





fastText文本分类思想
fastText文本分类的核心思想是什么? 仔细观察模型的后半部分,即从隐含层输出到输出层输出,会发现它就是一个softmax线性多类别分类器,分类器的输入是一个用来表征当前文档的向量;模型的前半部分,即从输入层输入到隐含层输出部分,主要在做一件事情:生成用来表征文档的向量。那么它是如何做的呢?叠加构成这篇文档的所有词及n-gram的词向量,然后取平均。叠加词向量背后的思想就是传统的词袋法,即将文档看成一个由词构成的集合。 于是fastText的核心思想就是:将整篇文档的词及n-gram向量叠加平均得到文档向量,然后使用文档向量做softmax多分类。这中间涉及到两个技巧:字符级n-gram特征的引入以及分层Softmax分类。
一、fastText简介
fastText是一个快速文本分类算法,与基于神经网络的分类算法相比有两大优点:
1、fastText在保持高精度的情况下加快了训练速度和测试速度
2、fastText不需要预训练好的词向量,fastText会自己训练词向量
3、fastText两个重要的优化:Hierarchical Softmax、N-gram
二、fastText模型架构
fastText 模型架构和 Word2Vec 中的 CBOW 模型很类似,不同之处在于,fastText 预测标签,而 CBOW 模型预测中间词。一般情况下,使用fastText进行文本分类的同时也会产生词的embedding,即embedding是fastText分类的产物。CBOW看文章:
word2vec将上下文关系转化为多分类任务,进而训练逻辑回归模型,这里的类别数量|V|词库大小。通常的文本数据中,词库少则数万,多则百万,在训练中直接训练多分类逻辑回归并不现实。word2vec中提供了两种针对大规模多分类问题的优化手段, negative sampling 和hierarchical softmax。在优化中,negative sampling 只更新少量负面类,从而减轻了计算量。hierarchical softmax 将词库表示成前缀树,从树根到叶子的路径可以表示为一系列二分类器,一次多分类计算的复杂度从|V|降低到了树的高度。
模型架构三层还是:输入层、隐藏层、输出层
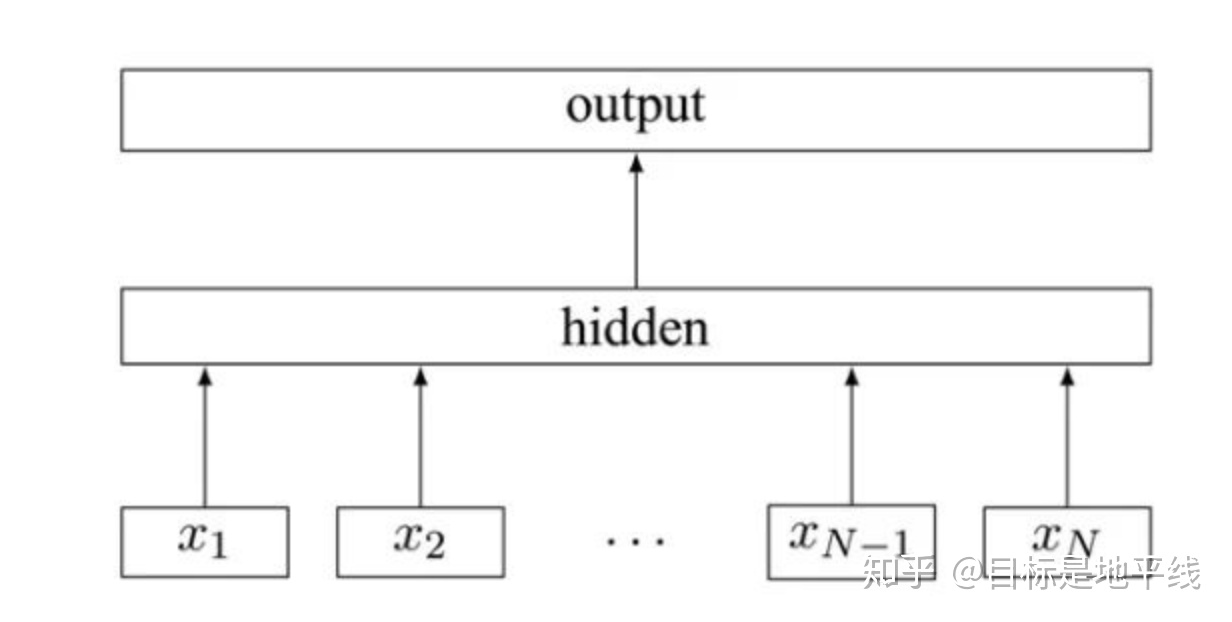
