







一、fastText原理
2017年,Facebook提出的 fastText 是在大型语料库上快速训练模型,并为未出现在训练数据中的单词计算其表征。模型如其名,最大的优势在于快速。
fastText 的 CBOW 模型:将 word2vec 的 CBOW 模型中的中心词替换为类别标签就是 fastText。
fastText 的 skip-gram 模型:
首先,word2vec 的 skip-gram 是根据词 word 对上下文的词 word 做预测。
fastText 的 skip-gram 模型做出的改进是增加了子词 sub-word,那么就可以根据子词 sub-word,或者词 word,或者两者结合 sub-word + word 对上下文做预测,实际操作中是根据两者结合做预测。
We also include the word w itself in the set of its n-grams, to learn a representation for each word (in addition to character n-grams).
2017 ACL中 Enriching Word Vectors with Subword Information 的报告展示,解释他们当时并未尝试单纯用 sub-word 做预测。另外提问环节也解释了他们当时并未采用词类比(word analogy)的语料库做训练(如snow -- white)。
注意 ngrams 中起始位置<>,以区分 sub-word 和 word 相同的部分。
二、fastText对12种影音节目进行分类
1.加载训练数据
# 加载数据
import pandas as pd
train_df = pd.read_csv('data/text_train.txt', sep='\t', header=None)
train_df.columns = ['label', 'content']
train_df.head()
>>>
label content
0 娱乐 《青蛇》造型师默认新《红楼梦》额妆抄袭(图) 凡是看过电影《青蛇》的人,都不会忘记青白二蛇的...
1 娱乐 6.16日剧榜 <最后的朋友> 亮最后杀招成功登顶 《最后的朋友》本周的电视剧排行榜单依然只...
2 娱乐 超乎想象的好看《纳尼亚传奇2:凯斯宾王子》 现时资讯如此发达,搜狐电影评审团几乎人人在没有看...
3 娱乐 吴宇森:赤壁大战不会出现在上集 “希望《赤壁》能给你们不一样的感觉。”对于自己刚刚拍完的影片...
4 娱乐 组图:《多情女人痴情男》陈浩民现场耍宝 陈浩民:外面的朋友大家好,现在是搜狐现场直播,欢迎《...
# 查看训练集分类名称以及样本数量
for name, group in train_df.groupby(train_df.columns[0]):
print(name,len(group))
>>>
体育 2000
健康 2000
女人 2000
娱乐 2000
房地产 2000
教育 2000
文化 2000
新闻 2000
旅游 2000
汽车 2000
科技 2000
财经 20002.训练数据集 预处理
2.1 jieba分词
# 训练数据集分词
import jieba
with open('data/stopwords.txt', encoding='utf8') as file:
line_list = file.readlines()
stopword_list = [k.strip() for k in line_list]
stopword_set = set(stopword_list)
def word_cut(content, stopword_set):
cutWords = [k for k in jieba.cut(content, True) if k not in stopword_set]
return " ".join(cutWords)
train_df["content"] = train_df["content"].map(lambda x: word_cut(x, stopword_set))
train_df.head()
>>>
label content
0 娱乐 青蛇 造型 造型师 默认 新 红楼 红楼梦 额 妆 抄袭 图 看过 过电 电影 青蛇 不...
1 娱乐 6.16 日剧 榜 < 最后 朋友 > 亮 最后 杀招 成功 登顶 最后 朋友 ...
2 娱乐 超乎 想象 好看 纳尼亚 尼亚 传奇 2: 凯斯 宾 王子 现时 资讯 发达 搜狐 电影...
3 娱乐 吴宇森 赤壁 赤壁大战 大战 不会 出现 现在 上集 希望 赤壁 不一 感觉 。” 刚刚...
4 娱乐 组 图 :《 多情 女人 痴情 男 陈浩民 现场 耍宝 陈浩民 外面 朋友 现在 搜狐 ...2.2 encoder编码:将文本类别的标签映射为数字
# 标签编码
from sklearn.preprocessing import LabelEncoder
labelEncoder = LabelEncoder()
train_df['label'] = labelEncoder.fit_transform(train_df['label'])
train_df.head()
>>>
label content
0 3 青蛇 造型 造型师 默认 新 红楼 红楼梦 额 妆 抄袭 图 看过 过电 电影 青蛇 不...
