






我的微信公众号:不断努力的霜木君
虽然不怎么更新,但有机会就分享点东西上去,探讨一下世界与人生的哲学。
这是大四上学期机器学习基础课程的大作业,挺有意思的。后面如果有同学也选了这门课,可以选这个题。
由于我们在做的过程中也参考了很多大佬的做法,所以完全开源。
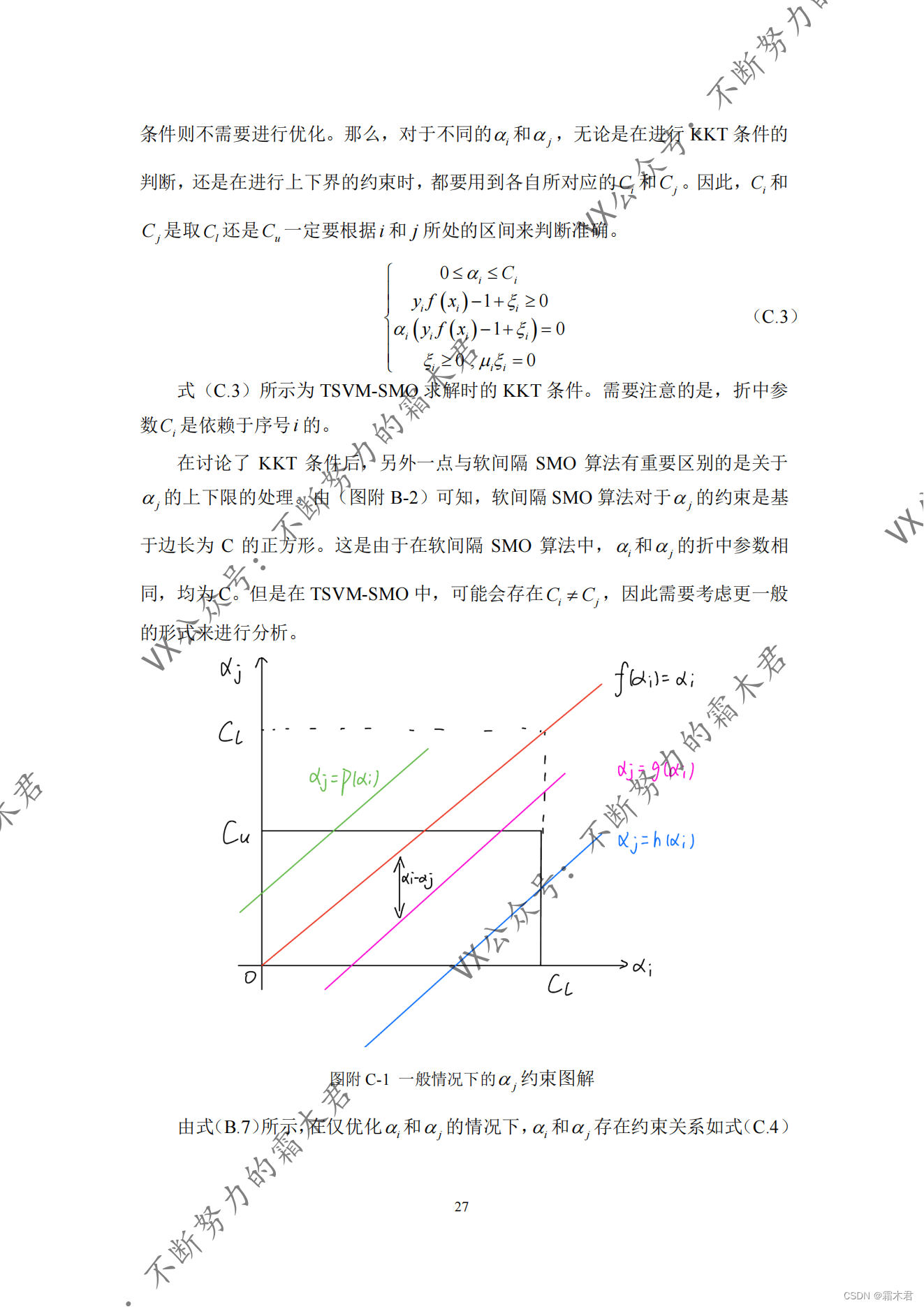
特点在于:SMO算法中,针对TSVM做了改动,在KKT条件判定、松弛因子等部分都考虑得比较严密。欢迎大家在评论区与我讨论(在我还记得这个项目期间)。
总得来说,我感觉我们这个项目做的不错,完全结合书上的理论做了改动,并不是直接把网上的东西搬过来用,最后老师给了我94分,还行吧,可能我在汇报的时候讲的不够突出,以后继续努力。
下面展示部分报告内容,具体分析及源码请查看报告
下载链接:






源码(部分):

clc
clear all
close all
%% 数据载入
datas = load("iris.data")
rowrank = randperm(size(datas, 1)); % size获得datas的行数,randperm打乱各行的顺序
data_random = datas(rowrank,:); % 按照rowrank重新排列各行,注意rowrank的位置
X = data_random(1:10,1:4); %有标记样本
y = data_random(1:10,5)'; %有标记样本的标记(这里以行向量存储,要不下面会报错)
X_unknown = data_random(11:70,1:4); %无标记样本
X_test = data_random(71:100,1:4); %测试样本
y_test = data_random(71:100,5)'; %测试样本标记(这里以行向量存储,要不下面会报错)
% y = [1,1,1,1,1,1,1,1,-1,-1,-1,-1,-1,-1,-1,-1,-1];% 标记向量 %采用西瓜来测试
% y = double(y);
% X = [0.697,0.460;0.774,0.376;0.634,0.264;...% 属性向量
% 0.608,0.318;0.556,0.215;0.403,0.237;...
% 0.481,0.149;0.437,0.211;0.666,0.091;...
% 0.243,0.267;0.245,0.057;0.343,0.099;...
% 0.639,0.161;0.657,0.198;0.360,0.370;...
% 0.593,0.042;0.719,0.103];
% X_unknown = [0.7,0.3;0.3,0.7;0.5,0.5;0.6,0.4;0.6,0.6;0.2,0.2;0.5,0.1];
% X = double(X);
%% 采用线性核或高斯核
kernel_type = 1; % 0代表线性核,1代表高斯核
%% 线性核建立
K_L = zeros(size(y,2),size(y,2));
for i=1:size(y,2)
for j=1:size(y,2)
K_L(i,j) = X(i,:)*X(j,:)';
end
end
%% 高斯核建立
K_G = zeros(size(y,2),size(y,2));
sigma = 100;
for i=1:size(y,2)
for j=1:size(y,2)
K_G(i,j) = exp(-(norm(X(i,:)-X(j,:))^2)/(2*sigma^2));
end
end
%% 模型训练
C = 10;
if kernel_type == 0
[w_L,b_L,alphas_L,SVs_L] = smoSimple(X, y',C, 100, K_L,0,sigma) % 线性核_SMO算法求解alpha和b
else
[w_L,b_L,alphas_L,SVs_L] = smoSimple(X, y',C, 100, K_G,1,sigma) % 高斯核_SMO算法求解alpha和b
end
w_only = w_L;b_only = b_L; alphas_only = alphas_L;
%% TSVM模型构建