输入:fastText的输入是多个单词及其n-gram特征,这些特征用来表示单个文档,将整个文本作为特征去预测文本对应的类别
三、层次softmax
3.1Softmax回归
Softmax回归(Softmax Regression)又被称作多项逻辑回归(multinomial logistic regression),它是逻辑回归在处理多类别任务上的推广。
在逻辑回归中, 我们有m个被标注的样本:
代价函数(cost function)如下:
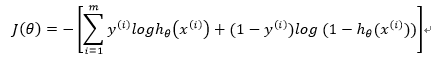
在Softmax回归中,类标是大于2的,因此在我们的训练集
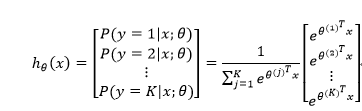
代价函数如下:
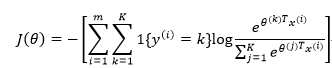
其中1{·}是指示函数,即1{true}=1,1{false}=0
既然我们说Softmax回归是逻辑回归的推广,那我们是否能够在代价函数上推导出它们的一致性呢?当然可以,于是:

可以看到,逻辑回归是softmax回归在K=2时的特例。
softmax函数常在神经网络输出层充当激活函数,目的就是将输出层的值归一化到0-1区间,将神经元输出构造成概率分布,主要就是起到将神经元输出值进行归一化的作用,下图展示了softmax函数对于输出值z1=3,z2=1,z3=-3的归一化映射过程
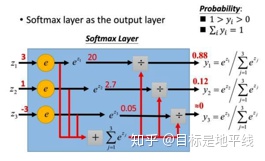
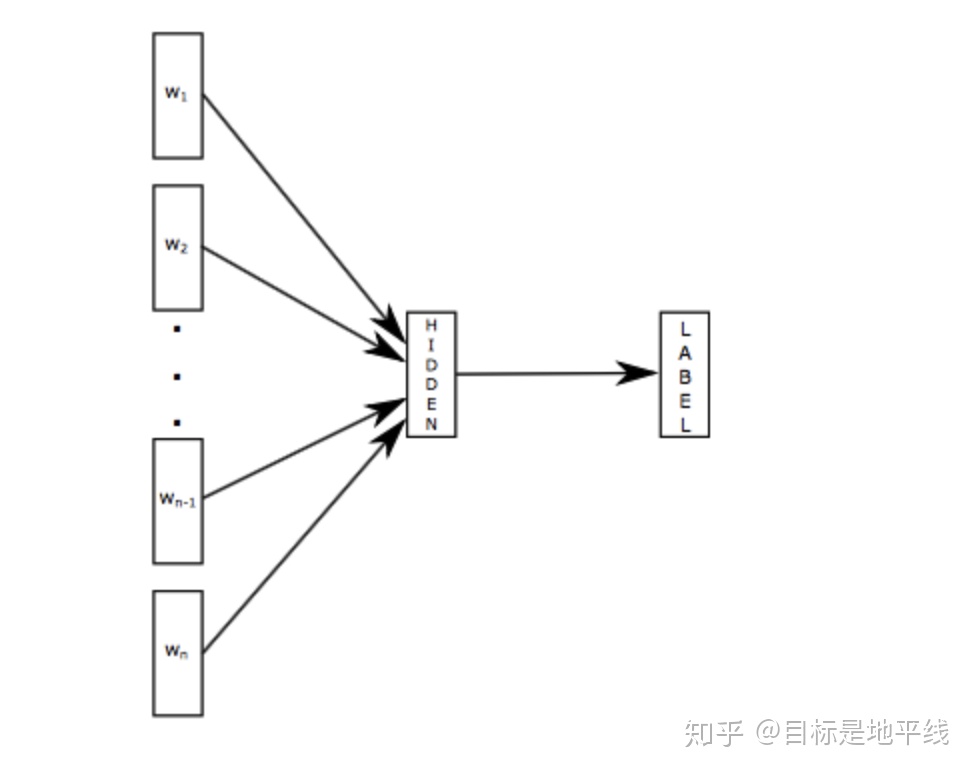
在标准的softmax中,计算一个类别的softmax概率时,我们需要对所有类别概率做归一化,在这类别很大情况下非常耗时,因此提出了分层softmax(Hierarchical Softmax),思想是根据类别的频率构造霍夫曼树来代替标准softmax,通过分层softmax可以将复杂度从N降低到logN,从而降低算法的时间复杂度。下图给出分层softmax示例:
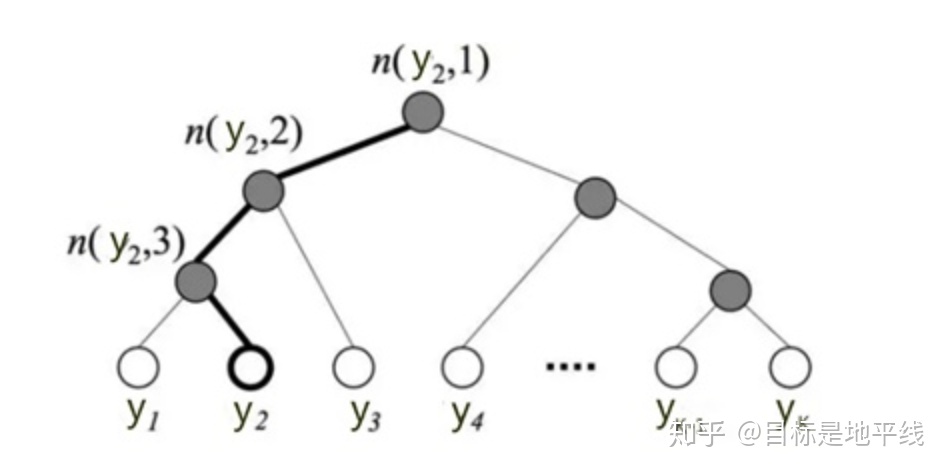
使用树的层级结构替代扁平化的标准Softmax,使得在计算
树的结构是根据类标的频数构造的霍夫曼树。K个不同的类标组成所有的叶子节点,K-1个内部节点作为内部参数,从根节点到某个叶子节点经过的节点和边形成一条路径,路径长度被表示为
