每一个点都对应一个坐标向量,所以每一个样本也可以称为特征向量
训练数据:用于训练的数据
训练样本:训练数据中的每一一个样本
标记空间/输出空间:所有输出的集合
分类:预测的是离散值
回归:预测的是连续值
二分类:只涉及两个类别的任务,其中一个称为正类,另一个为负类
多分类:
聚类:训练集中的样本分成若干个组,每一组称为一个‘簇’
监督学习:有标记信息,(分类,回归)
无监督学习:无标记信息(聚类)
泛化能力:学得的模型能够适用于新样本的能力
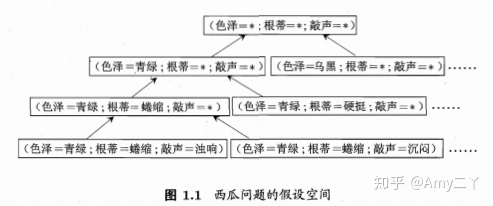
1.3假设空间
归纳:从特殊到一般(广义归纳:相当于从样本中学习。狭义归纳:从训练集中学的概念,因此称为概念学习)
演绎:从一般到特殊
概念学习:最基本的就是布尔概念学习
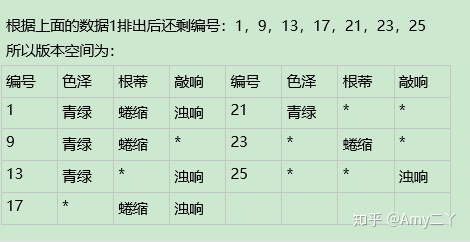
假设集合/版本空间:有多个假设与训练集一致,即与训练集一致

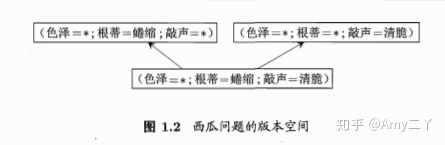
1.4归纳偏好
归纳偏好:机器学习算法在学习的过程中对某种类型假设的偏好
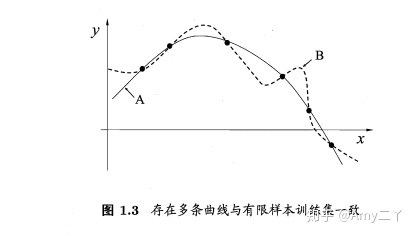
奥卡姆剃刀:若多个假设与观察一致,则选择最简单的一个,比如下图选择较为平滑的哪个
没有免费的午餐定理NFL:所有的学习算法总误差和期望值与算法无关。
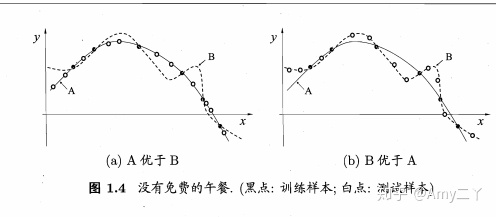
如上图,对于某些问题,A可能优于B,但一定会相应存在一些情况B优于A。所以,具体问题具体分析。
习题:
1.1 表1.1中若只包含编号为1和4的两个样例,试给出相应的版本空间。


*















 6439
6439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









