





环境
1. Scrapy
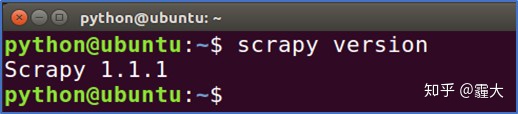
在Ubuntu安装Scrapy的步骤为:打开终端 >> 在终端输入命令:pip install scrapy >> 在终端输入命令:scrapy version >> 成功输出 Scrapy版本号则证明成功安装。
2. Redis(Ubuntu)
打开终端 >> 在终端输入命令:pip install redis
>> 在终端输入命令:sudo subl redis.conf(以管理员权限用sublime text3(可用 其他编辑器)编辑redis.conf文件)
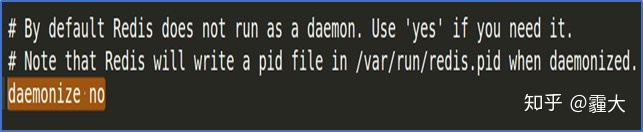
>> 将redis.conf中的daemonize设置为daemonize no使得启动redis-server时可以明显看出redis- server已启动
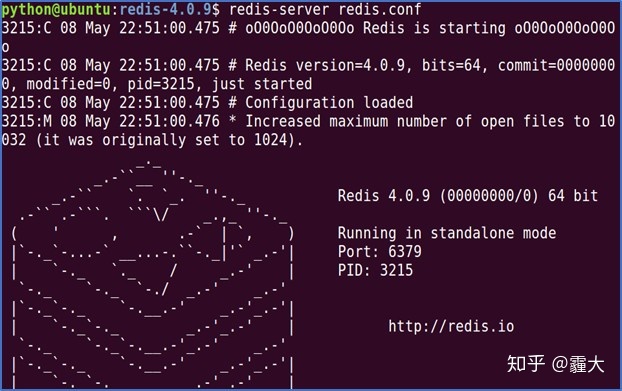
>> 在终端输入命令:redis-server redis.conf(以redis.conf为配置文件启动redis-server) >> 成功则显示redis- server启动界面。
3. Redis(Win10)
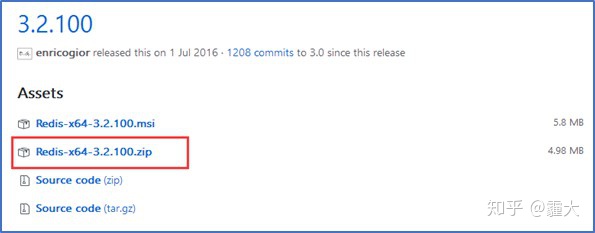
打开浏览器 >> 输入以下网址“https://github.com/MicrosoftArchive/redis/releases” 下载Redis的zip压缩包
>> 本文下载的 是Redis-x64-3.2.100.zip>>将下载好的zip文件直接解压即可使用
>> 配置Redis-x64-3.2.100文件夹下的redis.windows.conf文 件使得redis-server不作为守护进程使用>>修改redis.windows.conf中的daemonize为daemonize no
>> 在Redis-x64-3.2.100目 录下启动“cmd”