1 3 6.16 日剧 榜 < 最后 朋友 > 亮 最后 杀招 成功 登顶 最后 朋友 ...
2 3 超乎 想象 好看 纳尼亚 尼亚 传奇 2: 凯斯 宾 王子 现时 资讯 发达 搜狐 电影...
3 3 吴宇森 赤壁 赤壁大战 大战 不会 出现 现在 上集 希望 赤壁 不一 感觉 。” 刚刚...
4 3 组 图 :《 多情 女人 痴情 男 陈浩民 现场 耍宝 陈浩民 外面 朋友 现在 搜狐 ...2.3 label映射
# label映射
label_map ={}
for name, group in train_df.groupby(train_df.columns[0]):
print(name, len(group))
label_map[name] = "__label__" + str(name)
>>>
0 2000
1 2000
2 2000
3 2000
4 2000
5 2000
6 2000
7 2000
8 2000
9 2000
10 2000
11 2000
train_df["label"] = train_df["label"].map(lambda x: label_map[x])
train_df.head()
>>>
label content
0 __label__10 乐 网关 站 16 天内 内幕 揭秘 :“ 祸 在线 录制 搜狐 IT 消息 】“ 违规...
1 __label__6 涂鸦 纽约 一道 风景 风景线 来源 搜狐 文化 本文 来源 :《TimeOut 消费 ...
2 __label__1 关注 女性 关注 生活 状态 健康 状态 不仅仅 仅仅 女性 事情 本项 研究 旨在 以...
3 __label__4 北京 北京市 京市 市北 北部 新 项目 追踪 新 盘 数量 超过 过往 往年 北部 地...
4 __label__9 东 高端 车 源自 讴歌 否认 投产 欧版 雅阁 日前 业界 盛传 东风 本田 国产...v"__label__"是fastText中的默认标签格式,如果数据集使用其他格式需要在训练模型时修改label参数。
2.4 打乱数据集
# 打乱训练数据集
train_df = train_df.sample(frac=1).reset_index(drop=True)
train_df.head()
>>>
label content
0 __label__9 祁 玉 民 自主 品牌 忧虑 研发 应 国家 家主 主导 编者 编者按 祁 玉 民 ...
1 __label__11 权证 生态 正思 反思 华 建 强 市场 生态 中 主体 不可 不可或缺 或缺 互动 演...
2 __label__3 国内 乐坛 告急 八成 超女 快 男 下岗 歌手 放假 号称 拥有 天后宫 后宫 E...
3 __label__5 行政 职能 复习 分类 强化 专题 专题 1——16) 专题 十行 行政 行政监督 监督...
4 __label__10 6 月 6 日 中国 概念 概念股 近 全线 线下 下跌 分 众 大跌 15.49% ...2.5 保存数据为txt文档:方便fastText调用
# 保存为文本格式
train_df["fasttext_train"] = train_df["label"] + " " + train_df["content"]
train_df["fasttext_train"].to_csv("data/train_data.txt", index=False, header=False)3.训练并保存fastText模型
# 训练模型fasttext
import fasttext
ft_classifier = fasttext.train_supervised(input="data/train_data.txt", dim=100, epoch=10, lr=0.8, wordNgrams=2, loss='softmax', label="__label__")
# 保存模型
ft_classifier.save_model('models/ft_classifier.bin')3.1 fastText中参数解释(来源于官方文档):
$ ./fasttext supervised
Empty input or output path.
The following arguments are mandatory:
-input training file path
-output output file path
The following arguments are optional:
-verbose verbosity level [2]
The following arguments for the dictionary are optional:
-minCount minimal number of word occurrences [1]
-minCountLabel minimal number of label occurrences [0]
-wordNgrams max length of word ngram [1]
-bucket number of buckets [2000000]
-minn min length of char ngram [0]
-maxn max length of char ngram [0]
-t sampling threshold [0.0001]
-label labels prefix [__label__]
The following arguments for training are optional:
-lr learning rate [0.1]
-lrUpdateRate change the rate of updates for the learning rate [100]
-dim size of word vectors [100]
-ws size of the context window [5]
-epoch number of epochs [5]
-neg number of negatives sampled [5]
-loss loss function {ns, hs, softmax} [softmax]
-thread number of threads [12]
-pretrainedVectors pretrained word vectors for supervised learning []
-saveOutput whether output params should be saved [0]
The following arguments for quantization are optional:
-cutoff number of words and ngrams to retain [0]
-retrain finetune embeddings if a cutoff is applied [0]
-qnorm quantizing the norm separately [0]
-qout quantizing the classifier [0]
-dsub size of each sub-vector [2]
Defaults may vary by mode.
