







 本文通过一个连续10年积雪深度和灌溉面积的案例,详细解析了Excel数据分析工具得出的回归结果。包括回归统计表中的相关系数、测定系数、校正测定系数、标准误差和样本数目,以及方差分析表的自由度、误差平方和、均方差、F值和P值等关键统计指标。
本文通过一个连续10年积雪深度和灌溉面积的案例,详细解析了Excel数据分析工具得出的回归结果。包括回归统计表中的相关系数、测定系数、校正测定系数、标准误差和样本数目,以及方差分析表的自由度、误差平方和、均方差、F值和P值等关键统计指标。
内容来自用户:jasonboy95
利用Excel的数据分析进行回归,可以得到一系列的统计参量。下面以连续10年积雪深度和灌e69da5e887aa3231313335323631343130323136353331333433646365溉面积序列(图1)为例给予详细的说明。
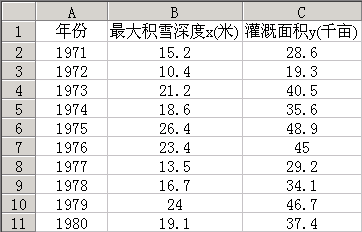
图1连续10年的最大积雪深度与灌溉面积(1971-1980)
回归结果摘要(Summary Output)如下(图2):
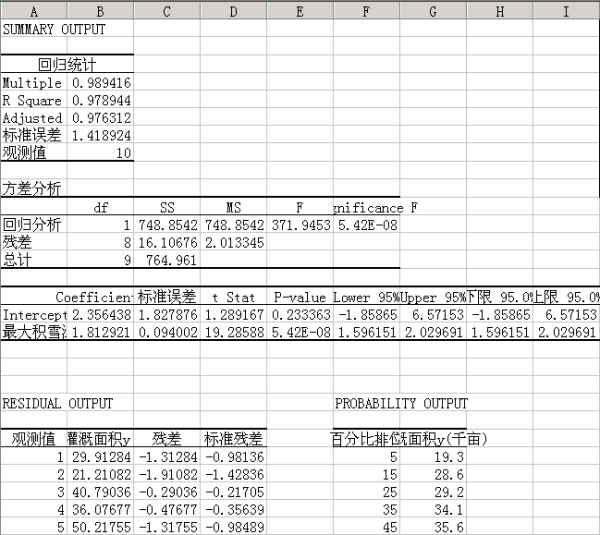
图2利用数据分析工具得到的回归结果
第一部分:回归统计表
这一部分给出了相关系数、测定系数、校正测定系数、标准误差和样本数目如下(表1):
表1回归统计表
逐行说明如下:
Multiple对应的数据是相关系数(correlation coefficient),即R=0.989416。
R Square对应的数值为测定系数(determination coefficient),或称拟合优度(goodness of fit),它是相关系数的平方,即有R2=0.9894162=0.978944。
Adjusted对应的是校正测定系数(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3278
3278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









