






 本文介绍了Pandas库的基本使用,包括数据框的创建、数据的读入导出、列名和行名的修改、数据的选取与合并,以及数据处理方法如清除无效数据、删去行列、排序、提取信息和数学运算。重点讲解了如何批量修改列名以及数据读取时的参数设置,帮助读者深入理解Pandas数据操作。
本文介绍了Pandas库的基本使用,包括数据框的创建、数据的读入导出、列名和行名的修改、数据的选取与合并,以及数据处理方法如清除无效数据、删去行列、排序、提取信息和数学运算。重点讲解了如何批量修改列名以及数据读取时的参数设置,帮助读者深入理解Pandas数据操作。

这次要学习的库是pandas库,该库是基于numpy为解决分析任务而创建的。pandas库引入的数据框概念,与R语言的数据框非常相似,并且提供了相关的函数实现快捷处理。下面就从大方面去了解pandas库,可通过下面的语句载入pandas库:
import pandas as pd一、数据结构及创建
pandas库中独有的数据结构就是数据框。所谓的数据框其实与之前的二维数组没什么区别,数据框的每一列都有对应的列名,每一行都有对应的行名。而一维的数据框在pandas库中有特别的称呼——系列Series。
# 创建一维数据框Series,index指定行名
s = pd.Series([3,-5,7,4],index = ['a','b','c','d'])二维的数据框就是一般的形式,创建方式也是比较简单:
data = {
'name':['john','mike','lily'],
'age':[13,14,13],
'height':[145,156,146]
}
df = pd.DataFrame(data,index = [1,2,3])
二、数据的读入和导出
pandas对于数据读入上有很好的处理能力,下面是官方给出的对应数据类型,pandas的读入方法和导出方法:
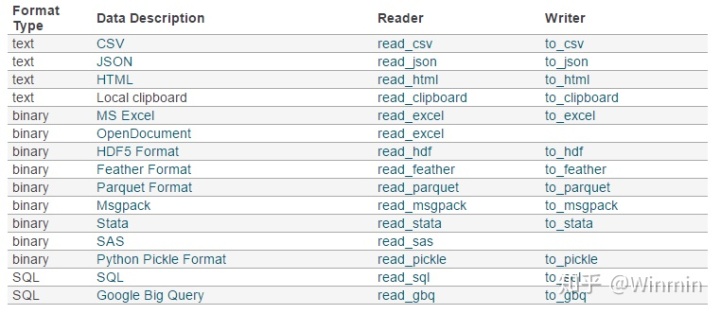
在上图可以看到pandas支持的数据类型很多,首先需要注意的无论是txt文件还是csv文件,在Pandas中都使用read_csv()方法读取,导出的方法也是一样的。其次,在读取函数read_*中有一些重要的参数:
· filepath_or_buffer: 文件所在路径,可以是一个描述路径的字符串· encoding : 编码,通常为'utf-8',如果中文读取不正常,可以将encoding设为'gbk'· sep: 分隔符,默认为一个英文逗号','· delimiter: 备选分隔符,如果指定了delimiter则sep失效· header: 用来指定由哪一列或者哪几列作为列名,默认为header=0,表示第一列作为列名· names: 一个列表,为数据额外指定列名
介绍完导入函数的重要参数之后,我们可以尝试导入数据:
# 设置工作目录
import os
os.chdir('C:UsersAdministratorDesktop')
# 导入csv数据
df = pd.read_csv('data.csv', encoding='gbk')
# 导入txt数据
df1 = pd.read_csv('data.txt', encoding='gbk',sep=' ')
# 导入excel数据
df2 = pd.read_excel('data.xlsx',encoding='gbk')
能成功读取之后,现在就是学习导出数据的方法了,首先我们先学习一些to_*类函数的重要参数:
· path_or_buf: 表示路径的字符串或者文件句柄,也是是导出数据的完整的文件名称· sep: 分隔符,默认为英文逗号','· header: 可为字符串的列表或布尔值,前者可以为数据重新设置列名,后者设置是否输出列名
同样地我们可以尝试将数据导出:
# 导出为csv / txt / excel
df.to_csv('data2.csv') / df.to_txt('data2.txt') / df.to_excel('data2.excel')更多关于数据读取和导出的细节,大家可以参考连接文章:Pandas数据读取与导出
三、数据的选取
数据框的数据选择无非就从两个维度选择,一个是列或者行的标签名,另外一种就是按照行列数。因为选取数据框的数据也有挺多方法的,下面就分几种情况,分别介绍适用的选择方法:
# 选取(多)列,行没有要求
df[['姓名','数学']]
# 选取(多)行,列没有要求
df[1:3] # 表示取第二行到第三行的数据
# 选取单(多)行,单(多)列
df.iloc[[3],[3]] / df.iloc[[2,3],0:3]
df.loc[[2],['英语']] / df.loc[[2,3],['数学','英语']]
# iloc行和列的选取是数学,loc选择的行列都是具体的行名列名
# 按照条件选取数据框子集
df[df['语文']>70]既然数据的选择与数据框的行名和列名有很大的关系,那么我们顺便了解一下如何修改数据框的列名和行名,这个可以方便我们对数据框的数据选择:
# 修改列名
df.columns = ['A','B','C','D']
# 修改行名
df.index = ['A','B','C','D',E'','F']四、数据合并
数据和合并可分为纵向合并和横向合并,pandas中对于数据框的合并采用的方法主要有concat、merge、append等,下面就逐个学习:
首先是concat的使用,首先参数 axis=0表示合并方向为上下,ignore_index表示是否将忽略原index重新定义index。
# 纵向合并1(列名称相同)
import numpy as np
df1 = pd.DataFrame(np.ones((3,4))*0, columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1, columns=['a','b','c','d'])
df3 = pd.DataFrame(np.ones((3,4))*2, columns=['a','b','c','d'])
res = pd.concat([df1, df2, df3], axis=0,ignore_index=True)
