







MVSNet:香港科技大学的权龙教授团队的MVSNet(2018年ECCV)开启了用深度做多视图三维重建的先河。
2019年,2020年又有多篇改进:RMVSNet(CVPR2019),PointMVSNet(ICCV2019),P-MVSNet(ICCV2019),MVSCRF(ICCV2019),Cascade(CVPR2020),CVP-MVSNet(CVPR2020),Fast-MVSNet(CVPR2020),UCSNet(CVPR2020),CIDER(AAAI2020),PVAMVSNet(ECCV2020),D2HC-RMVSNet(ECCV2020),Vis-MVSNet(BMVC 2020)。
一 MVSNet:目标是预测图片上每个像素的深度信息
MVSNet: Depth Inference for Unstructured Multi-view Stereo
MVSNet本质是借鉴基于两张图片cost volume的双目立体匹配的深度估计方法,扩展到多张图片的深度估计,而基于cost volume的双目立体匹配已经较为成熟,所以MVSNet本质上也是借鉴一个较为成熟的领域,然后提出基于可微分的单应性变换的cost volume用于多视图深度估计。
论文实现了权龙教授多年的深度三维重建想法。
过程:
(1)输入一张reference image(为主) 和几张source images(辅助);
(2)分别用网络提取出下采样四分之一的32通道的特征图;
(3)采用立体匹配(即双目深度估计)里提出的cost volume的概念,将几张source images的特征利用单应性变换( homography warping)转换到reference image,在转换的过程中,类似极线搜索,引入了深度信息。构建cost volume可以说是MVSNet的关键。
具体costvolume上一个点是所有图片在这个点和深度值上特征的方差,方差越小,说明在该深度上置信度越高。
(4)利用3D卷积操作cost volume,先输出每个深度的概率,然后求深度的加权平均得到预测的深度信息,用L1或smoothL1回归深度信息,是一个回归模型。
(5)利用多张图片之间的重建约束(photometric and geometric consistencies)来选择预测正确的深度信息,重建成三维点云。
该论文最重要的单应性变换( homography warping)的公式写错了,误导了好几篇后续改进的顶会论文,不过神奇地是提供的代码没有错:
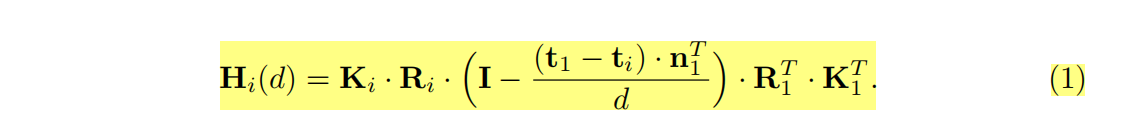
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