Cl=10;
Cu=0.1;
iter = 0;
[L_res,L_corrects,L_wrongs,accuracy_L,res_origin] = SVM_predict(alphas_L,b_L,X_unknown,y,X,y,kernel_type,sigma);
X_total = [X;X_unknown];
while Cu<Cl
iter = iter+1
ok_flag = 0;
K_L = zeros(size([y';L_res],1),size([y';L_res],1));
for i=1:size([y';L_res],1)
for j=1:size([y';L_res],1)
K_L(i,j) = X_total(i,:)*X_total(j,:)';
K_G(i,j) = exp(-(norm(X_total(i,:)-X_total(j,:))^2)/(2*sigma^2));
if kernel_type == 1
K_L(i,j) = K_G(i,j);
end
end
end
[w_L,b_L,alphas_L,SVs_L] = TSVMsmoSimple(X_total, [y';L_res],Cl,Cu,10, K_L,size(X,1),size(X_unknown,1),kernel_type,sigma);
while ok_flag ==0
for i = 1:size(X_unknown,1)-1
for j=i+1:size(X_unknown,1)
if kernel_type == 0
ksi_i = max(0,1-L_res(i)*(w_L*X_unknown(i,:)'+b_L)); %P127 (6.24)
ksi_j = max(0,1-L_res(j)*(w_L*X_unknown(j,:)'+b_L));
elseif kernel_type == 1
m = size(alphas_L,1);
temp1=0;temp2=0;
temp3 = [y';L_res];
for k=1:m
temp1 = temp1 + alphas_L(k)*temp3(k)*exp(-(norm(X_total(k,:)-X_unknown(i,:))^2)/(2*sigma^2));
temp2 = temp2 + alphas_L(k)*temp3(k)*exp(-(norm(X_total(k,:)-X_unknown(j,:))^2)/(2*sigma^2));
end
ksi_i = max(0,1-L_res(i)*(temp1+b_L)); %P127 (6.24)
ksi_j = max(0,1-L_res(j)*(temp2+b_L));
end
ok_flag = 1;
if ((L_res(i)*L_res(j))<0) && (ksi_i>0)&&(ksi_j>0)&&((ksi_i+ksi_j)>2)
L_res(i) = L_res(i)*(-1);
L_res(j) = L_res(j)*(-1);
ok_flag = 0;
break
end
end
if ok_flag == 0
break
end
end
if ok_flag == 0
[w_L,b_L,alphas_L,SVs_L] = TSVMsmoSimple(X_total, [y';L_res],Cl,Cu,10, K_L,size(X,1),size(X_unknown,1),kernel_type,sigma);
end
end
Cu = min(2*Cu,Cl)
end
result = [y';L_res];
%% 测试集检验
[test_res,test_corrects,test_wrongs,accuracy_test,~] = SVM_predict(alphas_L,b_L,X_test,y_test,X_total,result,kernel_type,sigma);
[testonly_res,testonly_corrects,testonly_wrongs,accuracy_testonly,~] = SVM_predict(alphas_only,b_only,X_test,y_test,X_total,result,kernel_type,sigma);
