






几个值的深思的问题
- 什么是字符?
字符是各种文字和符号的总称,包括各个国家文字、标点符号、图形符号、数字等。 - 什么是字符集?
字符集是多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同,常见字符集有:ASCII字符集、ISO 8859字符集、GB2312字符集、BIG5字符集、GB18030字符集、Unicode字符集等 - 什么是字符编码?
1、 计算机要准确的处理各种字符集文字,需要进行字符编码,以便计算机能够识别和存储各种文字。
2、 字符编码(encoding)和字符集不同。字符集只是字符的集合,不一定适合作网络传送、处理,有时须经编码(encode)后才能应用。如Unicode可依不同需要以UTF-8、UTF-16、UTF-32等方式编码。
3、字符编码就是以二进制的数字来对应字符集的字符。 因此,对字符进行编码,是信息交流的技术基础。 - 概括
1、使用哪些字符。也就是说哪些汉字,字母和符号会被收入标准中。所包含“字符”的集合就叫做“字符集”。
2、规定每个“字符”分别用一个字节还是多个字节存储,用哪些字节来存储,这个规定就叫做“编码”。
3、各个国家和地区在制定编码标准的时候,“字符的集合”和“编码”一般都是同时制定的。因此,平常我们所说的“字符集”,比如:GB2312, GBK, JIS 等,除了有“字符的集合”这层含义外,同时也包含了“编码”的含义。
4、注意:Unicode字符集有多种编码方式,如UTF-8、UTF-16等;ASCII只有一种;大多数MBCS(包括GB2312,GBK)也只有一种。 - 有趣的例子
1、在显示器上看见的文字、图片等信息在电脑里面,其实并不是我们看见的样子,即使你知道所有信息都存储在硬盘里,把它拆开也看不见里面有任何东西,只有些盘片。假设,你用显微镜把盘片放大,会看见盘片表面凹凸不平,凸起的地方被磁化,凹的地方是没有被磁化;凸起的地方代表数字1,凹的地方代表数字0。硬盘只能用0和1来表示所有文字、图片等信息。
2、那么字母”A”在硬盘上是如何存储的呢?可能小张计算机存储字母”A”是1100001,而小王存储字母”A”是11000010,这样双方交换信息时就会误解。比如小张把1100001发送给小王,小王并不认为1100001是字母”A”,可能认为这是字母”X”,于是小王在用记事本访问存储在硬盘上的1100001时,在屏幕上显示的就是字母”X”。也就是说,小张和小王使用了不同的编码表。小张用的编码表是ASCII,ASCII编码表把26个字母都一一的对应到2进制1和0上;小王用的编码表可能是EBCDIC,只不过EBCDIC编码与ASCII编码中的字母和01的对应关系不同。一般地说,开放的操作系统(LINUX 、WINDOWS等)采用ASCII 编码,而大型主机系统(MVS 、OS/390等)采用EBCDIC 编码。在发送数据给对方前,需要事先告知对方自己所使用的编码,或者通过转码,使不同编码方案的两个系统可沟通自如。 - 这个例子说明了三点
1、不管是任何文字图片等,最后都会以二进制的形式储存到电脑的磁盘中(比如记事本A.txt,内容为”ABC”文件,在此磁盘中表现的就是01 01这种二进制形式)
盘片表面凹凸不平,凸起的地方被磁化,凹的地方是没有被磁化,凸起的地方代表数字1,凹的地方代表数字0。硬盘只能用0和1来表示所有文字、图片等信息。是的 很强势
2、 任何文件要储存到电脑中,都会事先进行编码,然后储存到电脑的磁盘中,比如A.txt文件,默认编码为ANSI编码,也可以编码为UTF-8,然而不同的编码方式 对应着计算机用一个字节还是多个字节存储,用哪些字节来存储。
3、在双方数据进行通讯时,要么就保证发送方和接受方的数据编码是相同,要么就是其中一方需要转码 - 什么是字节和位?