(Word-representation modes and use a default of 5.)skipgramcbow-minCount初学者对 maxn, minn, wordNgrams 这几个参数有点混淆,特意去查了一下,maxn 和 minn 是字符级别的拆分,相对与 wordNgrams 而言的,是字符级别的 Ngrams.
以英语语言为例:
charNgrams: "example"
👉minn=maxn=3: "exa", "xam", "amp", "mpl", "ple"
wordNgrams: I am happy.
👉Unigrams: "I", "am", "happy"
👉Bigrams: "I am", "am happy"
👉Trigrams: "I am happy"
以中文语言为例:
charNgrams: “我喜欢学习。”
👉 将单个字本身作为字符串char拆分:"["我", "喜", "欢", "学", "习"]
👉 将词语作为字符串char拆分:["我", "喜欢", "学习"]
wordNgrams:
👉 Unigrams: ["我", "喜", "欢", "学", "习"]
👉 Bigrams: ["我喜", "喜欢", "欢学", "学习"]
👉 Trigrams: ["我喜欢", "喜欢学", "欢学习"]
另外,从语言学的角度来看,英语、法语、西班牙语等表音文字通过字符组合来表示语言的音节或音素,这样的拆分是更容易让模型学习到 sub-word 信息的。而中文作为表意文字,其实是很难对字 word 级别的对象再进行拆分的, 2020年的Glyce模型提出了把汉字当成一个图片,然后通过 CNN 学习图片中文字的语义。
总之,两者的区别 maxn 和 minn 的处理对象是字符级别的 charNgrams,而 wordNgrams 处理对象是单词 word 级别。
另外在文献 Bag of Tricks for Efficient Text Classification 和 Enriching Word Vectors with Subword Information 里看到这样的命名方式:字符级别的子词 sub-word , 单词级别的 word embedding , 以及单词组合 wordNgrams. 正好再次说明 fasttext 相对于 word2vec 的改进,word2vec 处理的最小单位是 word,而 fasttext 处理的最小单位是 sub-word,解决了 word2vec 没能解决的 OOV(Out-Of-Vocabulary)问题。
注意到fasttext模型默认参数 minn 和 maxn 都是0,说明 fasttext 模型做文本分类时没有charNgrams,就是将单词作为整体分词。同时默认 wordNgrams=1 也是说明只考虑单个词,而不考虑词的组合。
实际上,字符级别的 charNgrams 能够帮助模型理解单词的内部结构,比如不同词性之间的联系以及处理拼写错误的情况。而单词级别的 wordNgrams 会注意到短语间的联系,对处理句子内部的语法结构更有帮助。
3.2 增加验证集评估模型
本次训练中采用了完全独立的训练数据集和测试数据集,没有验证集做交叉验证。
如果想划分验证集初步评估模型,可以将打乱后的训练集划分后测试。以下是一个简单的划分。
也可以采用交叉验证,但是不建议,因为fastText模型接受的input是一个txt文件,交叉验证就需要将每次的训练集和验证集都保存输出为文件。
# 将打乱后的数据集直接划分8:2
train_df["fasttext_train"] = train_df["label"] + " " + train_df["content"]
ft_train = train_df["fasttext_train"][:19211]
ft_test = train_df["fasttext_train"][19211:]
ft_train.to_csv("data/train_data.txt", index=False, header=False)
ft_test.to_csv("data/test_data.txt", index=False, header=False)
# 训练模型fasttext
import fasttext
ft_classifier = fasttext.train_supervised(input="data/train_data.txt")
# 验证数据集测试(n_examples, precision, recall)
result = ft_classifier.test("data/test_data.txt")4.加载测试数据集
# 加载测试数据
test_df = pd.read_csv("data/text_test.txt", sep="\t", header=None)
test_df.columns = ["label", "content"]
test_df.head()
>>>
label content
0 娱乐 组图:黄健翔拍时装大片 承认口无遮拦 2006年之前,他只是最好的体育节目主持人之一。200...