%% 结果绘制
accBound = 0.001; % 决定分类线的精度。值越小,分类线越精确,同时绘制速度越慢
L_idx = SVs_L';
figure(1);
title("训练集(10%+60%) 菱形为“1”样本,圆形为“-1”样本,实心为支持向量")
hold on
for i=1:size(result,1)
if result(i)==1
plot(X_total(i,1),X_total(i,2),'diamond r');
else
plot(X_total(i,1),X_total(i,2),'ob');
end
end
for i=1:size(L_idx,1)
j = L_idx(i);
if result(j)==1
plot(X_total(j,1),X_total(j,2),'diamond r','MarkerFaceColor','r');% 绘制"1"样本支持向量
else
plot(X_total(j,1),X_total(j,2),'ob','MarkerFaceColor','b');% 绘制"-1"样本支持向量
end
end
if kernel_type == 0
plotSVM(0, size(X_total,2), X_total, result, b_L, alphas_L, X_total(SVs_L,:), SVs_L, accBound,sigma,1)
else
plotSVM(1, size(X_total,2), X_total, result, b_L, alphas_L, X_total(SVs_L,:), SVs_L, accBound,sigma,1)
end
figure(2)
title("测试集分类结果(30%) TSVM")
hold on
for i=1:size(test_res,1)
if test_res(i)==1
plot(X_test(i,1),X_test(i,2),'diamond r');
else
plot(X_test(i,1),X_test(i,2),'ob');
end
if test_res(i) ~= y_test(i)
scatter(X_test(i,1),X_test(i,2),1,'MarkerEdgeColor','k','Marker','x','LineWidth',10);
end
end
figure(3)
title("测试集分类结果(30%) SVM")
hold on
for i=1:size(test_res,1)
if testonly_res(i)==1
plot(X_test(i,1),X_test(i,2),'diamond r');
else
plot(X_test(i,1),X_test(i,2),'ob');
end
if testonly_res(i) ~= y_test(i)
scatter(X_test(i,1),X_test(i,2),1,'MarkerEdgeColor','k','Marker','x','LineWidth',10);
end
end
%% SMO算法
function [w,b,alphas,SVs] = smoSimple(dataMat, labelMat, C,maxIter, K,kernel_type,sigma)
b = 0;
num = 0;
[N, D] = size(dataMat);
alphas = zeros(N, 1);
iter = 0;
kernalData = K;
w = zeros(1,size(dataMat,2));
while (iter < maxIter)
alphaPairsChanged = 0; % 记录alpha已经优化的数量
for i = 1: N
fXi = (alphas .* labelMat)' * kernalData(:, i) + b; % fXi为目前对xi的预测结果 (6.24)
Ei = fXi - labelMat(i); % Ei为使用alpha_i计算时的预测误差
% 接下来的if语句判断某条数据是否符合KKT条件
