






 本文探讨了层次聚类方法的局限性,特别是终止条件选择的困难和不具伸缩性的特点。通过对比试验,DNMC算法在Wine和Iris数据集上表现出优于M-Chameleon的聚类效果,降低了时间开销并解决了不可逆的合并或分裂问题。未来工作将研究在高维数据中的应用。
本文探讨了层次聚类方法的局限性,特别是终止条件选择的困难和不具伸缩性的特点。通过对比试验,DNMC算法在Wine和Iris数据集上表现出优于M-Chameleon的聚类效果,降低了时间开销并解决了不可逆的合并或分裂问题。未来工作将研究在高维数据中的应用。
层次聚类方法存在的不足
在凝聚的层次聚类方法和分裂的层次聚类方法中,均需要用户指定所期望得到的聚类个数和阈值作为聚类过程的终止条件,但是对于复杂的数据来说这是很难事先判定的。层次聚类方法尽管简单,但经常会遇到合并或分裂点选择的困难。这样的决定是非常关键的,因为一旦一组对象被合并或者分裂,下一步的处理将在新生成簇的基础上进行。已做的处理不能被撤消,聚类之间也不能交换对象。如果在某一步没有很好地做出合并或分裂的决定,可能会导致低质量的聚类结果。而且,这种聚类方法不具有很好的可伸缩性,因为合并或分裂的决定需要检查和估算大量的对象或簇。 层次聚类算法由于要使用距离矩阵,所以它的时间和空间复杂性都为O(n2) ,几乎不能在较大的数据集上使用。层次聚类算法只处理符合某静态模型的簇,忽略了不同簇间的信息而且忽略了簇间的互连性(互连性指的是簇间距离较近数据对的多少)和近似性(近似性指的是簇间数据对的相似度)。
试验结果与分析
1 试验结果
本文选取的是 UCI 数据库中的Wine和Iris两组数据集。其中 Wine 包含 178个样本,13 个数值型属性,分成 3 个类,每个类分别有 59, 71, 48 个记录;Iris数据集有 150 条记录,数据集是四维的,分为 3 类,每一类有 50 个记录。在试验中我们对 DNMC 与传统的 M-Chameleon 算法进行了详细的比较,以下实验结果均在Matlab 软件平台上编程实现,试验结果如表 1 和表2 所示。
表1 Wine数据集的测试结果
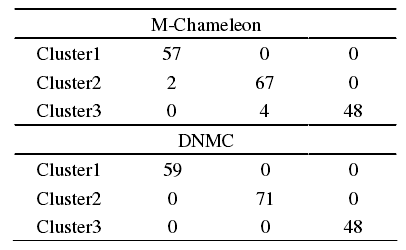
表2
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1783
1783











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









