






很多人经常说,同样的SQL在Oracle中的查询性能要比在MySQL中好很多,大家有没有深究过其中的原因呢?除了MySQL 8.0之前不支持hash-join以外,还有其他原因吗?
其实很多时候,出现这种差异的原因,是Oracle有查询重写的机制,并不是Oracle本身有多快,而是Oracle聪明的优化器已经帮你改好了SQL。
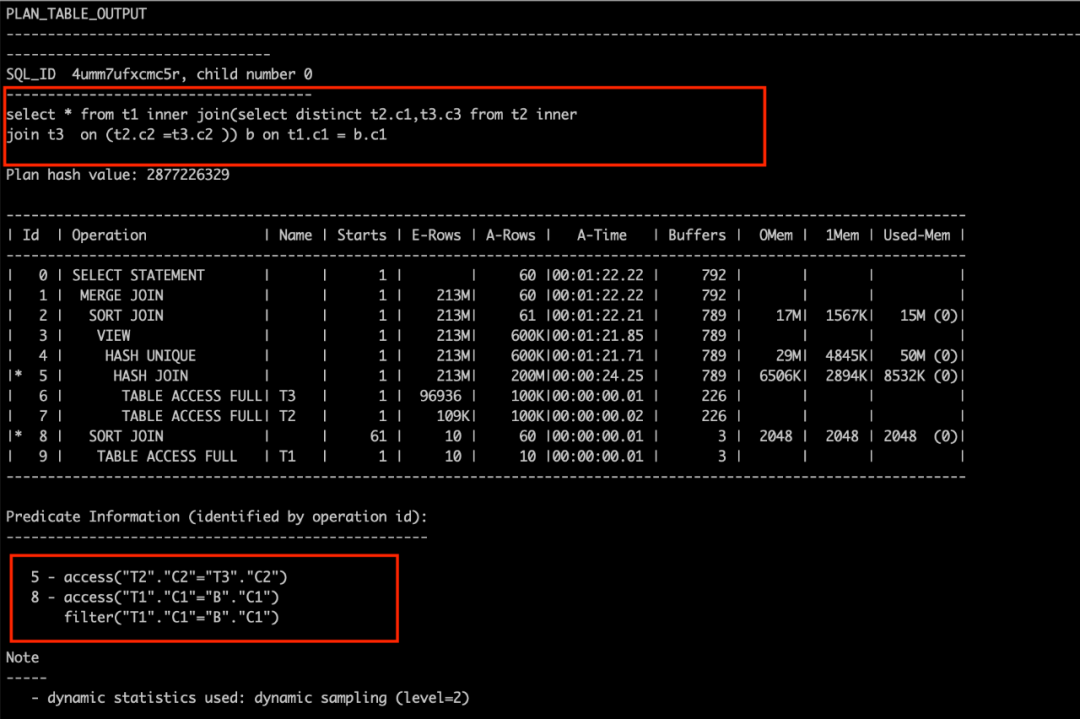
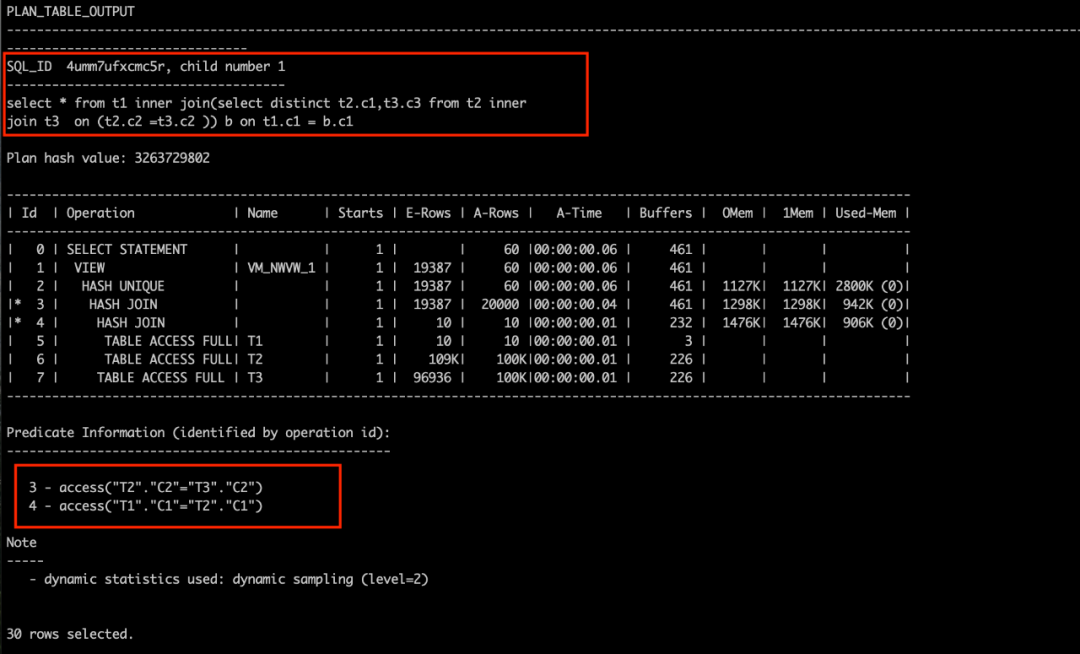
首先,对比下面两张图,看看区别在哪里?
 对比两个图,能看到图2中,oracle做了view merge,将
(select distinct t2.c1,t3.c3 from t2 inner join t3 on (t2.c2 =t3.c2 )) b
打开,view中的表与其他表放在一起计算连接方式,生成一个性能较好的执行计划;图1的执行计划中,
外层循环一次,view就要执行一次,里面的谓词又不高效,因此,查询性能就表现得很差。
就不卖关子了,其实,我在第一次执行SQL前,先将参数
"_complex_view_merging"
设成了
false ,默认是true。
实验过程如下:
对比两个图,能看到图2中,oracle做了view merge,将
(select distinct t2.c1,t3.c3 from t2 inner join t3 on (t2.c2 =t3.c2 )) b
打开,view中的表与其他表放在一起计算连接方式,生成一个性能较好的执行计划;图1的执行计划中,
外层循环一次,view就要执行一次,里面的谓词又不高效,因此,查询性能就表现得很差。
就不卖关子了,其实,我在第一次执行SQL前,先将参数
"_complex_view_merging"
设成了
false ,默认是true。
实验过程如下:
声明一下,写这篇文章的目的,不是想说Oracle多好,MySQL多么不好,研发SQL写得好,那么在MySQL中得查询性能也是一样一样的~
对比两个图,能看到图2中,oracle做了view merge,将
(select distinct t2.c1,t3.c3 from t2 inner join t3 on (t2.c2 =t3.c2 )) b
打开,view中的表与其他表放在一起计算连接方式,生成一个性能较好的执行计划;图1的执行计划中,
外层循环一次,view就要执行一次,里面的谓词又不高效,因此,查询性能就表现得很差。
就不卖关子了,其实,我在第一次执行SQL前,先将参数
"_complex_view_merging"
设成了
false ,默认是true。
实验过程如下:

select * from tt1 inner join(select distinct tt2.c1,tt3.c3 from tt2 inner join tt3 on (tt2.c2 =tt3.c2 )) b on tt1.c1 = b.c1 ;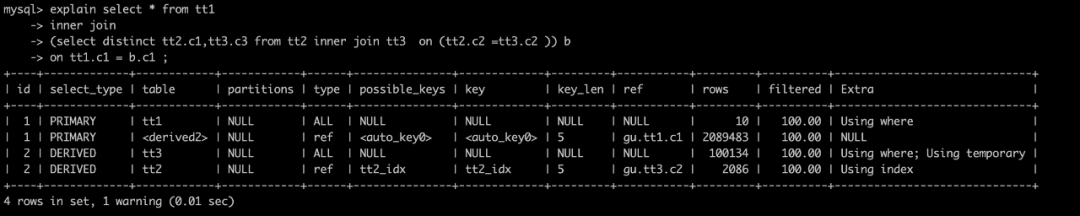
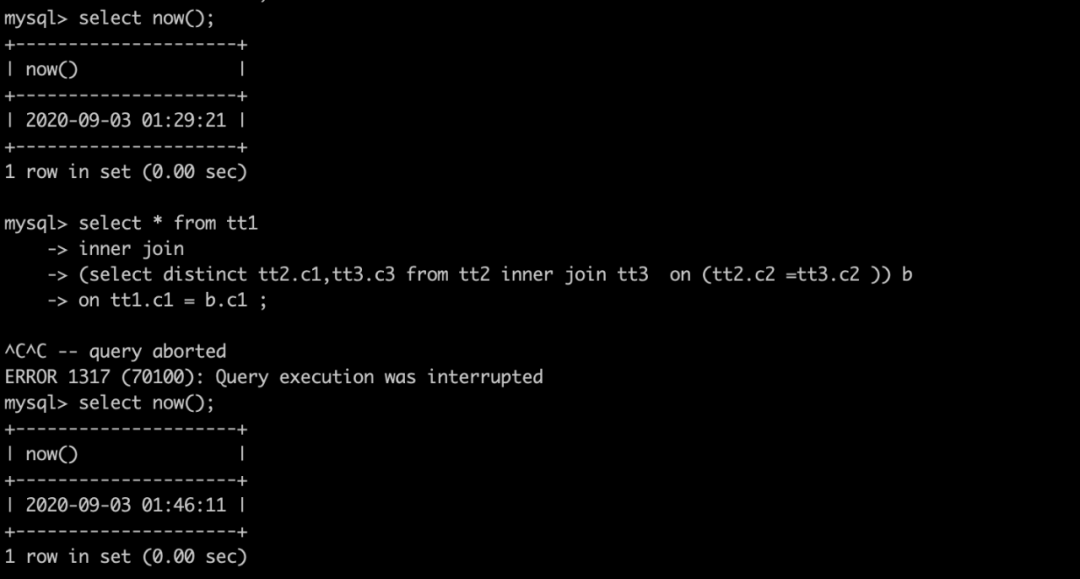
select * from tt1 ,(select distinct c2, c1 from tt2) t2 ,(select distinct c2,c3 from tt3) t3where tt1.c1=t2.c1 and t2.c2=t3.c2;

声明一下,写这篇文章的目的,不是想说Oracle多好,MySQL多么不好,研发SQL写得好,那么在MySQL中得查询性能也是一样一样的~














 3213
3213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