%if ((labelMat(i) * Ei < -toler) && (alphas(i) < C)) || ((labelMat(i) * Ei > toler) && (alphas(i) > 0))
if kernel_type == 0
ksi_i = max(0,1-labelMat(i)*(w*dataMat(i,:)'+b)); %P127 (6.24)
elseif kernel_type == 1
temp1=0;
for k=1:N
temp1 = temp1 + alphas(k)*labelMat(k)*exp(-(norm(dataMat(k,:)-dataMat(i,:))^2)/(2*sigma^2));
end
ksi_i = max(0,1-labelMat(i)*(temp1+b)); %P127 (6.24)
end
if ( ((alphas(i) >= 0) && (alphas(i) <= C))&& ((labelMat(i) * fXi-1+ksi_i >= 0) && (alphas(i)*(labelMat(i) * fXi-1+ksi_i) == 0)&&(ksi_i>=0)&&((C-alphas(i))*ksi_i==0))==0) %训练选取的alpha是不满足KKT条件的。因为满足KKT条件的alpha不需要被优化p125
% 若alpha可更改,则执行如下语句
% 选择与i所对应的样本距离最远的j 课本p125
distance = 0;
maxdist = 0;
for index=1:N
distance = dist(dataMat(i,:),dataMat(index,:)');
if distance>maxdist
maxdist = distance;
j = index;
end
end
% 使用选出来的alpha_j计算预测结果fXj
fXj = (alphas .* labelMat)' * kernalData(:, j) + b;
Ej = fXj - labelMat(j); % Ej为使用alpha_j计算时的预测误差
alphaIold = alphas(i);
alphaJold = alphas(j);
% 计算alpha_j的上下界
if labelMat(i) ~= labelMat(j)
L = max(0, alphas(j) - alphas(i));
H = min(C, C + alphas(j) - alphas(i));
else
L = max(0, alphas(j) + alphas(i) - C);
H = min(C, alphas(j) + alphas(i));
end
if L == H
continue;
end
eta = 2.0 * kernalData(i, j) - kernalData(i, i) - kernalData(j, j);
if eta >= 0
fprintf("eta >= 0\n");
continue;
end
alphas(j) = alphas(j) - labelMat(j) * (Ei - Ej) / eta;
alphas(j) = clipAlpha(alphas(j), H, L); % 越界的alpha被强制赋值
if (abs(alphas(j) - alphaJold) < 0.00001)% 迭代求解终止条件
continue;
end
% 至此,alpha_j计算完成
% 根据alpha_i和alpha_j的关系式,计算alpha_i
alphas(i) = alphaIold + labelMat(j) * labelMat(i) * (alphaJold - alphas(j));
% 计算分类超平面的偏置
b1 = b - Ei - labelMat(i) * (alphas(i) - alphaIold) * kernalData(i, i) - ...
labelMat(j) * (alphas(j) - alphaJold) * kernalData(i, j);
b2 = b - Ej - labelMat(i) * (alphas(i) - alphaIold) * kernalData(i, j) - ...
