







一、RDD为什么出现?
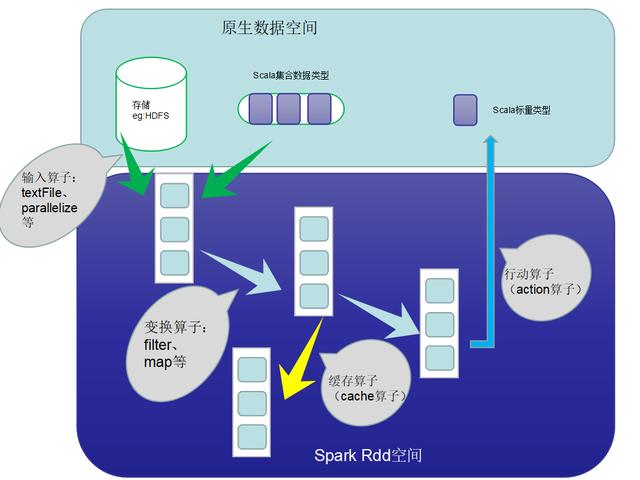
在实际开发应用中,存在许多迭代式计算,这些应用场景的共同之处是,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。
以前常用的MapReduce框架是把中间结果写入到HDFS中,带来了大量的数据复制、磁盘IO和序列化开销。
如果有一种方法,能将结果保存在内存当中,就可以大量减少IO消耗。RDD一种弹性分布数据集,就是为了满足这种需求而出现的,它提供了一个抽象的数据架构,我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理。
不同RDD之间的转换操作形成依赖关系,可以实现管道化,从而避免了中间结果的落地存储,大大降低了数据复制、磁盘IO和序列化开销。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 496
496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