1 娱乐 奥运明星写真集锦曝光 展现健康时尚(图) 来源:人民网奥运明星奥运明星大满贯――属于最强者的...
2 娱乐 内地票房榜:《功夫熊猫》获全胜 带动内地影市 《功夫熊猫》首映周末逼4000万2006年1月...
3 娱乐 编者按: 昨天,央视紧急停播动画片《虹猫蓝兔七侠传》事件经报道后,引发了数十万网民的热烈大辩...
4 娱乐 第十一届上海国际电影节 金爵奖评委名单 [点击图片进入下一页]金爵奖评委陈冲陈冲(美籍华裔女...5.测试数据集 预处理
5.1 分词
# 测试数据集分词
test_df["content"] = test_df["content"].map(lambda x: word_cut(x, stopword_set))
print(test_df.head())
>>>
label content
0 娱乐 组 图 黄健翔 拍 时装 大片 承认 口 遮拦 2006 年 之前 最好 体育 体育...
1 娱乐 奥运 明星 明星写真 写真 写真集 集锦 曝光 展现 健康 时尚 图 来源 人民 人...
2 娱乐 内地 票房 票房榜 :《 功夫 熊猫 获 全胜 带动 内地 影 市 功夫 熊猫 首映...
3 娱乐 编者 编者按 昨天 央视 紧急 停播 动画 动画片 画片 虹 猫 蓝 兔 七 侠 传 事...
4 娱乐 第十 第十一 第十一届 十一 十一届 一届 上海 海国 国际 电影 电影节 金 爵 奖评...5.2 encoder编码
# Encoder映射
test_label_list = labelEncoder.transform(test_df['label'])
test_df['label'] = test_label_list
print(test_df.head())
>>>
label content
0 3 组 图 黄健翔 拍 时装 大片 承认 口 遮拦 2006 年 之前 最好 体育 体育...
1 3 奥运 明星 明星写真 写真 写真集 集锦 曝光 展现 健康 时尚 图 来源 人民 人...
2 3 内地 票房 票房榜 :《 功夫 熊猫 获 全胜 带动 内地 影 市 功夫 熊猫 首映...
3 3 编者 编者按 昨天 央视 紧急 停播 动画 动画片 画片 虹 猫 蓝 兔 七 侠 传 事...
4 3 第十 第十一 第十一届 十一 十一届 一届 上海 海国 国际 电影 电影节 金 爵 奖评...5.3 label映射
# 测试数据集label映射
label_map ={}
for name, group in test_df.groupby(test_df.columns[0]):
print(name, len(group))
label_map[name] = "__label__" + str(name)
>>>
0 1000
1 1000
2 1000
3 1000
4 1000
5 1000
6 1000
7 1000
8 1000
9 1000
10 1000
11 1000
test_df["label"] = test_df["label"].map(lambda x: label_map[x])
test_df.head()
>>>
label content
0 __label__3 组 图 黄健翔 拍 时装 大片 承认 口 遮拦 2006 年 之前 最好 体育 体育...
1 __label__3 奥运 明星 明星写真 写真 写真集 集锦 曝光 展现 健康 时尚 图 来源 人民 人...
2 __label__3 内地 票房 票房榜 :《 功夫 熊猫 获 全胜 带动 内地 影 市 功夫 熊猫 首映...
3 __label__3 编者 编者按 昨天 央视 紧急 停播 动画 动画片 画片 虹 猫 蓝 兔 七 侠 传 事...