labelMat(j) * (alphas(j) - alphaJold) * kernalData(j, j);
if (0 < alphas(i)) && (C > alphas(i))
b = b1;
elseif (0 < alphas(j)) && (C > alphas(j))
b = b2;
else
b = (b1 + b2) / 2;
end
alphaPairsChanged = alphaPairsChanged + 1;
end
end
if alphaPairsChanged == 0
iter = iter + 1;
else
iter = 0;
end
end
w = zeros(1,size(dataMat,2));
num = 0;
SVs=zeros(1,1);
for i = 1:N
w = w +alphas(i)*labelMat(i)*dataMat(i,:);
if alphas(i)>0
num = num +1;
SVs(num)=i;
end
end
end
%% 第一版SMO算法-KKT约束条件与课本不符,废弃不用
function [w,b,alphas,SVs] = sssssmoSimple(dataMat, labelMat, C,maxIter, K)
b = 0;
num = 0;
[N, D] = size(dataMat);
alphas = zeros(N, 1);
iter = 0;
kernalData = K;
while (iter < maxIter)
alphaPairsChanged = 0; % 记录alpha已经优化的数量
for i = 1: N
fXi = (alphas .* labelMat)' * kernalData(:, i) + b; % fXi为目前对xi的预测结果 (6.24)
Ei = fXi - labelMat(i); % Ei为使用alpha_i计算时的预测误差
% 接下来的if语句判断某条数据是否符合KKT条件
%if ((labelMat(i) * Ei < -toler) && (alphas(i) < C)) || ((labelMat(i) * Ei > toler) && (alphas(i) > 0))
if ( ((alphas(i) >= 0) && (alphas(i) <= C))&& ((labelMat(i) * fXi-1 >= 0) && (alphas(i)*(labelMat(i) * fXi-1) == 0))==0) %训练选取的alpha是不满足KKT条件的。因为满足KKT条件的alpha不需要被优化p125
% 若alpha可更改,则执行如下语句
% 选择与i所对应的样本距离最远的j 课本p125
distance = 0;
maxdist = 0;
for index=1:N
distance = dist(dataMat(i,:),dataMat(index,:)');
if distance>maxdist
maxdist = distance;
j = index;
end
end
% 使用选出来的alpha_j计算预测结果fXj
fXj = (alphas .* labelMat)' * kernalData(:, j) + b;
Ej = fXj - labelMat(j); % Ej为使用alpha_j计算时的预测误差
alphaIold = alphas(i);
alphaJold = alphas(j);
% 计算alpha_j的上下界
if labelMat(i) ~= labelMat(j)
L = max(0, alphas(j) - alphas(i));
H = min(C, C + alphas(j) - alphas(i));
else
L = max(0, alphas(j) + alphas(i) - C);
H = min(C, alphas(j) + alphas(i));
end
if L == H
continue;
end
eta = 2.0 * kernalData(i, j) - kernalData(i, i) - kernalData(j, j);
if eta >= 0
fprintf("eta >= 0\n");
continue;
end
alphas(j) = alphas(j) - labelMat(j) * (Ei - Ej) / eta;
alphas(j) = clipAlpha(alphas(j), H, L); % 越界的alpha被强制赋值
if (abs(alphas(j) - alphaJold) < 0.00001)% 迭代求解终止条件
continue;
end
% 至此,alpha_j计算完成
% 根据alpha_i和alpha_j的关系式,计算alpha_i
alphas(i) = alphaIold + labelMat(j) * labelMat(i) * (alphaJold - alphas(j));
% 计算分类超平面的偏置
b1 = b - Ei - labelMat(i) * (alphas(i) - alphaIold) * kernalData(i, i) - ...
labelMat(j) * (alphas(j) - alphaJold) * kernalData(i, j);
b2 = b - Ej - labelMat(i) * (alphas(i) - alphaIold) * kernalData(i, j) - ...
labelMat(j) * (alphas(j) - alphaJold) * kernalData(j, j);
if (0 < alphas(i)) && (C > alphas(i))
b = b1;
elseif (0 < alphas(j)) && (C > alphas(j))
b = b2;
else
b = (b1 + b2) / 2;
end
alphaPairsChanged = alphaPairsChanged + 1;
end
end
if alphaPairsChanged == 0
iter = iter + 1;
else
iter = 0;
end
end
w = zeros(1,size(dataMat,2));