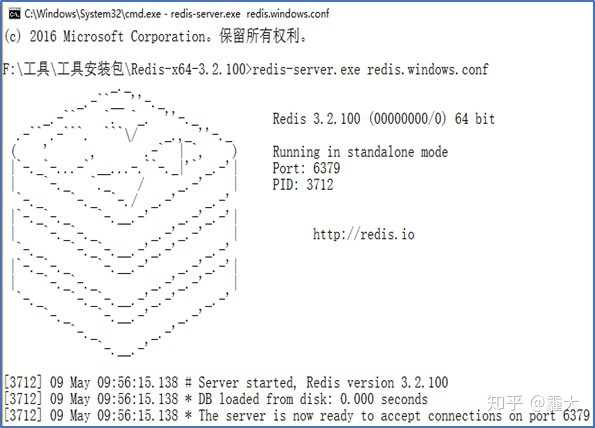
>> 在cmd中输入“redis-server.exe redis.windows.conf”(以redis.windows.conf为配置文件启动redis- server)
>> 启动成功。

4. Redis Desktop Manager(Win10)
打开浏览器 >> 输入以下网址“https://redisdesktop.com/download” 下载Redis Desktop Manager的exe文件
>> 本文下载的是 Redis Desktop Manager的Windows版本
>> 将下载好的exe文件直接安装运行
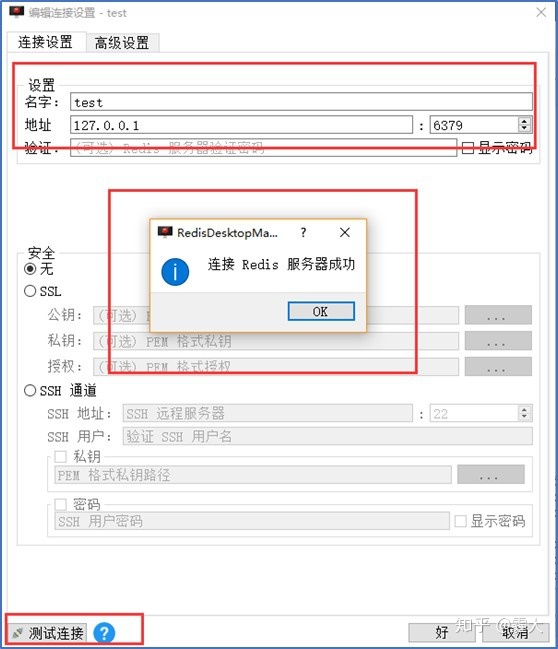
>> 启动Redis Desktop Manager,设置其与本地Redis 数据库相连接(Master端在Windows下)
>> 测试连接情况。
5. MongoDB
打开终端 >> 输入命令:sudo apt-get install mongodb
>> 再在终端输入命令:mongo –version,安装成功则输出MongoDB版本号

6. Robo 3T
为了方便管理MongoDB,我们安装了Robo 3T。Robo 3T是一个MongoDB的可视化工具。
安装步骤如下:打开浏览器 >> 在浏览器输入以下 网址“https://robomongo.org
>> 选择相应的Robo 3T版本进行下载
>> 将下载好的压缩包进行解压即可直接使用
>> 在终端输入: robo3t --version,查看Robo 3T版本号
>> 启动Robo 3T,配置连接到本地MongoDB

-------------------------------------------------------------------------------
各模块作用
1. items
