






文本风格转换-情感
论文链接:
https://arxiv.org/abs/1805.05181
代码连接:
https://github.com/lancopku/unpaired-sentiment-translation
论文题目:
Unpaired Sentiment-to-Sentiment Translation A Cycled Reinforcement Learning Approach

轻音乐喜欢可以边听边阅读

引言
上次分享了一篇关于图像风格转换的文章,于是想找找自然语言处理这边有没有有趣的文章,果然,很多学者在研究关于文本风格转换的课题,笔者打算先从情感转换开始,逐步介绍文本风格转换的内容。这次分享的文章用循环强化学习实现无平行语料的情感转换,所谓平行语料,是由原文文本及其平行对应的译语文本构成的双语/多语语料库,其对齐程度可有词级、句级、段级和篇级几种。本文提出了一种新的方法用于无平行语料的情感转换问题。当前大多数的模型存在普遍的问题,在进行情感转换的同时,不能保证内容的不变。例如当把“The food is delicious”这句话从正向情感迁移到负向情感时,会得到“What a bad movie”。主语从food变成movie。其原因是内容和情感在同一个隐向量中,所有信息混在一起难以解释。因为没有平行语料,非情感的语义信息难以不受影响。
模型结构
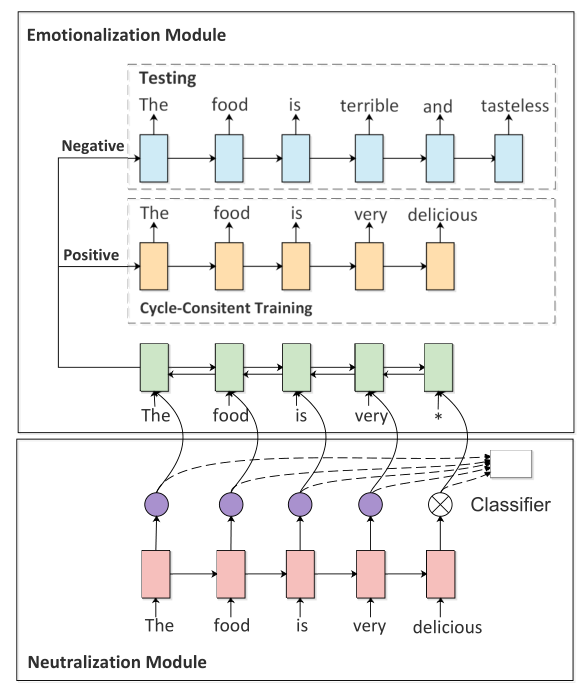
图1 模型图
图1是本文的模型,分为两个模块,图下方的去情感模块,和图上方的情感模块,去情感模块主要是去除句子的情感词,使句子中性化,情感化模块给中性句子加上情感词,使其情感化。
主要模块介绍
去情感模块:循环强化学习要求模型有初始学习能力,因此文章一个预训练方法来让去情感模块学会判断非情感词。预训练使用了基于自注意力机制的情感分类器,将注意力权重用作监督信号,通常情感词的获得的权重大,而中性词获得的权重小。根据连续的权重提取非情感词,将权重离散化为0和1。首先计算出每个句子的平均权重值,如果某个词的权重小于这个值,则其离散值为设定1,否则为0。情感词权重为1,非情感词为0。将这个结果可以帮助去掉情感。试验结果表明情感分类准确率达到89%-90%,可以认为分类器充分捕捉了每个词的情感信息。
情感化模块:文章采用 encoder-decoder框架,设置两个decoder,一个用于添加正向情感,一个添加负向情感。具体情感添加根据任务中的目标情感而定。
循环强化学习过程

