








用 dplyr 包实现各种数据操作,通常的数据操作无论多么复杂,往往都可以分解为若干基本数据操作步骤的组合。
共有 5 种基本数据操作:
select()——选择列filter()/slice()——筛选行arrange()—— 对行排序mutate()——修改列/创建新列summarize()——汇总
这些函数都可以与
group_by()——分组
连用,以改变数据操作的作用域:作用在整个数据框,或数据框的每个分组。
这些函数组合使用就足以完成各种数据操作,它们的相同之处是:
- 第 1 个参数是数据框,方便管道操作
- 根据列名访问数据框的列,且列名不用加引号
- 返回结果是一个新数据框,不改变原数据框
从而,可以方便地实现:"将多个简单操作,依次用管道连接,实现复杂的数据操
作"。
另外,若要同时对所选择的多列应用函数,还有强大的 across() 函数,它支持各种选择列语法,搭配 mutate() 和 summarise() 使用,产生非常强大同时修改/汇总多列的效果。
2.5.1 选择列
选择列,包括对数据框做选择列、调整列序、重命名列。
下面以虚拟的学生成绩数据来演示,包含随机生成的 20 个 NA:
df = read_xlsx("datas/ExamDatas_NAs.xlsx")
df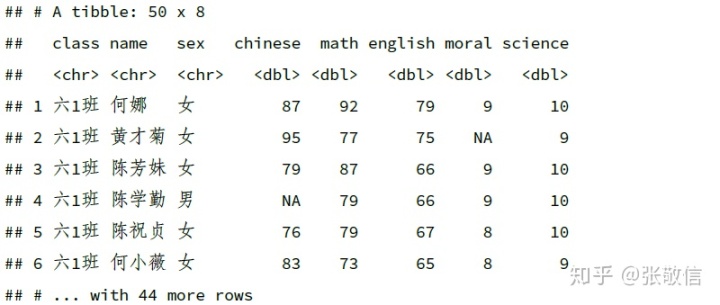
1. 选择列语法
(1) 用列名或索引选择列
df %>%
select(name, sex, math) # 或者select(2, 3, 5)
(2) 借助运算符选择列
- 用
:选择连续的若干列 - 用
!选择变量集合的余集(反选) &和|选择变量集合的交或并c()合并多个选择
(3) 借助选择助手函数
选择指定列:
everything(): 选择所有列last_col(): 选择最后一列,可以带参数,如last_col(5)选择倒数第 6 列
选择列名匹配的列:
starts_with(): 以某前缀开头的列名ends_with(): 以某后缀结尾的列名contains(): 包含某字符串的列名matches(): 匹配正则表达式的列名num_range(): 匹配数值范围的列名,如num_range("x", 1:3)匹配x1, x2, x3