#纵向合并2(列名称不尽相同)
df1 = pd.DataFrame(np.ones((3,4))*0, columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1, columns=['b','c','d','e'])
# outer为外连接 inner为内连接 连接原理与数据库的连接一致
res = pd.concat([df1, df2], axis=0, join='outer',ignore_index=True)
res = pd.concat([df1, df2], axis=0, join='inner',ignore_index=True)
#横向合并1(行名称相同)
res = pd.concat([df1, df2], axis=1)
#横向合并2(行名称不尽相同)
df1 = pd.DataFrame(np.ones((3,4))*0, columns=['a','b','c','d'], index=[1,2,3])
df2 = pd.DataFrame(np.ones((3,4))*1, columns=['b','c','d','e'], index=[2,3,4])
# 参数join_axes 决定连接的方式,若不指定参数的取值为全外连接,指定的话就按照左连接或者右连接
res = pd.concat([df1, df2], axis=1, join_axes=[df1.index])
res = pd.concat([df1, df2], axis=1)接着也是比较重要的连接方法merge,这个方法是使用于横向合并。上面concat的连接是按照列行名称进行的,而merge则是根据数据框的字段取值进行连接的,类似于数据框的多表连接中的等值连接。这里介绍一下merge中用于指定连接的字段关键参数有:
·on:当用于连接的字段名称一致时使用
·left_on / right_on:连接的字段名称不一样时使用,用于指定合并表对应的两个字段名称·left_index / right_index:使用行索引合并用于指定两数据表的行索引
指定好连接的字段时,此时需要决定的是连接的方法,通过参数how指定,其取值有:
"left"(左连接) 、"right"(右连接)、"inner"(内连接)和"outer"(全外连接)。
还有参数suffixes,用于追加到重叠列名的末尾,用于区分数据合并前的来源,通常需要我们用字符串列表元组指定后缀内容,默认为('_x','_y')。
最后的合并用法是append,这个方法通常用于为数据框添加字段的和纵向合并拥有相同列字段名称的数据框,比如:
# 添加字段
df1 = pd.DataFrame(np.ones((3,4))*0, columns=['a','b','c','d'])
s1 = pd.Series([1,2,3,4], index=['a','b','c','d'])
res = df1.append(s1, ignore_index=True)
# 纵向合并(仅当合并的两表列名称一致)
import numpy as np
df1 = pd.DataFrame(np.ones((3,4))*0, columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1, columns=['a','b','c','d'])
df3 = df1.append(df2,ignore_index=True)五、数据处理
1、清除无效数据
pandas中的数据框数据出现缺失时,会显示NaN,我们一般对其的处理无非就是使用其他值替换NaN值,或者删去NaN所在的行或者列。
# 删去包含NaN值的所有行
df.dropna()
# 删去指定方向上包含了指定数量个NaN值的行或者列
df.dropna(axis=0,thresh=4) # 删去行方向上有四个NaN值的行
#将数据框中的NaN值替换为0
df.fillna(0)
#将数据框中第一列的NaN值替换成0,第二行的NaN值替换成5
df.fillna({1:0, 2:5})2、删去行列
df.drop(['a','b']) #删去行索引为a或者b的行
df.drop(['A','B'],axis = 1) #删去列名为A或B的列3、排序
# 按照行索引或者列名称排列,参数ascending=False 降序排列
df.sort_index(axis = 0) #按行
df.sort_index(axis = 1) #按列
#按照字段的值排序
df.sort_values(by = '数学',ascending=False)
# 返回序数
df.rank() #返回相同大小的数据框,且每个字段的取值为原字段元素对应的排序数,值越小序数越小4、提取数据框信息
# 数据框的维数
df.shape()
# 数据框的行索引
df.index()
# 数据框的列名称
df.columns()
# 数据框的整体信息
df.info()
# 数据框非NaN值的个数
df.count()
# 提取数据框前几行数据
df.head()5、数学函数
pandas的数学函数都是针对数据框每一列进行运算的:
# 求和
df.sum()
# 累加
df.cumsum()
# 最大小值
df.max()/ df.min()
# 最大小值的行索引
df.idxmax() / df.idxmin()
# 平均数和中位数
df.mean() / df.median()
# 数据框的数据统计汇总
df.describe()6、数学运算
在各种运算方法中,参数order用于指定与数据框运算的序列、常量或者数据框,参数axis可用于控制运算的方向,参数fill_value 为None或者浮点型,用于替换缺省值。
# 矩阵加法
df.add()
# 矩阵减法
df.sub()
#矩阵乘法
df.mul()
#矩阵除法
df.div()














 7353
7353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