字节byte和位bit是电脑里的数据量单位。
1.按计算机中的规定,一个英文的字符占用一个字节,而一个汉字以及汉字的标点符号、字符都占用两个字节。
2.1个字节等于8位 1byte=8bit
3.1bit在磁盘中以二进制01的形式保存 凸起的地方代表数字1,凹的地方代表数字0
字符编码种类
ASCII
ASCII码是西欧编码的方式,采取7位编码,所以是2^7=128,共可以表示128个字符,包括34个字符,(如换行LF,回车CR等),其余94位为英文字母和标点符号及运算符号等。
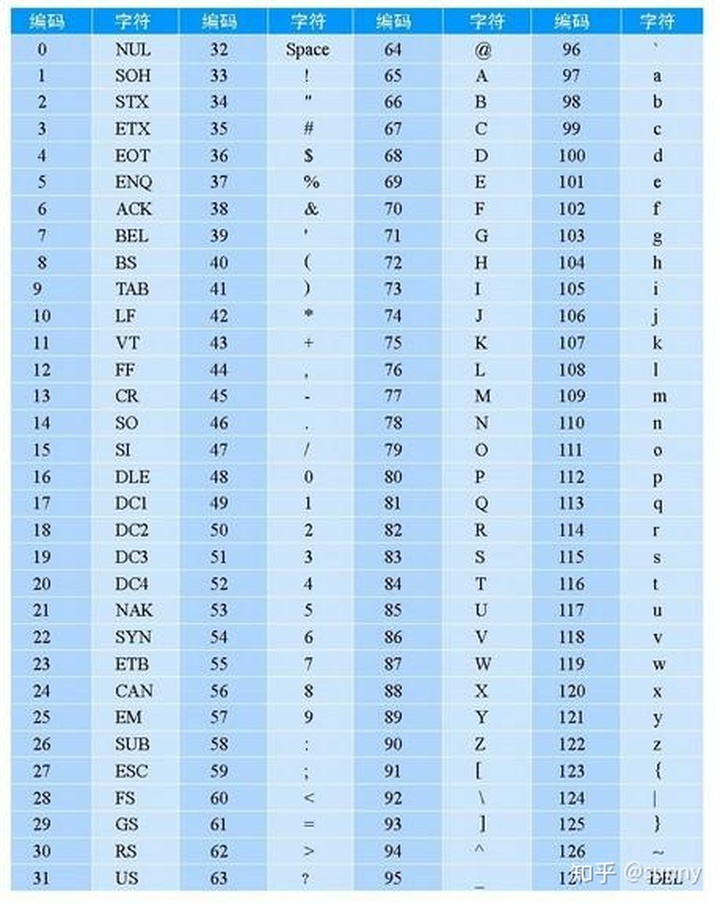
重点:
字符集:从符号(NUL=”/0”=“空操作字符”)到“Z”再到“DEL”符号
字符编码范围:二进制:00000000——01111111 十进制:0-127
占用字节:1字节 8bit 盘片储存方式:凹凹凹凹凹凹凹凹——凸凸凸凸凸凸凸凸
注:NUL:‘0’是一个ASCII码为0的字符,从ASCII码表中可以看到ASCII码为0的字符是“空操作字符”,它不引起任何控制动作,也不是一个可显示的字符。
但我们发现ASCII码是没有中文编码的,显然在天朝是不够用的,于是GB2312诞生了。
GB2321
GB2312 是对 ASCII 的中文扩展。兼容ASCII。
编码规定:
编码小于127的字符与ASCII编码相同,
特性:两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(称之为高字节)从0xA1用到0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。
字符集:从符号(NUL=”/0”=“空操作字符”)到“Z”到“齄”(简体中文)
字符编码范围:16进制:0x0000-(中间有一部分是未使用的)-0xF7FE
占用字节:英文 1字节 8bit 盘片储存方式:凹凹凹凹凹凹凹凹——凸凸凸凸凸凸凸凸
中文 2字节 16bit 凹凹凹凹凹凹凹凹凹凹凹凹凹凹凹凹——…
GBK
GBK 兼容ASCLL 兼容 GB2312 是GB2312的扩展
但是中国的汉字太多了,我们很快就就发现有许多人的人名没有办法在这里打出来,不得不继续把 GB2312 没有用到的码位找出来用上。后来还是不够用,于是干脆不再要求低字节一定是127号之后的内码,只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。结果扩展之后的编码方案被称为 “GBK” 标准,GBK 包括了 GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。
Unicode
Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。
目前的Unicode字符分为17组编排,0x0000至0x10FFFF,每组称为平面(Plane),而每平面拥有65536个码位,共1114112个。然而目前只用了少数平面。UTF-8、UTF-16、UTF-32都是将数字转换到程序数据的编码方案。
UTF-8
UTF-8以字节为单位对Unicode进行编码。从Unicode到UTF-8的编码方式如下:
UTF-8的特点是对不同范围的字符使用不同长度的编码。对于0x00-0x7F之间的字符,UTF-8编码与ASCII编码完全相同。UTF-8编码的最大长度是6个字节。从上表可以看出,6字节模板有31个x,即可以容纳31位二进制数字。Unicode的最大码位0x7FFFFFFF也只有31位。
例1:“汉”字的Unicode编码是0x6C49。0x6C49在0x0800-0xFFFF之间,使用用3字节模板了:1110xxxx 10xxxxxx 10xxxxxx。将0x6C49写成二进制是:0110 1100 0100 1001, 用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89。
举一个例子:It’s 知乎日报
你看到的unicode字符集是这样的编码表:
I 0049
t 0074
’ 0027
s 0073
0020
知 77e5
乎 4e4e
日 65e5
报 62a5
每一个字符对应一个十六进制数字。
计算机只懂二进制,因此,严格按照unicode的方式(UCS-2),应该这样存储:
I 00000000 01001001
t 00000000 01110100
’ 00000000 00100111
s 00000000 01110011
00000000 00100000
知 01110111 11100101
乎 01001110 01001110
日 01100101 11100101
报 01100010 10100101
这个字符串总共占用了18个字节,但是对比中英文的二进制码,可以发现,英文前9位都是0!浪费啊,浪费硬盘,浪费流量。
怎么办?