for i = 1:N
w = w +alphas(i)*labelMat(i)*dataMat(i,:);
if alphas(i)>0
num = num +1;
SVs(num)=i;
end
end
end
%% TSVM-SMO算法
function [w,b,alphas,SVs] = TSVMsmoSimple(dataMat, labelMat, Cl,Cu,maxIter, K,num_known,num_unknown,kernel_type,sigma)
b = 0;
num = 0;
[N, D] = size(dataMat);
alphas = zeros(N, 1);
iter = 0;
kernalData = K;
w = zeros(1,size(dataMat,2));
while (iter < maxIter)
alphaPairsChanged = 0; % 记录alpha已经优化的数量
for i = 1: N
if i<=num_known
Ci = Cl;
else
Ci = Cu;
end
fXi = (alphas .* labelMat)' * kernalData(:, i) + b; % fXi为目前对xi的预测结果 (6.24)
Ei = fXi - labelMat(i); % Ei为使用alpha_i计算时的预测误差
% 接下来的if语句判断某条数据是否符合KKT条件
%if ((labelMat(i) * Ei < -toler) && (alphas(i) < C)) || ((labelMat(i) * Ei > toler) && (alphas(i) > 0))
if kernel_type == 0
ksi_i = max(0,1-labelMat(i)*(w*dataMat(i,:)'+b)); %P127 (6.24)
elseif kernel_type == 1
temp1=0;
for k=1:N
temp1 = temp1 + alphas(k)*labelMat(k)*exp(-(norm(dataMat(k,:)-dataMat(i,:))^2)/(2*sigma^2));
end
ksi_i = max(0,1-labelMat(i)*(temp1+b)); %P127 (6.24)
end
if ( ((alphas(i) >= 0) && (alphas(i) <= Ci))&& ((labelMat(i) * fXi-1+ksi_i >= 0) && (alphas(i)*(labelMat(i) * fXi-1+ksi_i) == 0)&&(ksi_i>=0)&&((Ci-alphas(i))*ksi_i==0))==0) %训练选取的alpha是不满足KKT条件的。因为满足KKT条件的alpha不需要被优化p125
%if ( ((alphas(i) >= 0) && (alphas(i) <= Ci))&& ((labelMat(i) * fXi-1 >= 0) && (alphas(i)*(labelMat(i) * fXi-1) == 0))==0) %训练选取的alpha是不满足KKT条件的。因为满足KKT条件的alpha不需要被优化p125
% 若alpha可更改,则执行如下语句
% 选择与i所对应的样本距离最远的j 课本p125
distance = 0;
maxdist = 0;
for index=1:N
distance = dist(dataMat(i,:),dataMat(index,:)');
if distance>maxdist
maxdist = distance;
j = index;
end
end
if j<=num_known
Cj = Cl;
else
Cj = Cu;
end
% 使用选出来的alpha_j计算预测结果fXj
fXj = (alphas .* labelMat)' * kernalData(:, j) + b;
Ej = fXj - labelMat(j); % Ej为使用alpha_j计算时的预测误差
alphaIold = alphas(i);
alphaJold = alphas(j);
% 计算alpha_j的上下界
if labelMat(i) ~= labelMat(j) %假若Ci和Cj不相等,那么上下限与普通SVM不同
L = max(0, alphas(j) - alphas(i));
H = min(Cj, Ci + alphas(j) - alphas(i));
else
L = max(0, alphas(j) + alphas(i) - Ci);
H = min(Cj, alphas(j) + alphas(i));
end
if L == H
continue;
end
eta = 2.0 * kernalData(i, j) - kernalData(i, i) - kernalData(j, j);
if eta >= 0
%fprintf("eta >= 0\n");
continue;
end
alphas(j) = alphas(j) - labelMat(j) * (Ei - Ej) / eta;
alphas(j) = clipAlpha(alphas(j), H, L); % 越界的alpha被强制赋值
if (abs(alphas(j) - alphaJold) < 0.00001)% 迭代求解终止条件
continue;
end
% 至此,alpha_j计算完成
% 根据alpha_i和alpha_j的关系式,计算alpha_i
alphas(i) = alphaIold + labelMat(j) * labelMat(i) * (alphaJold - alphas(j));
% 计算分类超平面的偏置
b1 = b - Ei - labelMat(i) * (alphas(i) - alphaIold) * kernalData(i, i) - ...
labelMat(j) * (alphas(j) - alphaJold) * kernalData(i, j);
b2 = b - Ej - labelMat(i) * (alphas(i) - alphaIold) * kernalData(i, j) - ...