爬虫抓取数据的工作实际上是从非结构化数据(网页)中提取出结构化数据。虽然Scrapy框架爬虫可以将提取到的数据以Python字典 的形式返回,但是由于Python字典缺少结构,所以很容易发生返回数据不一致亦或者名称拼写的错误,若是Scrapy爬虫项目中包含复 数以上的爬虫则发生错误的机率将更大。因此,Scrapy框架提供了一个items模块来定义公共的输出格式,其中的Item对象是一个用于 收集Scrapy爬取的数据的简单容器。
2. Downloader Middleware
Downloader Middleware是一个Scrapy能全局处理Response和Request的、微型的系统。Downloader Middleware中定义的Downloader Middleware设有优先级顺序,优先级数字越低,则优先级越高,越先执行。在本次分布式爬虫中,我们定义了两个Downloader Middleware,一个用于随机选择爬虫程序执行时的User-Agent,一个用于随机选择爬虫程序执行时的IP地址。
3. settings
settings模块用于用户自定义Scrapy框架中Pipeline、Middleware、Spider等所有组件的所有动作,且可自定义变量或者日志动作。
-------------------------------------------------------------------------------
测试
Master端为Win10物理机,Slave端为两个相同配置的Ubuntu虚拟机
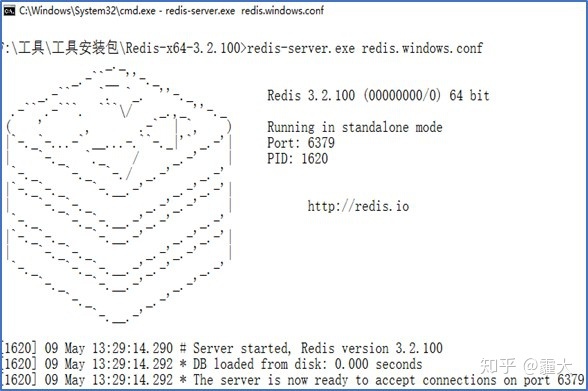
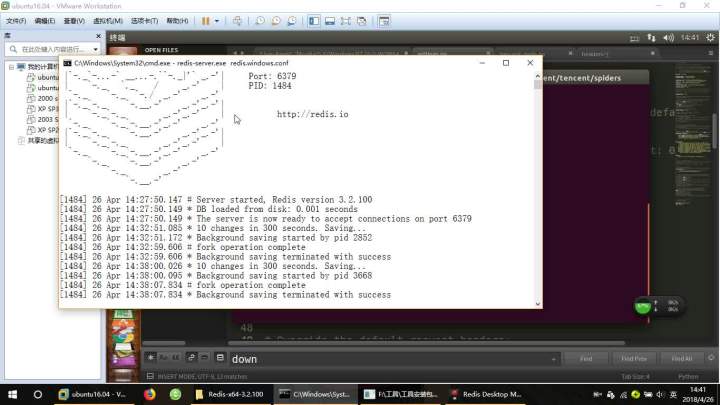
1. 启动Master端的redis-server
启动成功如图,可以看出redis-server的运行端口为6379,版本号为3.2.100
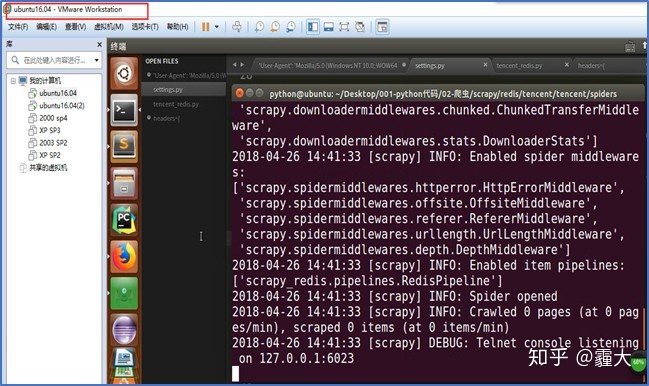
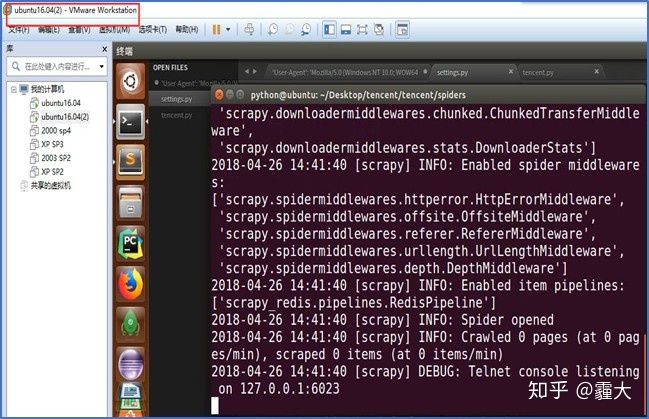
2. 启动两个Slave端的爬虫程序
