





想找一份Python开发类工作,可以在BOSS直聘网上查找,薪酬在15-40k之间比比皆是。这种垂直类渠道网站比较有针对性,可以很快找到目标岗位的职位,分类也比较细。
我们的目标:抓取“Python”的职位薪酬,并保存到CSV文件中。每页30条记录,共计10页。
最终效果:以CSV方式保存职位薪酬职位信息。
技术点:CSV文件写入、Selenium库的使用、XPath的使用等。
代码编写方式:采用函数、面向过程方式编写。
接下来我们一起进行代码编写,通过5步搞定这个爬取。
1.导入相关库
import time
import csv
from selenium import webdriver
from lxml import etree
import random
2.计算总的页数
由于网站没有提供总页数,我们只能依靠点击下一页链接来爬取数据,直到下一页链接不可用。当页面中下一页可以点击时,超链接标签如图所示。当页面中下一页不能点击时,超链接标签如图所示。
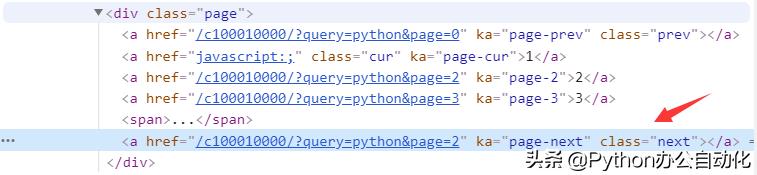
图中下一页链接可以点击
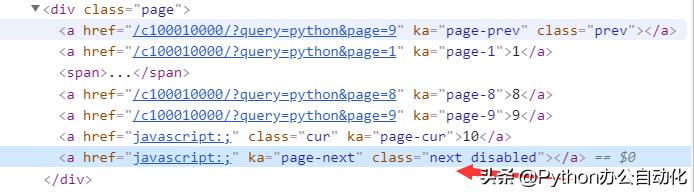
代码中判断如下,如果找不到下一页的页面元素标志,认为到了最后一页。
try:
next_page_tag = driver.find_element_by_xpath("//a[@class='next']")
next_page_tag.click()
flag = True
time.sleep(3)
except:
#find_element_by_xpath找不到元素,会引发异常
flag = False
print("如果没有找到,这里可以认为到了最后一页")
3.匹配出职位列表标签
谷歌浏览器打开网站https://www.zhipin.com/c100010000/?query=python&page=1&ka=page-1。右键点击一个职位标题,选择检查链接,打开界面如图所示。
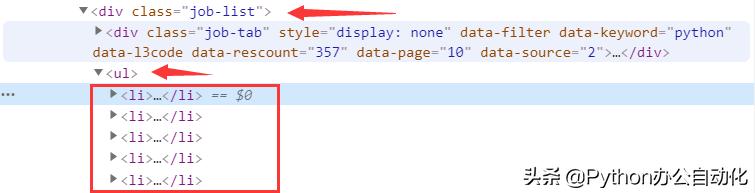
获取职位列表的关键代码如下。
html = etree.HTML(page_source)
info_links = html.xpath("//div[@class='job-list']/ul/li")
print(info_links)
for link in info_links:
name = link.xpath(".//span[@class='job-name']/a/text()") # 名称
print(name)
4.全部代码
源代码见selenium_boss.py,大约只有80行代码,请读者反复测试。
# coding:utf_8_sig
import time
import csv
from selenium import webdriver
from lxml import etree
import random
import os
cur_path=os.path.dirname(__file__)
filename=os.path.join(cur_path,'chromedriver_win32_83.0.4103.39', "chromedriver.exe")
# 创建EXCEL文件地址
csv_filename =os.path.join(cur_path,'51boss.csv')
all_lists = []
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"
options = webdriver.ChromeOptions()
options.add_argument('--ignore-certificate-errors')
options.add_argument('--ignore-ssl-errors')
options.add_argument(f'--user-agent={user_agent}')
driver = webdriver.Chrome(filename, chrome_options=options)
url = "https://www.zhipin.com/job_detail/?query=python&city=101020100&industry=&position="
driver.get(url)
time.sleep(5)
def crawl():
flag = True
while flag:
page = driver.page_source
# 解析保存csv
parse_html(page)
# 随机几秒,看起来正常爬取。
rand_seconds = random.choice([2, 3])+random.random()
time.sleep(rand_seconds)
# 爬取当前页, 点击下一页进行抓取
try:
next_page_tag=driver.find_element_by_xpath("//a[@class='next']")
next_page_tag.click()
flag = True
time.sleep(3)
except:
#find_element_by_xpath找不到元素,会引发异常
flag = False
print("如果没有找到,这里可以认为到了最后一页")
if all_lists:
to_csv(csv_filename, all_lists)
def parse_html(page_source):
html = etree.HTML(page_source)
info_links = html.xpath("//div[@class='job-list']/ul/li")
for link in info_links:
name=link.xpath(".//span[@class='job-name']/a/text()")#名称
url = ["https://www.zhipin.com/" +
x for x in link.xpath(".//span[@class='job-name']/a/@href")] # 链接
company = link.xpath(".//h3[@class='name']/a/text()") # 公司
salary = link.xpath(".//span[@class='red']/text()") # 薪酬
d = dict()
for x in range(len(name)):
d["name"] = name[x]
d["url"] = url[x]
d["company"] = company[x]
d["salary"] = salary[x]
all_lists.append(d)
def to_csv(file, all_lists):
headnames = ['name', 'url', 'company', 'salary']
with open(file, 'w', encoding='utf_8_sig', newline="") as f:
writer = csv.DictWriter(f, fieldnames=headnames)
writer.writeheader()
writer.writerows(all_lists)
if __name__ == "__main__":
crawl()
代码执行结果如图所示,同时浏览器自动翻页,自动爬取,请读者自行验证。
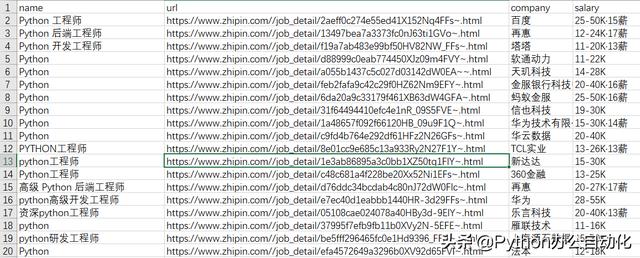
Python招聘的公司岗位薪酬还是很不错的,祝你早日找到合适的高薪职位。














 281
281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