labelMat(j) * (alphas(j) - alphaJold) * kernalData(j, j);
if (0 < alphas(i)) && (Ci > alphas(i))
b = b1;
elseif (0 < alphas(j)) && (Cj > alphas(j))
b = b2;
else
b = (b1 + b2) / 2;
end
alphaPairsChanged = alphaPairsChanged + 1;
end
end
if alphaPairsChanged == 0
iter = iter + 1;
else
iter = 0;
end
end
w = zeros(1,size(dataMat,2));
SVs=zeros(1,1);
for i = 1:N
w = w +alphas(i)*labelMat(i)*dataMat(i,:);
if alphas(i)>0
num = num +1;
SVs(num)=i;
end
end
end
%% 预测函数
function [lists,corrects,wrongs,accuracy,res] = SVM_predict(alphas,b,x_pre,y_pre,X_data,label,Kernel,sigma)
m = size(alphas,1);
n = size(x_pre,1);
res = zeros(n,1);
for j=1:n % 软间隔支持向量机
for i=1:m
if Kernel == 0
res(j) = res(j) + alphas(i)*label(i)*x_pre(j,:)*X_data(i,:)';
elseif Kernel == 1
res(j) = res(j) + alphas(i)*label(i)*exp(-(norm(x_pre(j,:)-X_data(i,:))^2)/(2*sigma^2));
end
end
res(j) = res(j) + b;
end
lists = zeros(n,1);
cn=0;wn=0;
accuracy = 0;
corrects = zeros(n,1);
wrongs = zeros(n,1);
try
for i = 1:n
if res(i)>0
lists(i) = 1;
else
lists(i) = -1;
end
if lists(i) == y_pre(i)
cn = cn+1;
corrects(cn)=i;
else
wn = wn + 1;
wrongs(wn) = i;
end
end
catch
end
accuracy = cn/(cn+wn); % 计算准确率
end
%% 绘图函数
function plotSVM(Kernel_Method, D, dataMat, labelMat, b, alphas, supportVectors, supportVectorsIndices, accBound,sigma,index)
if D == 2
% 分类线位于所有预测值为0的数据点位置上。
% 1、对屏幕空间的矩形范围(至少包含所有训练数据点)内的所有坐标点进行预测
% 点与点的间隔越小,分类边界线越精确
% 2、画出预测值为0的点
% 3、将所有标出的点连起来,构成高维分类超平面在二维上的投影边界
% 第2和第3步可以用contour函数直接实现
% 构建屏幕空间坐标集合screenCorMat,第一页为X坐标,第二页为Y坐标
screenCorX = min(dataMat(:, 1)): accBound: max(dataMat(:, 1));
screenCorY = min(dataMat(:, 2)): accBound: max(dataMat(:, 2));
M = length(screenCorY);
N = length(screenCorX);
screenCorX = repmat(screenCorX, [M , 1]);
screenCorY = repmat(screenCorY',[1, N]);
screenCorMat = cat(3, screenCorX, screenCorY);
% 平铺屏幕空间所有点,便于预测
screenCorMat = reshape(screenCorMat, [M * N, 2]);
% 对屏幕空间所有点进行预测,得到预测结果矩阵predictCor
for i = 1: N
[~,~,~,~,predictCor(:,i)] = SVM_predict(alphas,b,[screenCorX(:,i),screenCorY(:,1)],dataMat,labelMat,Kernel_Method,sigma);
%predictCor(i) = kernelCor(:, i)' * (labelMat(supportVectorsIndices) .* alphas(supportVectorsIndices)) + b;
end
%predictCor = reshape(predictCor, [M, N]);
% 绘制预测结果为0的所有点,连起来,构成分类边界线
figure(index), contour(screenCorX, screenCorY, predictCor, [0, 0], 'k:','ShowText','on'); hold on;
hold on;
% 圈出所有支持向量
%figure(index), scatter(supportVectors(:, 1), supportVectors(:, 2), 100, 'k'); hold on;
% 绘制出边界点所在曲线
figure(index), contour(screenCorX, screenCorY, predictCor, [1 1], 'r:','ShowText','on'); hold on;
figure(index), contour(screenCorX, screenCorY, predictCor, [-1 -1], 'r:','ShowText','on');
else
fprintf('数据维数高于2维,无法绘图\n');
end
end
%% 在1到m之间随机选取一个整数j
function j = selectJrand(i, m)
j = i;
while (j == i)
j = randperm(m, 1);
end
end
%% 调整大于H或小于L的alpha,即掐头去尾
function aj = clipAlpha(aj, H, L)
% 令大于H的alpha等于H
if aj > H
aj = H;
end
% 令小于L的alpha等于L
if aj < L
aj = L;
end
end葡萄酒数据集的实现方法就不给出了,在报告里有。
欢迎大家关注我的微信公众号:不断努力的霜木君















 1673
1673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









