






前言
在之前的文章中我们分别介绍了:
如果自己做一个OCR的工具:
PIC2WORD:一个很简单的在线的图片转文字(OCR)工具
如何将视频转成图片:
在视频本地化过程中使用ffmpeg提升效率
在视频本地化过程中使用ffmpeg提升效率(二)视频转文字
了解完以上内容后,我们在实践中遇到一个新的问题:

视频来源:
https://www.weibo.com/u/6060307497?tabtype=video&layerid=4579407136031075
【睡前消息203:长租公寓、打工人,爷的青春回来了】5:05
在上面这个视频截图中,我们不仅看到了字幕,同时也看到了许多其他的文字,如果将上面这个图送到百度的文字识别API中,会得到以下结果:
序号 内容
1 微博
2 B站2020年度弹幕
3 @观视频工作室
4 no爷青回
5 No2.武汉加油
6 No3.有内味了
7 No4.双厨狂喜
8 No5.禁止套娃
9 2020年网络年度关键词
10 B站刚刚公布了2020年的年度弹幕
11 观视频
虽然我们看到了被识别出来的字幕,但是非字幕也识别了出来,所以我们必须要想办法将字幕那部分的文字单独提取出来。
这就是今天这篇帖子要分享的主要内容。
正文
一、百度通用文字识别API
访问地址来源:
https://ai.baidu.com/tech/ocr/general
这次我们依然使用的是免费的百度API。百度提供的通用文字识别API可以识别20种语言,每天有好几万次的免费调用,所以足够我们这种小体量的使用场景。
它目前包括四种版本:

对比起来,标准版是最初级的,支持10多种语言,而高精度版则支持更多语种,字库也更大,能识别生僻字。
不过,无论是标准版还是高精度版,都只能返回识别结果,这个还不能满足我们的需求,因为我们只想要截图中的字幕部分对应的文字。
所以我们可以考虑标准含位置版或高精度含位置版。
现在我们可以打开点击上述链接中的“立即使用”:
然后使用百度账号登录,并创建一个“应用”:

创建之后会得到API Key和Secret Key:

接下来就是去看技术文档和下载SDK:

我还是一如既往的使用PHP来做演示。
PHP的SDK可以在下面这个链接下载:
https://ai.baidu.com/sdk#ocr
下载前可以在开发环境的根目录下创建一个空白的文件夹,然后把SDK放到这个SDK里:
我们只需要lib文件夹和AipOcr.php文件即可:

这个操作在官方文档中也有介绍:

来源:
https://cloud.baidu.com/doc/OCR/s/hkibizxhx
我把这个截图放过来的主要目的是:其实我写的这些人家官方在文档里写得很清楚了。
二、引入百度OCR API并识别图片中的内容
1)引入API
有了API之后,就是引入API,引入的方法是创建一个index.php文件:
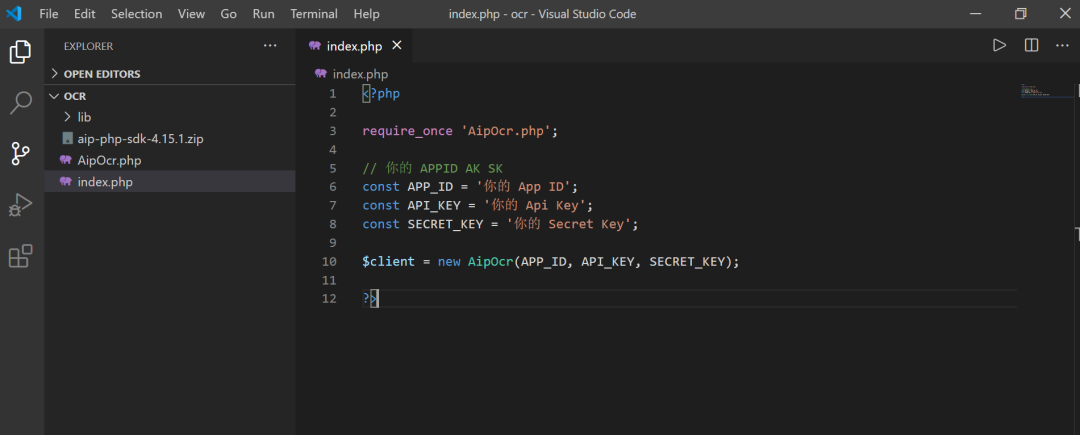
并将官方文档中的代码贴进去:

以下是代码:
index.php
<?php require_once 'AipOcr.php';// 你的 APPID AK SKconst APP_ID = '你的 App ID';const API_KEY = '你的 Api Key';const SECRET_KEY = '你的 Secret Key';$client = new AipOcr(APP_ID, API_KEY, SECRET_KEY);?>然后把之前创建应用时获得的APP ID、APP Key和Secret Key都贴进去。
这样就算成功引入百度的OCR API了。
接下来是继续看文档,尤其是看通用文字识别(含位置信息版)部分的代码:

来源:
https://cloud.baidu.com/doc/OCR/s/gkibizxd5
这段内容看着很霸气,但操作起来很简单。
首先,我们把图片放到根目录下我们刚刚创建的文件夹中:

然后把以下代码粘贴到index.php中:
<?php require_once 'AipOcr.php';// 你的 APPID AK SKconst APP_ID = '你的 App ID';const API_KEY = '你的 Api Key';const SECRET_KEY = '你的 Secret Key';$client = new AipOcr(APP_ID, API_KEY, SECRET_KEY);$image = file_get_contents('example.jpg');// 如果有可选参数$options = array();$options["recognize_granularity"] = "big";$options["language_type"] = "CHN_ENG";$options["detect_direction"] = "true";$options["detect_language"] = "true";$options["vertexes_location"] = "true";$options["probability"] = "true";// 带参数调用通用文字识别(含位置信息版), 图片参数为本地图片$result = $client->general($image, $options);?>仔细一对比会发现,官方文档提供的代码是针对好几种场景的,比如你的图片是来自网络的图片还是来自本地的图片。我们这里因为用的本地图片,所以就使用前面几行代码就可以了。
2)获取图片内容
在上面的代码中我们其实看不出来图片内容获取之后放在了哪里,那是因为我们没有创建变量来获取图片内容。因此,我们要修改一下第24行代码,变成:
$result = $client->general($image);
并且加一行:
print_r($result);
来显示获取到的结果。
代码如下:
<?php require_once 'AipOcr.php';// 你的 APPID AK SKconst APP_ID = '你的 App ID';const API_KEY = '你的 Api Key';const SECRET_KEY = '你的 Secret Key';$client = new AipOcr(APP_ID, API_KEY, SECRET_KEY);$image = file_get_contents('example.jpg');// 如果有可选参数$options = array();$options["recognize_granularity"] = "big";$options["language_type"] = "CHN_ENG";$options["detect_direction"] = "true";$options["detect_language"] = "true";$options["vertexes_location"] = "true";$options["probability"] = "true";// 带参数调用通用文字识别(含位置信息版), 图片参数为本地图片$result = $client->general($image, $options);print_r($result);?>这个时候去浏览器里访问这个index.php文件:

(注:
请务必要启动你的编程环境;务必将你的应用信息填写到代码中;务必在浏览器中输入正确的访问地址,本文不再介绍这些步骤的完成方法。)
这个时候你会看到密密麻麻的内容,并且决定关掉浏览器,回到自己正常的生活中去。
对于编程初学者来说,其实很怕看到这样的场景,因为许多初学者对数组的认识还不是那么深刻,不知道自己才能从数组中读取数据。
最简单的方法就是右键点击浏览器,选择查看网页源代码,这个时候看到的就是另外一种风景了:
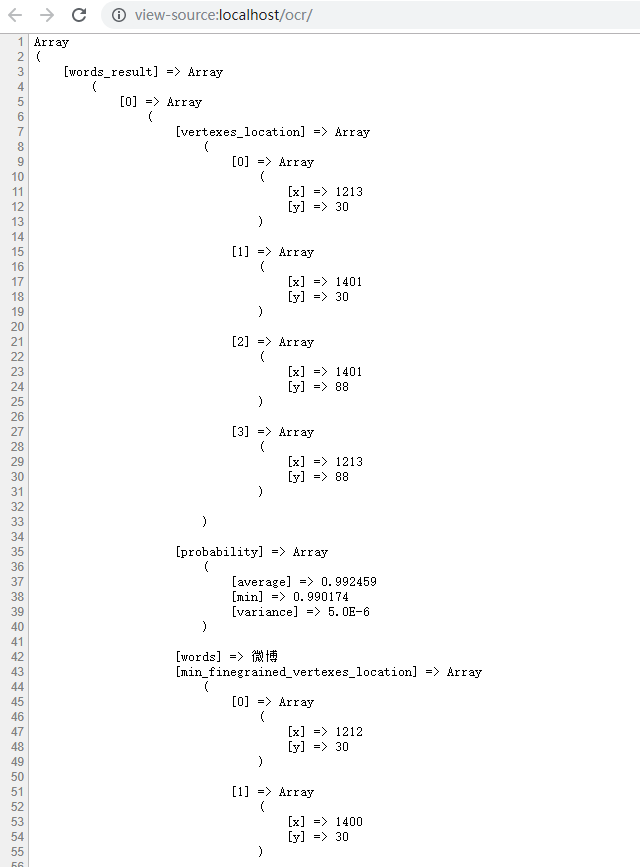
我们此时要去看一下文档,看看返回的结果中都包含了哪些信息:
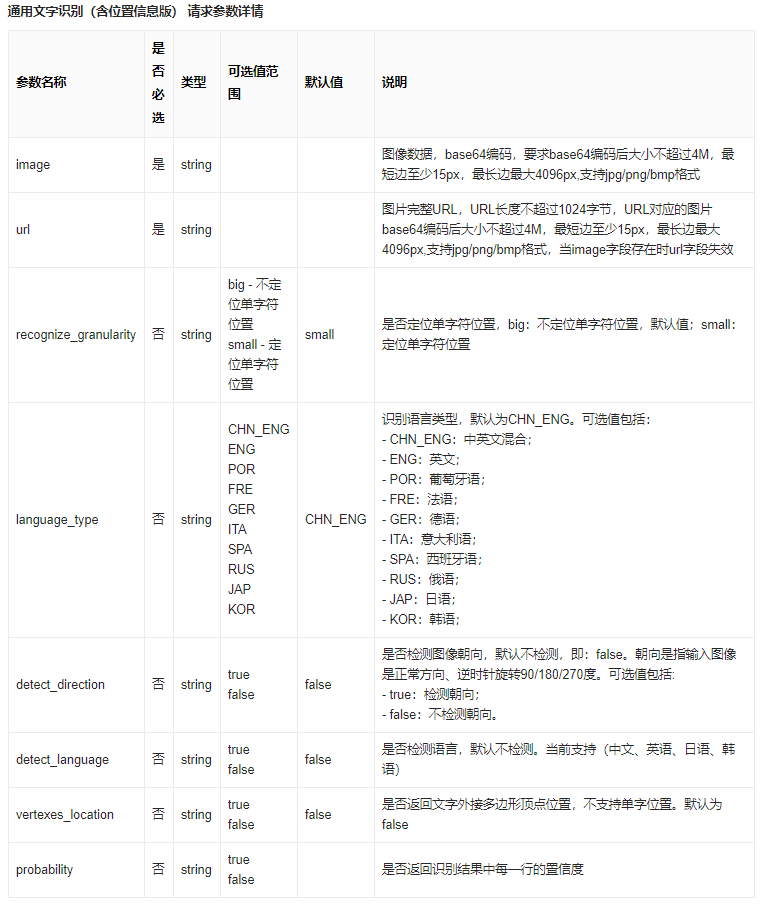
这里面详细介绍了所有返回的参数。
我们以计划提取的字幕部分的文字所在的代码为例:
[9] => Array ( [vertexes_location] => Array ( [0] => Array ( [x] => 178 [y] => 704 ) [1] => Array ( [x] => 908 [y] => 704 ) [2] => Array ( [x] => 908 [y] => 765 ) [3] => Array ( [x] => 178 [y] => 765 ) ) [probability] => Array ( [average] => 0.995323 [min] => 0.938568 [variance] => 0.000209 ) [words] => B站刚刚公布了2020年的年度弹幕 [min_finegrained_vertexes_location] => Array ( [0] => Array ( [x] => 178 [y] => 703 ) [1] => Array ( [x] => 907 [y] => 703 ) [2] => Array ( [x] => 907 [y] => 764 ) [3] => Array ( [x] => 178 [y] => 764 ) ) [location] => Array ( [top] => 704 [left] => 178 [width] => 733 [height] => 63 )在这段代码中,我们其实主要看两个部分:
[words] => B站刚刚公布了2020年的年度弹幕和
[location] => Array ( [top] => 704 [left] => 178 [width] => 733 [height] => 63 )这个就是这张截图中字幕部分的文字内容和位置信息。
在官方文档中还有这样一段描述:
| +location | 是 | array | 位置数组(坐标0点为左上角) |
| ++left | 是 | number | 表示定位位置的长方形左上顶点的水平坐标 |
| ++top | 是 | number | 表示定位位置的长方形左上顶点的垂直坐标 |
| ++width | 是 | number | 表示定位位置的长方形的宽度 |
| ++height | 是 | number | 表示定位位置的长方形的高度 |
可见,我们是这样来标记字幕位置的:

以字幕区域左上角的XY轴坐标来定位这个区域,Left就是X轴的值,Top就是Y轴的值。
根据上面的返回结果我们知道,上面这个截图中字幕区域的XY值分别是:178和704。
但如果你仔细去观察,你会发现:明明这个“B站”的位置在左下角,Y轴的值不可能那么大呀?
这是因为:百度的OCR API定义的原点为左上角:

这样是不是就说得通了?
知道了Left和Top后,我们再来看Width和Height,这两个值就比较好用了,我们如果知道了字幕的最大宽度和高度,就能准确定位出字幕的区域。即便我们的字幕是中英双语的,也能分别定位中文字幕和英文字幕。
下面,我们写一段代码,通过循环和判断来将字幕定位出来,如下:
<?php require_once 'AipOcr.php';// 你的 APPID AK SKconst APP_ID = '你的 App ID';const API_KEY = '你的 Api Key';const SECRET_KEY = '你的 Secret Key';$client = new AipOcr(APP_ID, API_KEY, SECRET_KEY);$image = file_get_contents('example.jpg');// 如果有可选参数$options = array();$options["recognize_granularity"] = "big";$options["language_type"] = "CHN_ENG";$options["detect_direction"] = "true";$options["detect_language"] = "true";$options["vertexes_location"] = "true";$options["probability"] = "true";// 带参数调用通用文字识别(含位置信息版), 图片参数为本地图片$result = $client->general($image, $options);//print_r($result);foreach($result["words_result"] as $words){ if($words["location"]["left"] >= 178 and $words["location"]["top"] >= 704) { echo $words["words"]; }}?>此时再去访问index.php页面:
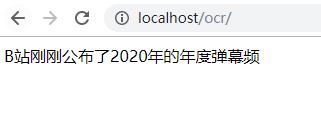
我们会看到原截图字幕部分的内容展示了出来(先忽略最后的那个“频”字儿),其他内容则没有。
仔细看上面的代码,会发现:
所有被识别出来的文字及其相关信息实际上都在$result["words_result"]这个数组里面,我们使用foreach循环来遍历这个数组,并将数组中的每一个元素看作是变量$words,然后根据location中的left和top的值来决定要选取哪一个元素,并将这个元素中words对应的文字展示出来。
为了测试这段代码的有效性,我们我们再次从原视频中截取一个图:

然后再次运行index.php,得到下面这个结果:
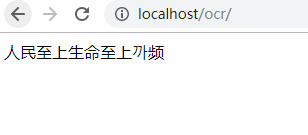
我们发现,不光“人民至上生命至上”显示出来了,后面的“观视频”也显示出来了,这就表明:我们不能仅用字幕的左上角来确定位置,还得把字幕的右上角的位置拿来,而这个右上角则是根据左上角的值以及字幕的宽度来决定的,我们需要在X轴上加上字幕的宽度来获得右上角坐标的X值。
而这里的宽度设为多少合适呢?
这个就要根据整个视频中最长的那个位置。
不过,在上面这个视频截图中,我们知道“观视频”其实是固定的logo,所以我们用它的左上角的XY坐标也可以做一个判断。
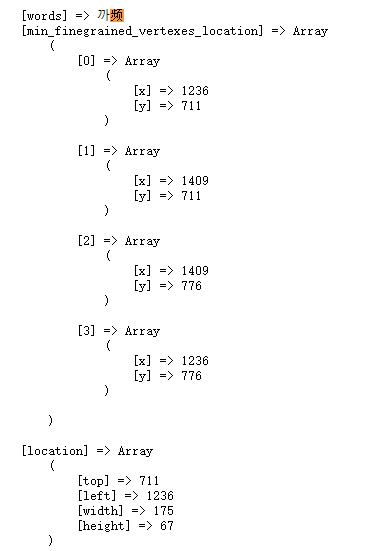
我们发现这个logo的左上角的值是1236,所以可以这样修改一下代码:
foreach($result["words_result"] as $words){ if($words["location"]["left"] >= 178 and $words["location"]["left"] < 1236 and $words["location"]["top"] >= 704) { echo $words["words"]; }}即:$words["location"]["left"] >= 178 and $words["location"]["left"] < 1236
在设置条件的时候设置一个范围即可。
现在再运行index.php:
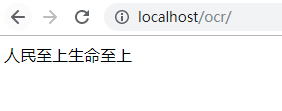
就只有字幕中的内容显示出来了。
我们再试一下前面那副图:
我们会发现“频”字儿还在,这个时候是需要调整一下1236那个值,将其再缩小一点就可以了,如:1100。
再次访问index.php:
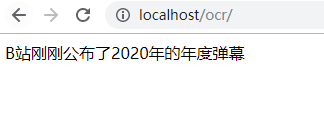
后面的“频”字就没有了。
三、思考
以上就是将视频的字幕单独识别成文字的过程。需要特别注意的是:
1)我在本文中展示的两幅截图都是我自己手动截图的,所以截出来的图中的字幕的具体位置会有变化,如果你自己亲自测试,需要根据所用的截图中实际字幕的XY值来调整代码,不要直接参考上述代码中的XY值。
2)请结合ffmpeg来获得截图,不要手动截图。
3)有时候我们在使用ffmpeg截图时会看一次截取很多帧出来,因此会出现重复的字幕内容,如何将他们合并呢?
希望大家可以自己去尝试一下。














 2055
2055











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