UTF
UTF-8是这样做的:
- 单字节的字符,字节的第一位设为0,对于英语文本,UTF-8码只占用一个字节,和ASCII码完全相同;
- n个字节的字符(n>1),第一字节的前n位设为1,第n+1位设为0,后面字节的前两位都设为10,这n个字节的其余空位填充该字符unicode码,高位用0补足。
这样就形成了如下的UTF-8标记位:
| 高位字节 | 低位字节 | 低位字节 | 低位字节 | 低位字节 | 低位字节 |
|---|
比如”知”字 在Unicode中占用两个字节,那么第一字节(我叫它高位字节)的前两位设位1,第三位设为10,后面低位字节设为前两位设为10, “知”→ 11100111 10011111 10100101
怎么知道“知”字占用两个字节的?首先要知道Unicode字符集中,“知”字的编码为77e5,然后转化为二进制流01110111 11100101的bit,每8bit等于1byte 所以就占两个字节
于是,”It’s 知乎日报“就变成了:
I 01001001
t 01110100
’ 00100111
s 01110011
00100000
知 11100111 10011111 10100101
乎 11100100 10111001 10001110
日 11100110 10010111 10100101
报 11100110 10001010 10100101
和上边的方案对比一下,英文短了,每个中文字符却多用了一个字节。但是整个字符串只用了17个字节,比上边的18个短了一点点。
剧透:一切都是为了节省你的硬盘和流量。
一图解忧愁
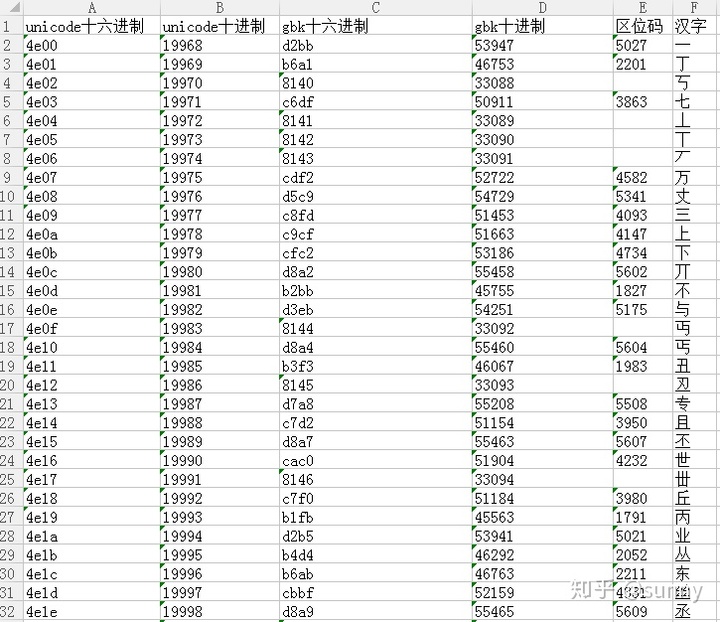
1.从这个可以看出,同样的字符集,但unicode编码和gbk编码是不同的。,所以unicode字符集不兼容gbk字符集
2.只要知道unicode字符集的编码表,就可以用UTF8编码规则找到UTF-8对应的汉字编码
解决问题
从上面的内容了解了字符编码以后,以后遇到相关的字符编码问题的时候至少有解决的思路,而不是一头雾















 1666
1666











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