启动两个Slave端的爬虫程序,使其进入等待状态,等待Master端对其分配请求,此时爬虫程序 已启动中间件和管道功能,并紧随其后启动爬虫功能,由于刚启动爬虫,此时爬取的网页数为0。
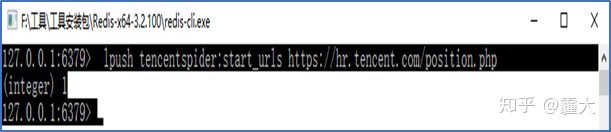
3. 向Master端添加第一个URL请求
在物理PC机启动redis-cli客户端,往redis-server服务器端压入第一个URL请求
“lpush tencentspider:start_urls https://hr.tencent.com/position.php”
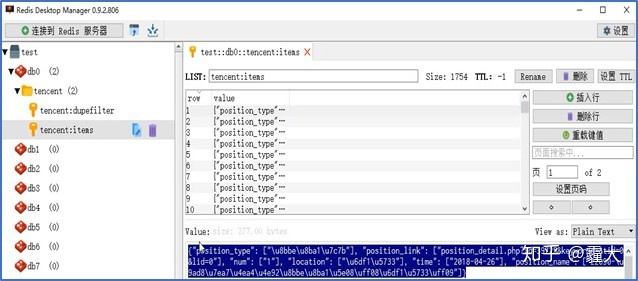
4.数据展示(Redis)及验证
两个Slave端爬取完数据后,数据存储在Master端的Redis数据库。
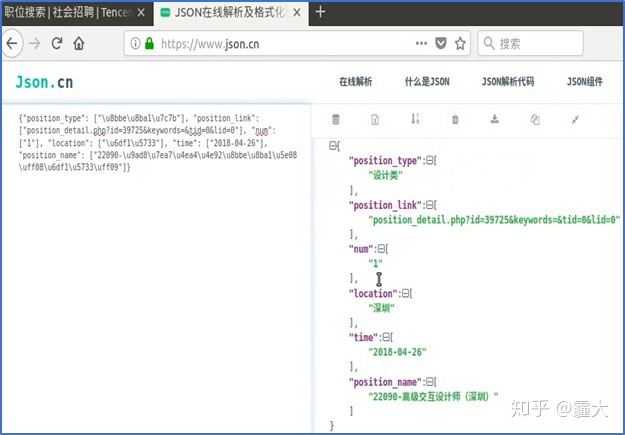
将Redis Desktop Manager中的Value值放入“https://www.json.cn/” 网站中查看,与被爬取网站作对比,发现信息一致,爬虫成功。
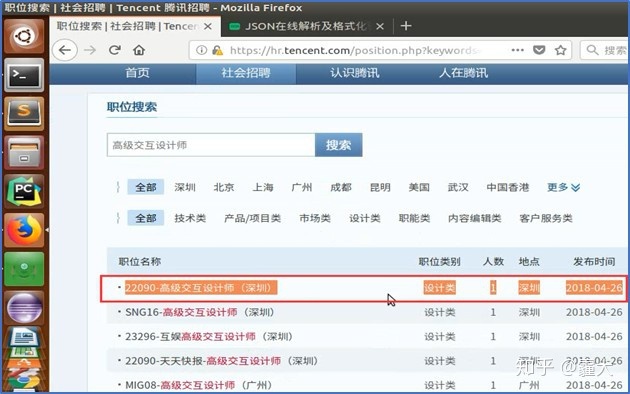
5.数据展示(MongoDB)
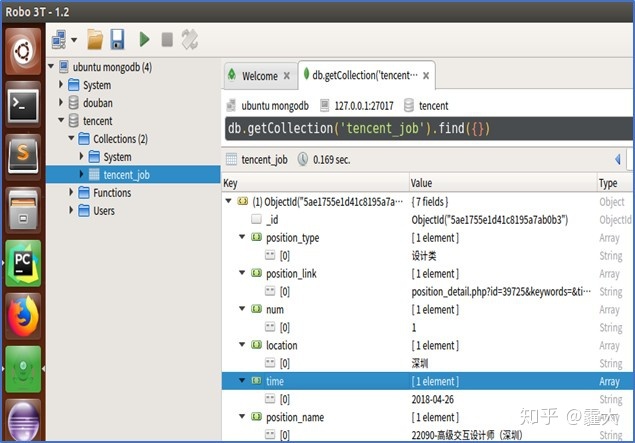
在本次分布式爬虫的最后,我们将爬取到的数据从Redis数据库转存入本地MongoDB数据库(save_2_mongodb.py)。
-------------------------------------------------------------------------------
运行视频:
-------------------------------------------------------------------------------
源码
LZC6244/Pythongithub.com















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









