





在2012年,深度学习出现之前,SVM被认为机器学习是近十几年来最成功的,表现最好的算法。
机器学习的一般框架:
从训练集中提取特征向量,针对特征向量结合一定的算法得到训练好的模型,用的到的模型预测新的实例,进行分类。这就是机器学习大概的框架过程。
SVM的动机,也就是目的是什么呢?
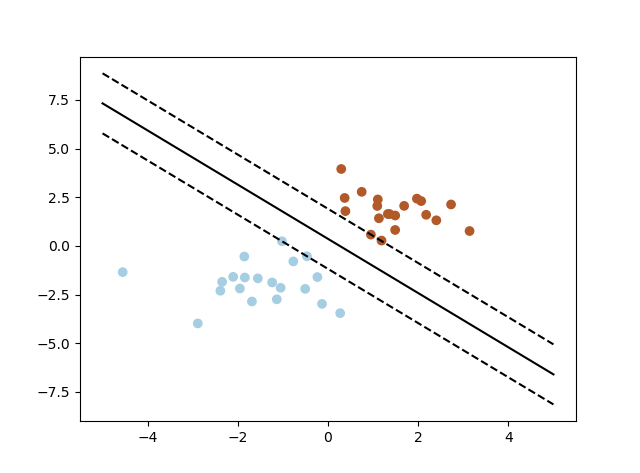
寻找区分两类的超平面(hyper plane),使边际最大。这里的边际是指超平面到两侧的点的最近的距离。边际最大的有利于更准确的对样本进行分类。
超平面的理解:
超平面是一维小于其环境空间的子空间。如果空间是3维的,那么它的超平面是2维的,而如果空间是二维的,则其超平面是一维线。这个概念可以用于定义子空间维度的任何一般空间。
超平面又分为两种情况:
一种:线性可区分(linear separable)
另一种:线性不可区分(linear inseparable)
在数学上超平面定义为这样一个公式:W·X+b=0
W是一个向量,weight vector,W={w1,w2,...,wn}
n是特征值的个数
X是训练实例
b是bias
在二维特征向量下:X=(x1,x2)
把b想象为额外的weight
超平面方程变为:
w0+w1·x1+w2·x2=0(这里的意思是将超平面方程中对应的b换成了w0)
这个公式可以从曾经学到的解析几何中的直线方程,来类比。在解析几何中表现一条直线用:y=ax+b,其中x是自变量,b截距,a是斜率。这里的w0+w1x1+w2x2=0,就可以类比为高维的直线方程。这样就相对好理解一点。
也就是说 w0+w1x1+w2x2=0,就表示所有满足条件的点,就在超平面上。也就是所有满足条件的点,组成了一个超平面。
在超平面的右上方的点满足:w0+w1x1+w2x2>0
在超平面的左下方的点满足:w0+w1x1+w2x2<0
通过这种定义就能够区分出,超平面、超平面右上方,超平面左下方的,不同区域的点的范围。
通过调整weight,可以使超平面定义边际的两边:
H1:w0+w1x1+w2x2>=1 for yi=+1
H2:w0+w1x1+w2x2<=1 for yi=-1
在这两个公式中又定义了一个yi,(由于不好输入,这里的1,2,i都是下标),这里的yi是指(x1,x2)这个点所属的归类,也就是之前说过的class label值。其中的值+1代表一类,-1代表一类。通过调整weight建立了两个部分。需要理解的是yi并不是坐标值,而是class label的分类值。
将上述的两个式子左右相乘就能得到如下公式:
yi(w0+w1x1+w2x2)>=1, 对于任意i都满足左侧的这个条件。
所有坐落在边际的两边的超平面上的点被称作“支持向量(support vectors)”
分界的超平面和H1或H2上的任意一点的距离为1/||W||,1除以W向量的范数,同时就能知道,最大化的边际的距离就是2/||W||
其中||W||是向量的范数(norm):If W=(w1,w2,...,wn) then W*W开方等于(w1的平方+w2的平方+...+wn的平方)的开方。
关键的问题来了:SVM,也就是支持向量机如何找出最大边际的超平面呢(MMH)?
过程比较复杂,需要一系列的数学公式进行推导,通过公式:yi(w0+w1x1+w2x2)>=1, 对于任意i都满足左侧的这个条件,可以变为有限制的凸优化问题,利用Karush=Kuhn-Tucker(KKT)条件和拉格朗日公式,可以推出MMH可以被表示为以下“决定边界”(decision boundary):
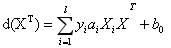
右侧的公式从1~L个值的求和,l是指总共有多少个支持向量点,对从属于支持向量的点进行求和,
yi是指一个点是支持向量的点xi(support vector)的类别标记
xi是特征向量的值,yi是class label
xT是转置矩阵,是要测试的实例
这个方程就是使边际最大化的平面。将实例带入方程,根据方程式的值的结果,来对相应的测试实例进行分类。
训练好的模型的算法复杂度是由支持向量的个数决定的,而不是由数据的维度决定的。所以svm不太容易产生overfitting
svm训练出来的模型完全依赖于支持向量(support vectors),即使训练集里面所有非支持向量的点都被去除,重复训练过程,结果仍然得到一个完全一样的模型
一个svm如果训练得出的支持向量的个数比较小,svm训练处的模型也比较容易被泛化。
对于线性不可分的情况:
数据集在空间中对应的向量不可被一个超平面区分开,这种情况一样可以通过svm来进行区分。
有如下两个步骤:
利用一个非线性的映射把原数据集中的向量点转换到一个更高维度的空间中
在这个高维度的空间中找一个线性的超平面来根据线性可分的情况来处理。
就相当于做了一次更高维度的投射,转换在了同一个维度,这样就更好的区分了。















 1526
1526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









