





继续我们的目标检测算法的分享,前期我们介绍了SSD目标检测算法的python实现以及Faster-RCNN目标检测算法的python实现以及yolo目标检测算法的darknet的window环境安装,本期我们简单介绍一下如何使用python来进行YOLOV3的对象检测算法

YOLOV3对象检测
YOLOV3的基础知识大家可以参考往期文章,本期重点介绍如何使用python来实现
图片识别
1、初始化模型
14-16 行:
模型的初始化依然使用cv下的DNN模型来加载模型,需要注意的是CV的版本需要大于3.4.2
5-8行:
初始化模型在coco上的label以便后期图片识别使用
10-12行:
初始化图片显示方框的颜色
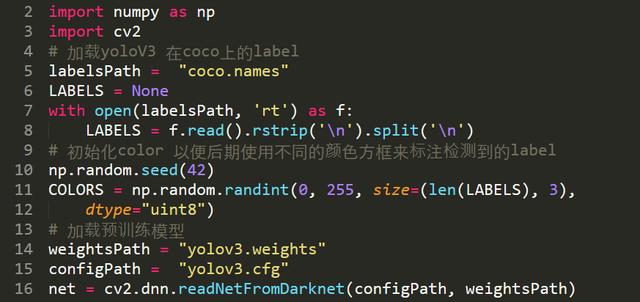
初始化模型
2、加载图片,进行图片识别
输入识别的图片进行图片识别,这部分代码跟往期的SSD 以及RCNN目标检测算法类似
19-20行:输入图片,获取图片的长度与宽度
25-29行:计算图片的blob值,输入神经网络,进行前向反馈预测图片
只不过net.forward里面是ln, 神经网络的所有out层

图片识别
3、遍历所有的out层,获取检测图片的label与置信度
遍历out层,获取检测到的label值以及置信度,检测到这里YOLOV3以及把所有的检测计算完成,但是由于yolov3对重叠图片或者靠的比较近的图片检测存在一定的问题,使用YOLOV3使用非最大值抑制来抑制弱的重叠边界
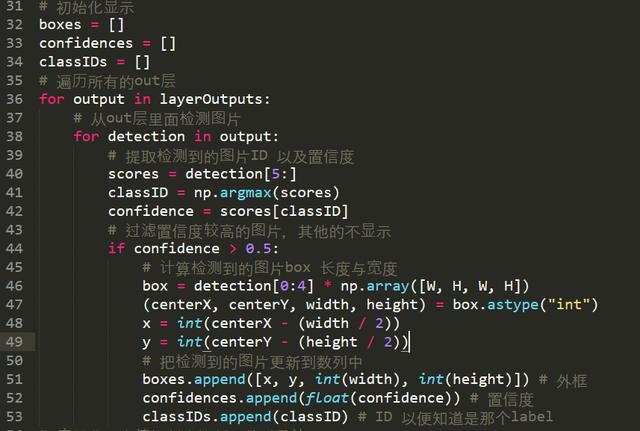
遍历图片
竟然把墨镜识别了手机,体现了YOLOV3在重叠图片识别的缺点

4、应用非最大值抑制来抑制弱的重叠边界,显示图片
56: 使用非最大值抑制来抑制弱的重叠边界
58-59行:遍历所有图片
61-62行:提取检测图片的BOX
64-68行:显示图片信息
70-71行:显示图片

显示图片
利用python来实现YOLOV3,与SSD 以及RCNN代码有很多类似的地方,大家可以参考往期的文章进行对比学习,把代码执行一遍

图片识别
视频识别
进行视频识别的思路:从视频中提取图片,进行图片识别,识别完成后,再把识别的结果实时体现在视频中,这部分代码结合前期的视频识别,大家可以参考多进程视频实时识别篇,因为没有多进程,检测速度很慢,视频看着比较卡
1、初始化模型以及视频流
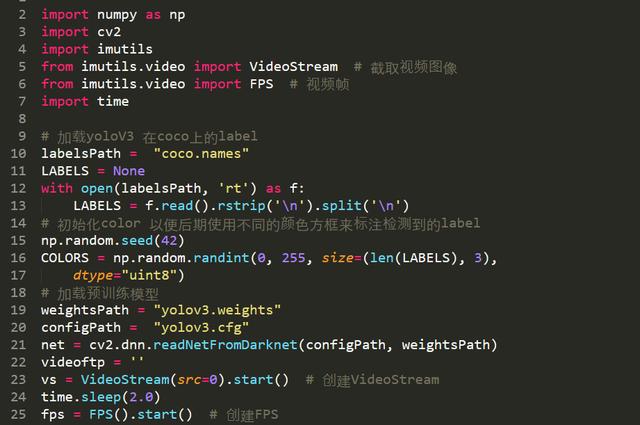
初始化
2、从视频中提取图片,进行图片的blob值计算,进行神经网络的预测

提取图片进行识别
3、提取检测到图片的置信度以及ID值

提取图片信息
4、应用非最大值抑制来抑制弱的重叠边界,显示图片

检测图片
5、关闭资源,显示图片处理信息

每个目标检测算法都有自己的优缺点,个人感觉,在精度要求不是太高的情况下SSD检测算法可以实现较快的速度实现,毕竟精度差不多的情况下,我们希望速度越快越好

截图视频图片















 1716
1716











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