4 __label__3 第十 第十一 第十一届 十一 十一届 一届 上海 海国 国际 电影 电影节 金 爵 奖评...5.4 保存数据为txt格式
# 保存为文本格式
test_df["fasttext_test"] = test_df["label"] + " " + test_df["content"]
test_df["fasttext_test"].to_csv("data/test_data.txt", index=False, header=False)6.调用模型进行测试
# 加载模型
ft_classifier = fasttext.load_model('models/ft_classifier.bin')
print(ft_classifier.labels)
>>>
['__label__1', '__label__9', '__label__6', '__label__4', '__label__3', '__label__5', '__label__2', '__label__8', '__label__11', '__label__0', '__label__7', '__label__10']6.1 模型在整个测试数据集上的整体性能测试
# 测试(n_examples, precision, recall)
result = ft_classifier.test("data/test_data.txt")
print(result)
>>>
(12000, 0.9053333333333333, 0.9053333333333333)6.2 混淆矩阵confusion matrix
from sklearn.metrics import confusion_matrix
predict_label_list = [int(y.strip("__label__")) for x in test_df["content"] for y in ft_classifier.predict(x)[0]]
pd.DataFrame(confusion_matrix(test_label_list, predict_label_list), columns=labelEncoder.classes_,index=labelEncoder.classes_ )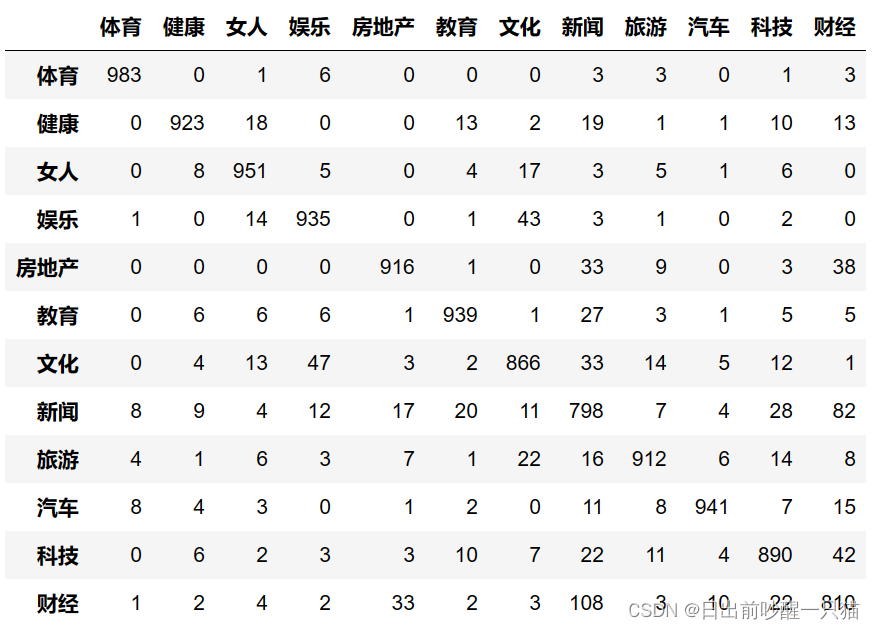
6.3 每个分类的Precision, Recall, f1, support
# precision_recall_fscore_support固定计算准确率的
import numpy as np
from sklearn.metrics import precision_recall_fscore_support
def ft_eval_model(test_label_list, predict_label_list, className_list):
# 计算每个分类的Precision, Recall, f1, support
p, r, f1, s = precision_recall_fscore_support(test_label_list, predict_label_list)
# 计算总体的平均Precision, Recall, f1, support
total_p = np.average(p, weights=s)
total_r = np.average(r, weights=s)
total_f1 = np.average(f1, weights=s)
total_s = np.sum(s)
res1 = pd.DataFrame({
u'Label': className_list,
u'Precision': p,
u'Recall': r,
u'F1': f1,
u'Support': s
})
res2 = pd.DataFrame({
u'Label': ['总体'],
u'Precision': [total_p],
u'Recall': [total_r],
u'F1': [total_f1],
u'Support': [total_s]
})
res2.index = [999]
res = pd.concat([res1, res2])