结合函数选择列:
where(): 应用一个函数到所有列,选择返回结果为TRUE的列,比如与is.numeric等函数连用
2. 一些选择列的示例
df %>%
select(starts_with("m"))
df %>%
select(ends_with("e"))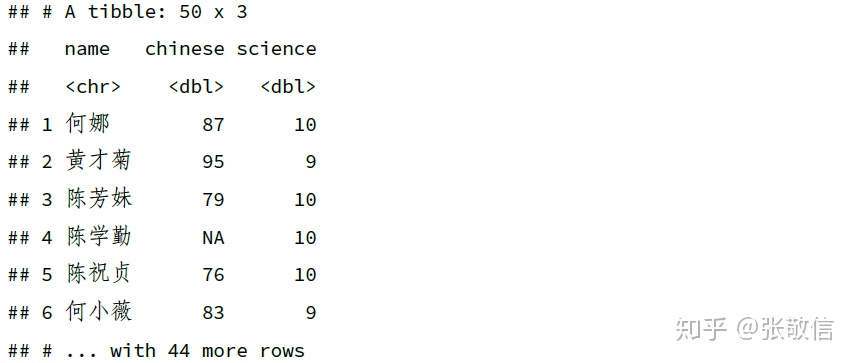
df %>%
select(contains("a"))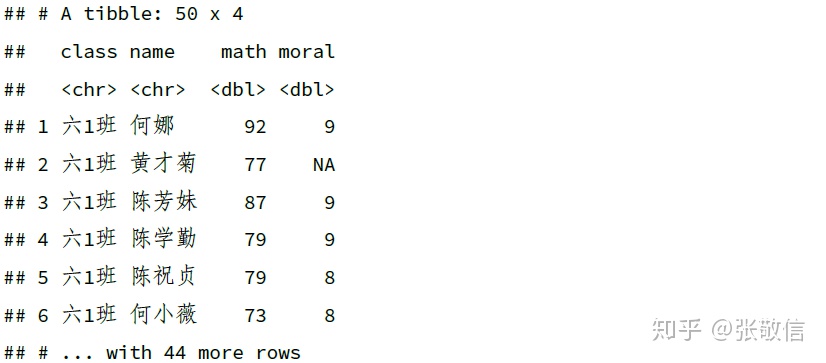
- 根据正则表达式匹配选择列:
df %>%
select(matches("m.*a"))

- 根据条件(逻辑判断)选择列,例如选择所有数值型的列:
df %>%
select(where(is.numeric))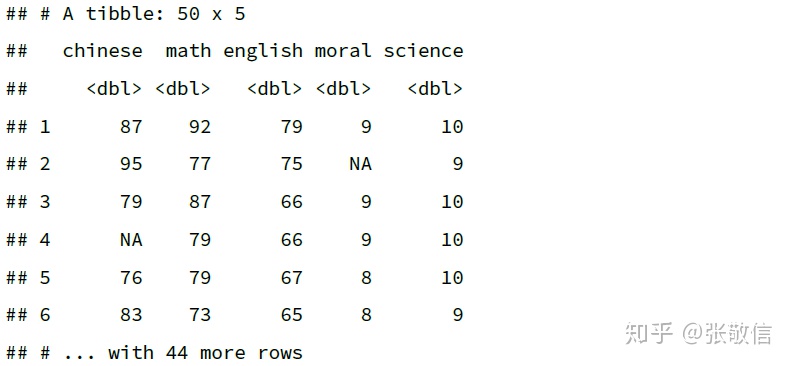
也可以自定义返回 TURE 或 FALSE 的判断函数,支持 purrr 风格公式写法。例如,选择列和 > 3000 的列:
df[, 4:8] %>%
select(where(~ sum(.x, na.rm = TRUE) > 3000))
再比如,结合 n_distinct() 选择唯一值数目 < 10 的列:
df %>%
select(where(~ n_distinct(.x) < 10))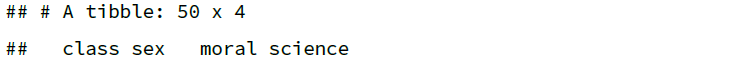
3. 用 - 删除列
df %>%
select(-c(name, chinese, science)) # 或者select(-ends_with("e"))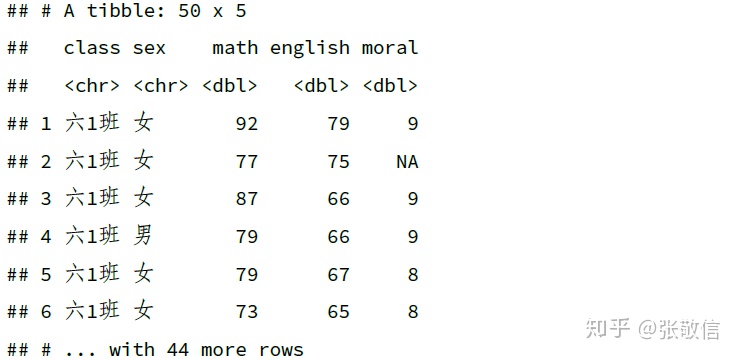
df %>%
select(math, everything(), -ends_with("e")) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2024
2024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