图2 伪代码
大致过程如下,设置初始值,根据极大似然估计预训练去情感模块和情感化模块,接下来做一个循环,通过去情感模块去除句子的情感词,使其中性化,然后情感化模块根据原始情感和语义内容重构原句,这样可以让情感模块在有监督的情况下学习增加情感。计算情感模块的梯度:
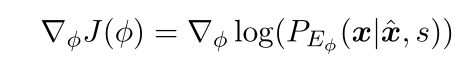
计算奖励函数R1:根据情感化模块生成情感相反的句子,计算奖励函数R2,计算整体奖励R=R1+R2计算去情感模块的梯度。
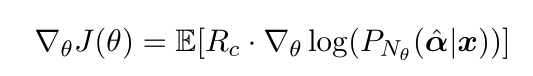
重复循环直至收敛。
激励函数
由于文本的离散性,RL 成功与否严重依赖于奖励函数的设计。作者提出了两个奖励函数。confidence 和 BLEU。Confidence是 self-attention 的情感分类器来评价是否符合目标情感。BLEU评价内容的保存程度。尤其是 BLEU,主要是针对作者开头提出的多数模型情感转换丢失原句语义信息的问题。最终的奖励函数为
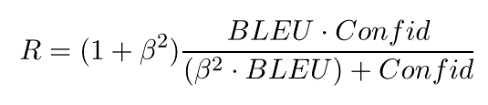
其中
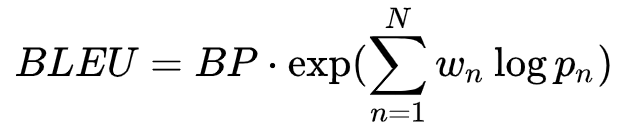
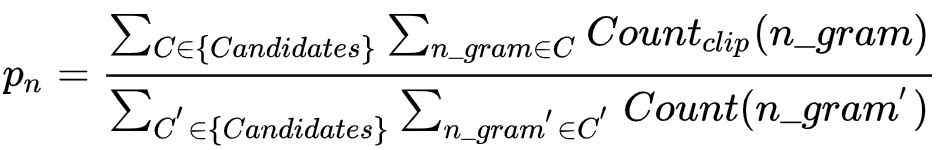
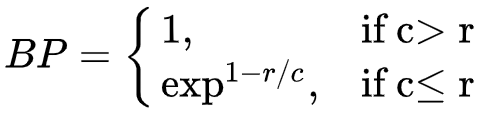
BLEU是nlp中常用的评价指标,后文将会简单介绍。
BLEU
BLEU
实现方法
BLEU是将产生的或者转换后的句子与人工生成的参考译文相比较,越接近,候选译文的正确率越高。实现方法:统计同时出现在系统译文和参考译文中的n 元词的个数,最后把匹配到的n元词的数目除以系统译文的n元词数目,得到评测结果。
针对某个待评测的转换句子,首先统计每个单词在所有参考译文中出现次数的最大值Max_Ref_Count,然后,统计该单词在转换句子中出现的总次数Count,取Count和Max_Ref_Count两者中小的一个,即
Countclip=min(Count, Max_Ref_Count)
这样保证了每个转换句子中的单词计数不会超过该词在某个参考译文中出现次数的最大值。
把转换句子中所有单词的Countclip值累加起来,得到Total_Countclip,即待评测的转换句子中出现在参考译文中的单词个数,最后,用Total_Countclip除以转换句子中全部单词的个数。
考虑到在修正的n 元语法精度计算中,随着n值的增大精度值几乎成指数级下降,因此,BLEU方法中采用了修正的n 元语法精度的对数加权平均值,相当于对修正的精度值进行几何平均,n 值最大为4。
BLEU
举例计算-Pn

如上面的例子中:
以1-gram为例,统计候选译文中每个单词出现的个数,然后统计在参考译文中每个单词出现的次数,如单词the,统计如下表:

然后累加每个单词的Countclip,将候选译文中每个单词出现的次数累加作为分母,得到P1: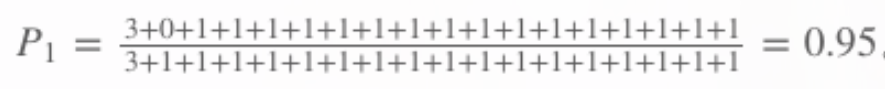
类似的可以求得2-gram 3-gram 4-gram对应的Pn。
另外也可以这样理解计算Pn,候选译文中单词1~6, 8~11, 14~15, 17~18 均出现在参考译文1中,第7个单词出现在参考译文2中,第12、16个单词均出现在译文2和3中。只有第13个词没有出现在任何译文中。因此,一元语法精确度为:17/18。如果考虑bi-gram {(it is), (is a), (a guide) …},那么,修正的2元语法的精度为:10/17。以此类推。
对于含多个句子的测试文本,以句子为单位分别计算n-gram 的匹配情况,然后,累计所有翻译句子修正后的n-gram 计数,及测试集的所有n-gram 计数,二者相除,便得到开始的Pn计算公式:
BLEU
举例计算-BP
接下来还要考虑Bp计算的值,因为如果一个机器翻译系统只翻译最可靠的词汇,译文句子就可能比较短,按上述方法计算出的精度值就会较高。所以,需要进一步考虑候选译文的句子长度对计算评分的影响。
如本例,候选译文长度为18,参考译文分别为16,18,16。
所以c=18" role="presentation" style="max-width: none; display: inline; line-height: normal; text-align: left; word-spacing: normal; float: none; direction: ltr; max-height: none; min-width: 0px; min-height: 0px;">c=18(候选翻译句子长度),r=18" role="presentation" style="font-size: 14px; max-width: none; line-height: normal; text-align: left; word-spacing: normal; float: none; direction: ltr; max-height: none; min-width: 0px; min-height: 0px;">r=18(参考翻译中选取长度最接近候选翻译的作为r)
故BP=e0=1" role="presentation" style="line-height: normal; word-spacing: normal; float: none; direction: ltr; max-height: none; min-width: 0px; min-height: 0px; max-width: 100%; box-sizing: border-box; overflow-wrap: break-word; font-size: 14px; font-family: Lato, "PingFang SC", "Microsoft YaHei", sans-serif; border-style: initial; border-color: initial;">BP=e0=1
BLEU
计算整合
最后将各部分值进行整合得到BLEU的得分。
这里wn可以取:w1=w2=w3=w4=0.25,也就是Uniform Weights
本文图片均选自论文:
Unpaired Sentiment-to-Sentiment Translation A Cycled Reinforcement Learning Approach
BLEU介绍部分参考:
1.宗成庆:《自然语言处理》讲义,第11 章(2020)
2.https://www.cnblogs.com/shona/p/12176501.html
封面内容取自:https://www.cnblogs.com/shona/p/12176501.html

我希望躺在向日葵上,即使沮丧,也能朝着阳光。因为我知道,人生不如意十有八九。我会难过,会暂时停下前进的脚步,也有绝望的时候。可我心里永远保存着一缕阳光,因为我躺在向日葵上。真正的强者不是不会流泪,而是一边流泪一边往前奔跑。只要信念尚存,希望一定在。毕竟,人活的是一种精神。

作者:韩锋
















 2583
2583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