return res[['Label', 'Precision', 'Recall', 'F1', 'Support']]
ft_eval_model(test_label_list, predict_label_list, labelEncoder.classes_) 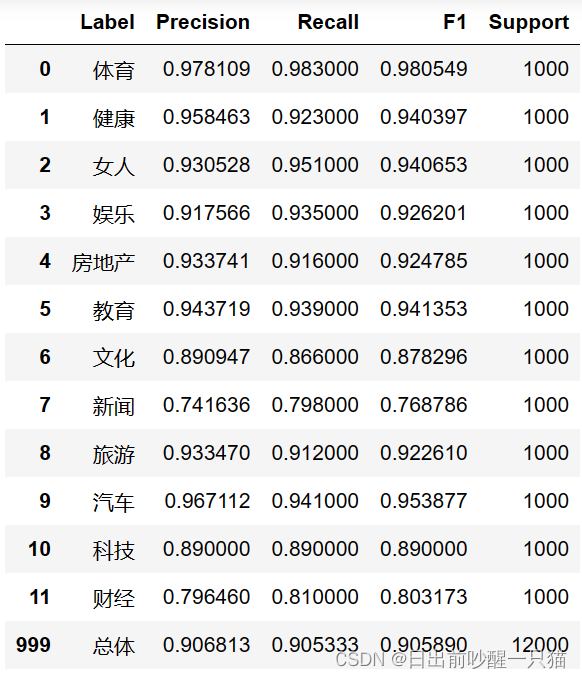
7.调用模型进行预测
打开网页随机选取一篇文章,先分词,再调用模型预测,最后从编码字典中选择对应的文字类别输出。
# 生成编码字典
classifier_dict = {
0: "体育",
1: "健康",
2: "女人",
3: "娱乐",
4: "房地产",
5: "教育",
6: "文化",
7: "新闻",
8: "旅游",
9: "汽车",
10: "科技",
11: "财经"
}
text1 = ["作为全球投资的重要目的地,中国展现出了引资韧性与吸引力。来华考察调研、展业兴业的外资企业数量持续增长,许多外资巨头以真金白银为中国经济发展投下“信任票”。知名跨国药企罗氏制药宣布加码在华投资;苹果的亚洲最大零售店在上海开门迎客;大众汽车集团(中国)宣布投资25亿欧元,强化在华研发实力;宝马集团计划增资200亿元,推动在华工厂大规模升级和技术创新……还有一批具有专业特色的外资金融机构加大布局,“落子”中国:国际主流卡组织万事达卡与网联设立的万事网联公司开业,成为我国第三家银行卡清算机构;外商独资的渣打证券正式展业、法巴证券获批设立;外商独资的安联基金开业……数据显示,一季度,在去年同期创历史的高基数影响下,我国吸引外资规模同比有所下降,但新设外资企业达1.2万家,同比增长了20.7%。新设企业数量增长有风向标作用,有望对未来到资形成一定支撑。“全国新设立外商投资企业数量持续高速增长,反映出跨国企业投资中国的热情较高。实际使用外资金额虽同比下降,但与去年四季度相比有所改善。”中国银行(4.520, -0.01, -0.22%)研究院研究员王静表示。我国引资结构也在持续优化。随着新质生产力发展,高新技术产业正成为对外资的“新引力”。数据显示,一季度,我国高技术制造业引资达377.6亿元,占全国引资比重较去年同期提高2.2个百分点。我国对外资的“磁吸力”从何而来?专家和海外人士认为,我国的超大规模市场、充足的人才资源、完备的产业门类体系、较强的规模经济效应、持续优化的营商环境,以及快速发展的新技术、新产业(74.390, -1.26, -1.67%)、新业态等,都是吸引外国投资者的重要加分项。首先,超大规模市场为吸引外资提供基础优势。“中国对外资最大的吸引力是市场。”意大利中国商业发展论坛主席伊万·卡迪洛表示,中国平均每24小时就有2.7万多家新企业注册、8万多辆汽车下线、近50亿美元的产品在网上售出、约3亿个包裹被送达,看到这些数字就应当明白中国市场的重要性、潜力和规模。其次,中国经济长期向好的基本面没有发生变化。投资中国就是共享中国发展红利,投资中国、加码中国、深耕中国的外资企业也将赢在中国。近期,南非联合银行在北京设立了外商独资企业泛非(北京)咨询有限公司。南非联合银行集团国际业务首席执行官时撷若接受上海证券报记者采访时表示,南非联合银行集团对中国市场的兴趣源于中国与非洲之间密不可分的经济联系及贸易往来。设立子公司的举措,将为集团带来大量商业机会并促进其非洲业务增长。最后,我国持续推进高水平对外开放,营商环境持续改善,也是吸引外资的重要因素。"]
# 预测
predict_text = ft_classifier.predict(word_cut(text1[0], stopword_set))
label = int(predict_text[0][0].replace('__label__', ''))
print(classifier_dict[label])
>>>
财经8.问题记录
总结来看,整个文本分类过程中最重要的数据预处理阶段和模型训练中参数的选择,其中对于训练数据集和测试数据集的预处理不能缺少的就是分词过程,encoder编码和label映射都是为了方便后续处理,没有这些后面相应修改细节就可以。而在参数选择上,影响最大的应该当属 epoch 和 lr,第三部分展示具体细节。
三、fastText优化
1.手动优化参数
根据官方文档,优化方向为数据预处理(大小写),调整epoch, lr, n-grams.