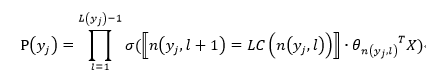
其中:
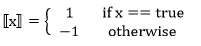
X是Softmax层的输入
上图中,高亮的节点和边是从根节点到
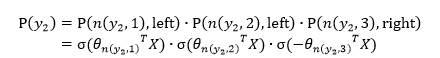
于是,从根节点走到叶子节点
通过分层的Softmax,计算复杂度一下从|K|降低到log|K|。
3.2 之前写过N-gram,一种利用滑动窗口扩大词的特征的方法,不赘述。
fastText效果好的原因:
我 来到 北师大
俺 去了 北京师范大学
这两段文本意思几乎一模一样,如果要分类,肯定要分到同一个类中去。但在传统的分类器中,用来表征这两段文本的向量可能差距非常大。传统的文本分类中,你需要计算出每个词的权重,比如tfidf值, “我”和“俺” 算出的tfidf值相差可能会比较大,其它词类似,于是,VSM(向量空间模型)中用来表征这两段文本的文本向量差别可能比较大。但是fastText就不一样了,它是用单词的embedding叠加获得的文档向量,词向量的重要特点就是向量的距离可以用来衡量单词间的语义相似程度,于是,在fastText模型中,这两段文本的向量应该是非常相似的,于是,它们很大概率会被分到同一个类中。使用词embedding而非词本身作为特征,这是fastText效果好的一个原因;另一个原因就是字符级n-gram特征的引入对分类效果会有一些提升 。实战fastText进行文本分类:
liunx版本下操作:
$ git clone https://github.com/facebookresearch/fastText.git
$ cd fastText
$ pip install .
安装成功后的导入:
import fasttext.FastText as fasttext数据集:
用的是清华的新闻数据集(由于完整数据集较大,这里只取部分数据)
链接: https://pan.baidu.com/s/1rgJQ4hSqRzxjUiVKPKjQkg 提取码: fpfj
完整实现文本分类代码已经放到github上:
exuding/NLPgithub.com
参考文献:
















 1011
1011











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









