





Pandas是一个用于数据分析的开源Python库。强大的结构化数据分析功能(依赖于Numpy),提供多种高级数据结构:Series、Data Frame、Panel,强大的数据索引和处理能力,它让Python能处理电子表格等数据。提供了数据快速加载、操作、对齐与合并等功能。Data Frame表示整个电子表格或矩形数据,而Series是Data Frame的单列。Data Frame可以看作是由Series对象组成的字典或集合。
数据集加载
当给定一个数据集,首先要加载它并查看其结构内容。查看数据集最简单方法是检查特定的行和列,并对它们取子集。查看每列中存储信息的类型,并通过聚合描述性统计来发现模式,与使用Excel的方式其实一样。
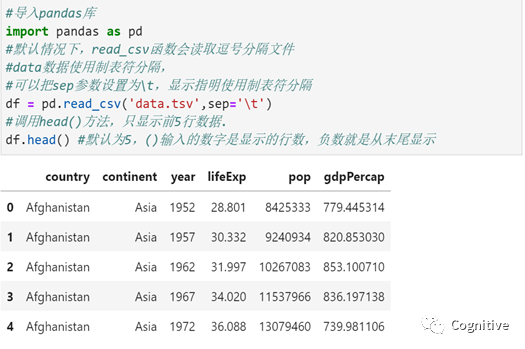
Pandas并不是Python标准库的一部分,所以在使用之前需要先导入,如示:

导入Pandas库后,就可以调用read_csv函数来加载CSV数据文件,调用Pandas的read_csv函数时要用点表示法。详细参阅《数据分析之pandas库运用(1)》、《数据分析之pandas库运用.(5)》、《数据分析之pandas库运用.(6)》。
检查read_csv读取返回的是否为Data Frame,使用Python内置的type函数(该函数是python的内置函数,不属于Pandas或任何包)

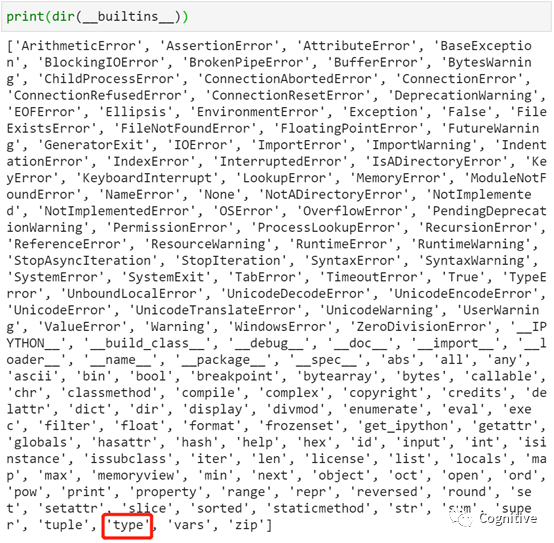
处理多个Python对象,并且想知道当前处理的是哪个对象时,type函数会非常有用,至于是否加print(),建议保持正确的编程习惯,是非常有必要的。
加载的数据集被保存为Pandas DataFrame对象,每一个Data Frame对象都有一个shape属性,用来指明Data Frame的行数和列数,如同使用Excel一样的行数和列数。

Shape属性返回一个元组(参阅《数据分析之pandas库运用(3)》,其中第一个值是行数,第二值是列数。结果显示data数据集有1704行,6列。
前面查看数据集保存的对象,数据集有多少行,多少列,为了获取数据集中的信息要点,需查看数据集的列,可用Data Frame的columns属性来得到列名。

Pandas的Data Frame对象,每列的类型必须相同,而每行而已包含混合类型。使用Data Frame的dtypes属性或info方法来查看
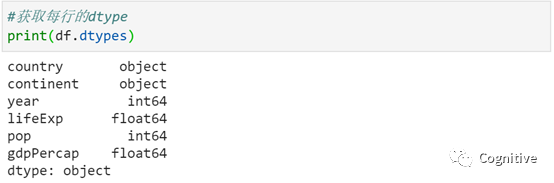
print(df.dtypes)输出的是country、continent列为object类型,year、pop例为int64类型,lifeExp、gdpPercap列为float64。
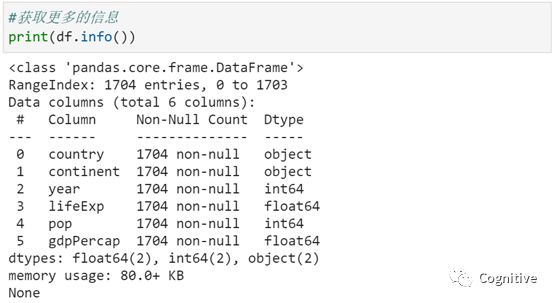
print(df.info())输出的是read_csv读取返回为DataFrame,index:1704行,从0到1703,数据列共有6列,并分别告诉每一列的有1704非空值,以及对应的类型,以及统计不同类型有几个,内存使用量是80.0+KB

相关阅读:
数据分析之pandas库运用.(1)
数据分析之pandas库运用.(3)
数据分析之pandas库运用.(5)
数据分析之pandas库运用.(6)















 518
518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