With a few steps, we were able to go from a precision at one of 12.4% to 59.9%. Important steps included:
preprocessing the data ;
changing the number of epochs (using the option , standard range -epoch[5 - 50]) ;
changing the learning rate (using the option , standard range -lr[0.1 - 1.0]) ;
using word n-grams (using the option , standard range ).-wordNgrams[1 - 5]采用默认参数的准确率
import fasttext
ft_classifier = fasttext.train_supervised(input="data/train_data.txt", dim=100, epoch=5,lr=0.1, wordNgrams=1, loss='softmax')
result = ft_classifier.test("data/test_data.txt")
>>>
(12000, 0.7704166666666666, 0.7704166666666666)只调整 epoch 从5到25,准确率获得明细提升~0.88
只调整学习率 lr 从0.1到1,准确率获得明细提升~0.89
只调整 wordNgrams=2,准确率下降一半~0.44
同时调整 lr=1 和 epoch=25,准确率上升至0.90508,此时再改变 wordNgrams=2 准确率会提升~0.916.
此时改变损失函数的计算方式为 hierarchical softmax,epoch=25,lr=1, wordNgrams=3, loss='hs',计算效率提升,但是会稍微牺牲准确率~0.89725。若将损失函数改为更适合多分类问题的 one-vs-all(ova),准确率~0.91825.
另外,改变词向量的维度 dim 的影响微乎其微。
综上所述,epoch 和 lr 是影响模型最重要的两个参数,lr=1可能导致模型难以收敛,不过这里测试数据集与其完全独立也获得了较高结果,因此可以接受这种调整,手动调整参数的最佳参数是,dim=100, epoch=25,lr=1, wordNgrams=3, loss='ova',精确度结果是0.91825.
2.网格搜索最优参数:
对于这种参数空间较大的模型,可以不用手动调整参数,采用网格搜索的方式找到最优参数组合,如网格搜索 (Grid Search),随机搜索 (Random Search)或贝叶斯优化 (Bayesian Optimization)。下面给出一个网格搜索的简单例子,其中评价指标选择了准确度accuracy,也可以改用precision, recall或f1等。
import fasttext
from sklearn.model_selection import ParameterGrid
from sklearn.metrics import accuracy_score
# 加载文件,保存内容和标签
def load_data(file_path):
labels = []
texts = []
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
label, text = line.strip().split(' ', 1)
labels.append(label)
texts.append(text)
return labels, texts
# 定义一个函数,用于加载模型进行测试并计算准确率
def evaluate_model(model, test_file):
true_labels, texts = load_data(test_file)
pred_labels = [model.predict(text)[0][0] for text in texts]
accuracy = accuracy_score(true_labels, pred_labels)
return accuracy
# 参数范围
param_grid = {
'lr': [0.1, 0.5, 1],
'dim': [50, 100, 150],
'ws': [3, 5, 7],
'epoch': [5, 10, 25],
'minCount': [1, 3, 5],
'neg': [5, 10, 15],
'wordNgrams': [1, 3, 5],
'loss': ['ns', 'hs', 'softmax', 'ova']
}
grid = ParameterGrid(param_grid)
best_accuracy = 0
best_params = None
test_file = 'data/test_data.txt'
# 将每次训练参数与准确率保存
with open('training_log.txt', 'w') as file:
for params in grid:
file.write(f"Training with parameters: {params}\n")
print(f"Training with parameters: {params}")
model = fasttext.train_supervised(input='data/train_data.txt', **params)
accuracy = evaluate_model(model, test_file)
file.write(f"Accuracy: {accuracy:.4f}\n")
print(f"Accuracy: {accuracy:.4f}")
if accuracy > best_accuracy:
best_accuracy = accuracy
best_params = params
# 输出最佳参数和准确率
with open('training_log.txt', 'a') as file:
file.write(f"Best accuracy: {best_accuracy:.4f} with parameters: {best_params}\n")
print(f"Best accuracy: {best_accuracy:.4f} with parameters: {best_params}")3.n-grams的选择对模型的影响
训练模型中,还可以调整最小词长度 minn 和最大词长度 maxn 范围来使更多长度的字词长度包含在其中,如 minn=1, maxn=5,不过对这个任务的精确度影响不大~0.894.

















 863
863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









