







近几年随着网络通信技术和互联网软件服务的快速发展,人们获得和处理的数据量都越来越大,市场上大数据人才稀缺。与大数据相关的职位主要有数据开发、数据挖掘、数据分析等,这些职位都要求掌握分布式计算计算例如Hadoop、Spark等等。如下图所示,数据挖掘、数据开发等岗位都要求候选人掌握一定分布式计算平台的知识,这篇文章就简要介绍一下当今最火热、应用场景广泛的大数据架构Spark


1.Spark的前世今生
Spark计算机集群是2009年由UC Berkeley AMP lab开发的一个集群计算的框架,目的是让数据分析更加快速。
Spark集群是一组计算机的集合,每个计算机节点作为独立的计算资源,又可以虚拟出多个具备计算能力的虚拟机,这些虚拟机是集群中的计算单元。Spark的核心模块专注于调度和管理虚拟机之上分布式计算任务的执行,集群中的计算资源则交给Cluster Manager这个角色来管理,Cluster Manager可以为自带的Standalone、或第三方的Yarn和Mesos。
2.Spark核心组件
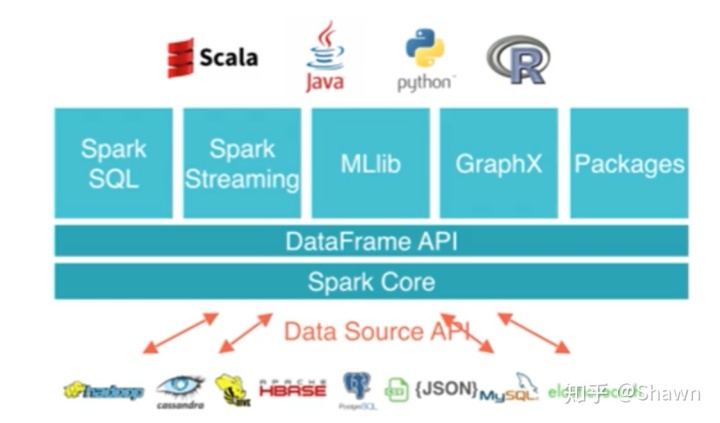
Spark接受的语法:SQL, Python, Scala, Java, R
Spark Streaming:支持高吞吐量、支持容错的实时流数据处理
Spark SQL,Data frames: 结构化数据查询
MLLib:Spark 生态系统里用来解决大数据机器学习问题的模块
GraphX是构建于Spark上的图计算模型
SparkR是一
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 708
708











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









