





之前转载过他人对于Batch Size对训练的影响的研究。但是其实描述的还不是很完善,最近刚好有空,写一篇我在深度学习过程中Batch Size对训练过程的影响。
安小飞:深度学习 | Batch Size大小对训练过程的影响zhuanlan.zhihu.com在实际深度学习项目中,一般有三种抽取数据的方式,第一种是取全量的数据进行梯度的更新;第二种是取1条样本进行每次迭代更新,即在线学习batch size=1;第三种是取部分样本数据也就是mini batch size进行梯度更新。三种方式对梯度更新也很容易想到,第一种因为是全量数据,所以梯度总能朝正确的方向进行下降;第二种为one by one,梯度的游走路径波动显然会很大;第三种是一种折中的方式,而我们需要做的就是找到第三种方式最优值。
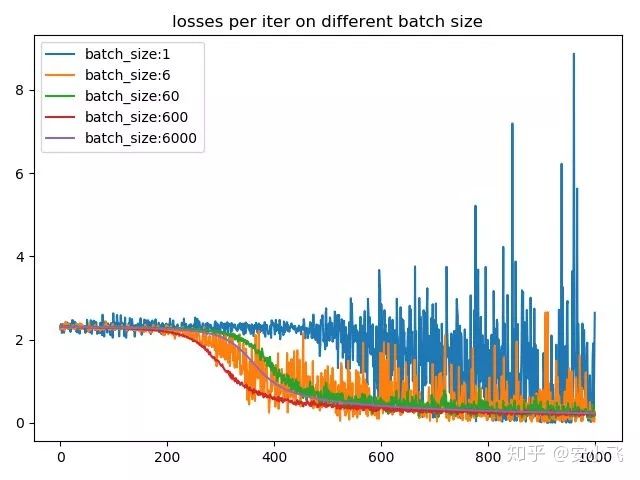
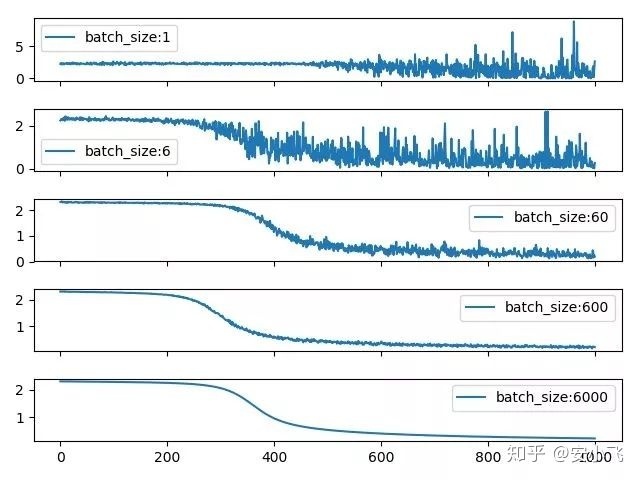
所以我们要明白Batch Size到底影响的是什么?显而易见的是它会影响目标函数的收敛速度,一般来说,增大Batch_Size,所带来的训练时的标准差并不是线性增长的,比如训练一个样本的标准差为σ,那么取Batch_Size=n所带来的标准差为
另一方面,Batch Size也会影响目标函数的最优解,我们知道训练目标是网络最终收敛的时候得到目标函数的最优解,而在实际的训练过程中我们并不总是能找到绝对最小值区域,很多时候是陷入了局部最优解。这时候,如果将Batch Size调整的较小,其每次的迭代下降方向就不是最准确的,loss小范围震荡下降反而会跳出局部最优解,从而寻找loss更低的区域。还有一种说法是,何凯明的论文Rethinking ImageNet pre-training【1】提到过,如果你的网络中使用了BN层的话,而BN层的计算在batch size较小时受batch size参数影响较大,batch size越小,参数的统计信息越不可靠,也会影响最终的效果。因此调小Batch_size可以有效防止陷入局部最小值,但是由于BN层的存在也会影响最终的效果,同时Batch_size调得过小也容易导致网络不收敛。所以在实际跑代码的过程中你就会发现,调Batch_size是个很玄学的过程。
这时候在看两个问题?
(1)深度学习中batch size的大小对训练过程的影响是什么样的?
详细以上的内容已经给出了答案。
(2)有些时候不可避免地要用超大batch,比如人脸识别,可能每个batch要有几万甚至几十万张人脸图像,训练过程中超大batch有什么优缺点,如何尽可能地避免超大batch带来的负面影响?
在不考虑Batch Normalization的情况下(这种情况我们之后会在bn的文章里专门探讨),先给个自己当时回答的答案吧(相对来说学究一点):
(1) 不考虑bn的情况下,batch size的大小决定了深度学习训练过程中的完成每个epoch所需的时间和每次迭代(iteration)之间梯度的平滑程度。batch size只能说影响完成每个epoch所需要的时间,决定也算不上吧。根本原因还是CPU,GPU算力吧。瓶颈如果在CPU,例如随机数据增强,batch size越大有时候计算的越慢。
对于一个大小为N的训练集,如果每个epoch中mini-batch的采样方法采用最常规的N个样本每个都采样一次,设mini-batch大小为b,那么每个epoch所需的迭代次数(正向+反向)为 , 因此完成每个epoch所需的时间大致也随着迭代次数的增加而增加。
由于目前主流深度学习框架处理mini-batch的反向传播时,默认都是先将每个mini-batch中每个instance得到的loss平均化之后再反求梯度,也就是说每次反向传播的梯度是对mini-batch中每个instance的梯度平均之后的结果,所以b的大小决定了相邻迭代之间的梯度平滑程度,b太小,相邻mini-batch间的差异相对过大,那么相邻两次迭代的梯度震荡情况会比较严重,不利于收敛;b越大,相邻mini-batch间的差异相对越小,虽然梯度震荡情况会比较小,一定程度上利于模型收敛,但如果b极端大,相邻mini-batch间的差异过小,相邻两个mini-batch的梯度没有区别了,整个训练过程就是沿着一个方向蹭蹭蹭往下走,很容易陷入到局部最小值出不来。
总结下来:batch size过小,花费时间多,同时梯度震荡严重,不利于收敛;batch size过大,不同batch的梯度方向没有任何变化,容易陷入局部极小值。
参考链接:
训练神经网络时如何确定batch的大小?mp.weixin.qq.com
【1】He K , Girshick R , Dollár, Piotr. Rethinking ImageNet Pre-training[J]. 2018.















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









