







k近邻法 (k-nearest neighbor, k-NN) 是一种基本分类与回归方法。是数据挖掘技术中原理最简单的算法之一,核心功能是解决有监督的分类问题。KNN能够快速高效地解决建立在特殊数据集上的预测分类问题,但其不产生模型,因此算法准确 性并不具备强可推广性。
k近邻法的输入为实例的特征向量,对应与特征空间的点;输出为实例的类别,可以取多类。
k近邻法 三个基本要素:
k 值的选择、距离度量及分类决策规则 。

算法过程
1, 计算训练样本和测试样本中每个样本点的距离;
2, 对上面所有的距离值进行排序;
3, 选前k个最小距离的样本;
4, 根据这k个样本的标签进行投票,得到最后的分类类别。
- 输入:训练数据集
其中, 为实例的特征向量, 为实例的类别,
- 输出:实例 所属的类
(1)根据给定的距离度量,在训练集 中找出与 最近邻的个点,涵盖这个 点的 的邻域记作)
(2)在 )中根据分类决策规则(如多数决策)决定 的类别其中, 为指示函数,即 时 为 1,否则 为 0。
距离度量
特征空间中两个实例点的距离是两个实例点相似程度的反映。
在距离类模型,例如KNN中,有多种常见的距离衡量方法。如欧几里得距离、曼哈顿距离、闵科夫斯基距离、切比雪夫距离及余弦距离。其中欧几里得距离为最常见。
- 欧几里得距离
(Euclidean Distance)
在欧几里得空间中,两点之间或多点之间的距离表示又称欧几里得度量。
二维平面三维空间
推广到在 n维空间 中,有两个点A和B,两点的坐标分别为:坐标轴上的值 正是我们样本数据上的n个特征。
- 曼哈顿距离
(Manhattan Distance)
曼哈顿距离,正式意义为城市区块距离,也被称作街道距离,该距离在欧几里得空间的固定直角坐标所形成的线段产生的投影的距离总和。其计算方法相当于是欧式距离的1次方表示形式,其基本计算公式如下:
- 闵科夫斯基距离
(Minkowski Distance)
其中p是一个变参数:
当p=1时,就是曼哈顿距离;
当p=2时,就是欧氏距离;
当p→∞时,就是切比雪夫距离。
因此,根据变参数的不同,闵氏距离可以表示某一类 / 种的距离。
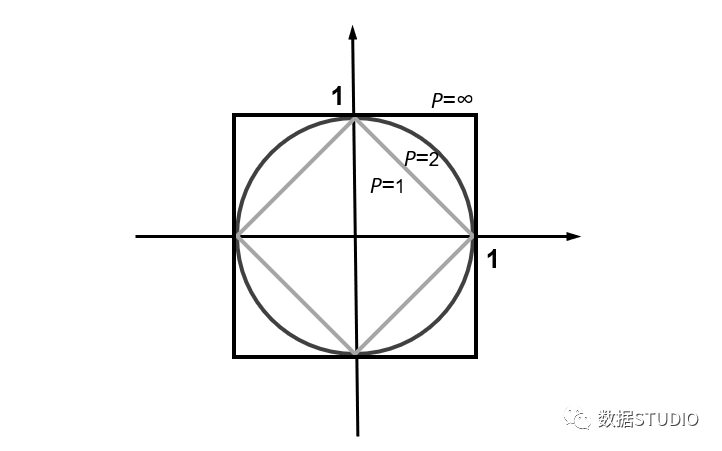
闵氏距离,包括曼哈顿距离、欧氏距离和切比雪夫距离都存在明显的缺点。
e.g. 二维样本(身高[单位:cm],体重[单位:kg]), 现有三个样本:
a(180,50),b(190,50),c(180,60)。那么a与b的闵氏距离(无论是曼哈顿距离、欧氏距离或切比雪夫距离)等于a与c的闵氏距离。但实际上身高的10cm并不能和体重的10kg划等号。闵氏距离的缺点:
(1)将各个分量的量纲(scale),也就是"单位"相同的看待了;(2)未考虑各个分量的分布(期望,方差等)可能是不同的。
- 切比雪夫距离
(Chebyshev Distance)
国际象棋中,国王可以直行、横行、斜行,所以国王走一步可以移动到相邻8个方格中的任意一个。国王从格子(xa,ya)走到格子(xb,yb)最少需要多少步?这个距离就叫切比雪夫距离。
n维空间
- 余弦距离
(Cosine Distance)
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个样本差异的大小。余弦值越接近1, 说明两个向量夹角越接近0度,表明两个向量越相似。几何中,夹角余弦可用来衡量两个向量方向的差异;机器学习中,借用这一概念来衡量样本向量之间的差异。
k值选择
k 值的选择会对KNN 算法的结果产生重大影响。
k值的减小就意味着整体模型变得复杂,学习器容易受到由于训练数据中的噪声而产生的过分拟合的影响。k值的的增大就意味着整体的模型变得简单。如果k太大,最近邻分类器可能会将测试样例分类错误,因为k个最近邻中可能包含了距离较远的,并非同类的数据点。
在应用中,k 值一般选取一个较小的数值,通常采用交叉验证来选取最优的k 值。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1369
1369











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









