







1.SVM算法的特点
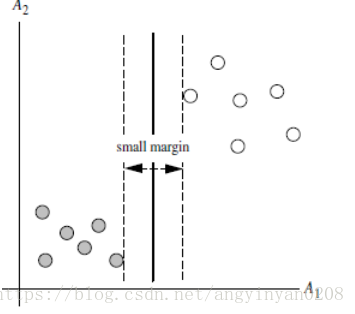

1.1 训练好的模型的算法复杂度是由支持向量的个数决定的,而不是由数据的维度决定的。 所有SVM不太容易产生overfitting
1.2 SVM训练出来的模型完全依赖于支持向量(Support Vectors),即使训练集里面所有非支持向量的点都被去除,重复训练过程,结果仍然会得到完全一样的模型。
1.3 一个SVM如果训练得出的支持向量个数比较小,SVM训练出的模型比较容易被泛化。
2.对于线性不可分的情况(linearly inseparable case)
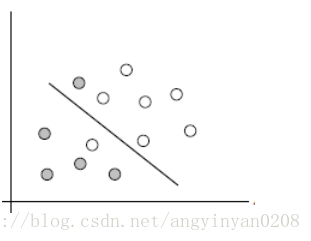
前面也提到如果软间隔支持向量机允许某些样本点不满足,但是当有大量的样本点不满足时,则不能使用这个方法了。
2.1两个步骤来解决:
-
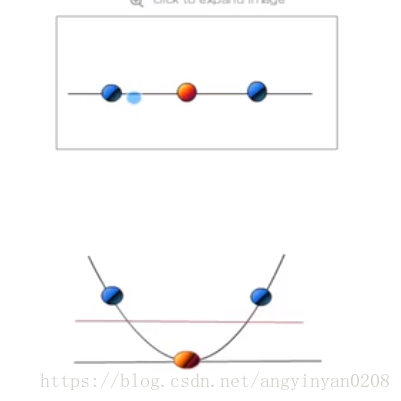
利用一个非线性的映射把原数据集中的向量点转化到一个更高维度的空间中
-
在这个高维度的空间中找一个线性的超平面来根据线性可分的情况处理
可以观看这个视频连接:https://www.youtube.com/watch?v=3liCbRZPrZA
2.2如何利用非线性映射把原始数据转化
2.2.1举个简单的小例子:

2.2.2思考两个问题:
2.2.2.1如何选择合理的非线性转化把数据转到高维中?
2.2.2.2如何解决计算机內积时算法复杂度非常高的问题?
2.2.3使用核方法(Kernel trick)
3.核方法(kernel trick)
3.1动机

3.2以下核函数和非线性映射函数的內积等同
常用的核函数:

如何选择使用哪个kernel?
根据先验知识,比如图像分类,通常使用RBF,文字不使用RBF
尝试不同的kernel,根据结果准确度而定。
3.3核函数的简单小例子

4.SVM扩展可解决多个类别分类问题
对于每个类,有一个当前类和其他类的二类分类器(one-vs-rest)














 706
706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









