






机器之心报道
 从以下伪代码不难看出,多头注意力机制在数学上等效于,使用两个因子的乘积分别表示 GBMA 中的各参数张量。
从以下伪代码不难看出,多头注意力机制在数学上等效于,使用两个因子的乘积分别表示 GBMA 中的各参数张量。
参与:思、肖清、一鸣
在 Transformer 完全采用注意力机制之后,注意力机制有有了哪些改变?哈希算法、Head 之间的信息交流都需要考虑,显存占用、表征能力都不能忽视。

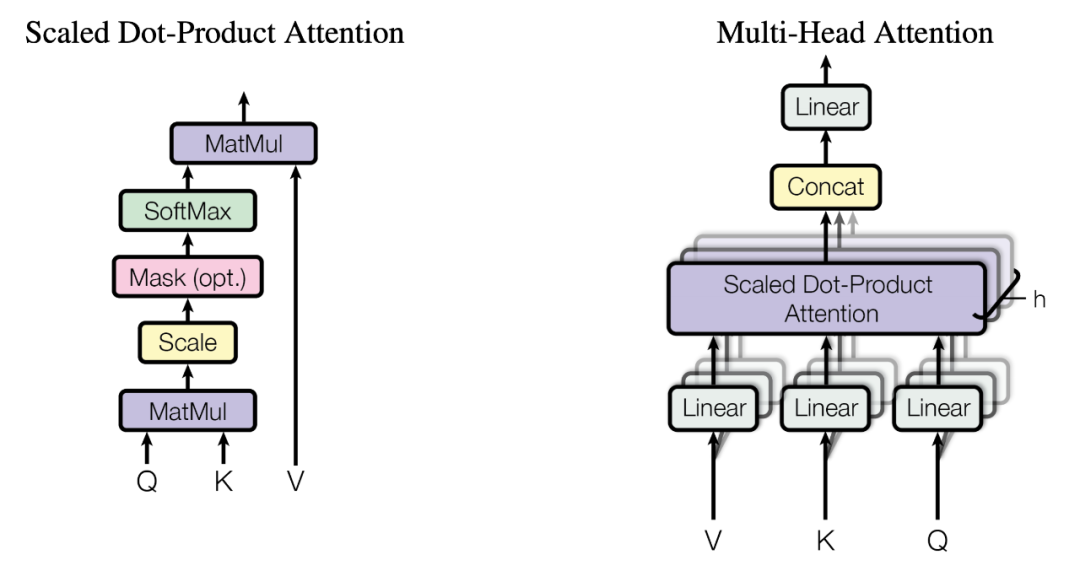
论文:Attention Is All You Need
论文链接:https://arxiv.org/abs/1706.03762 (https://arxiv.org/abs/1706.03762)
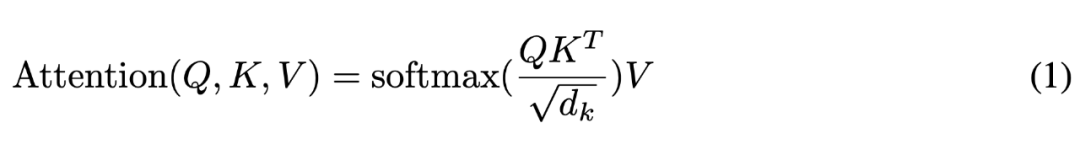

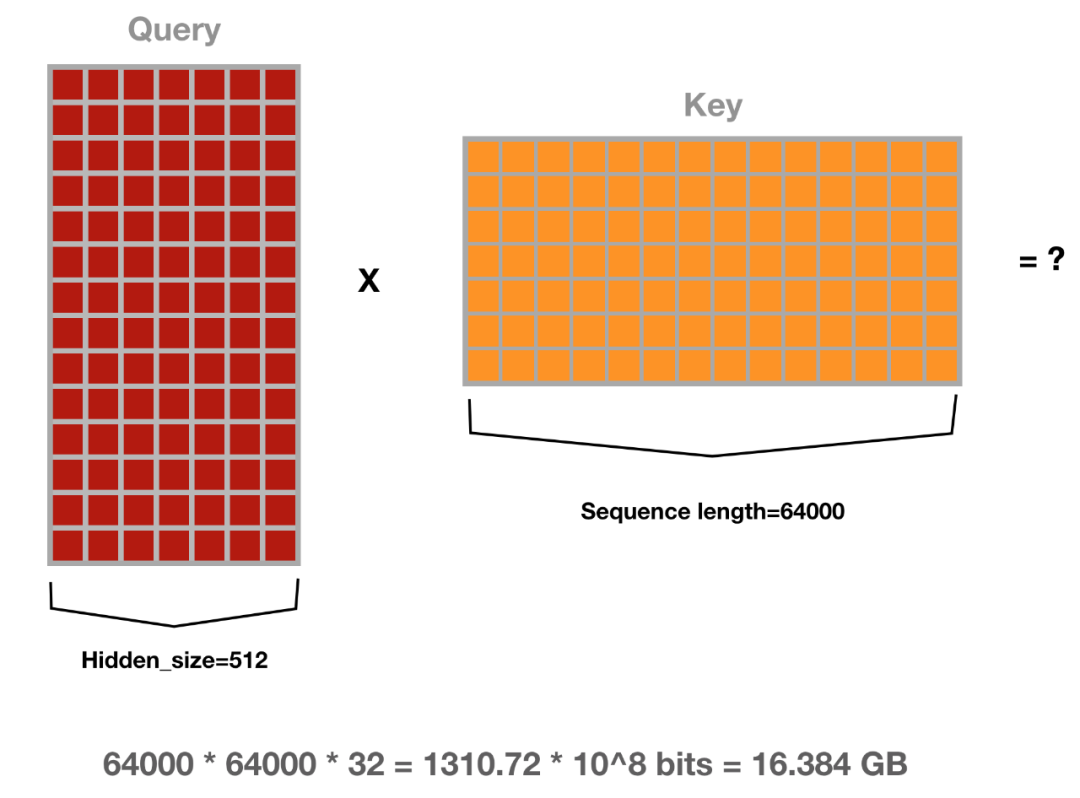
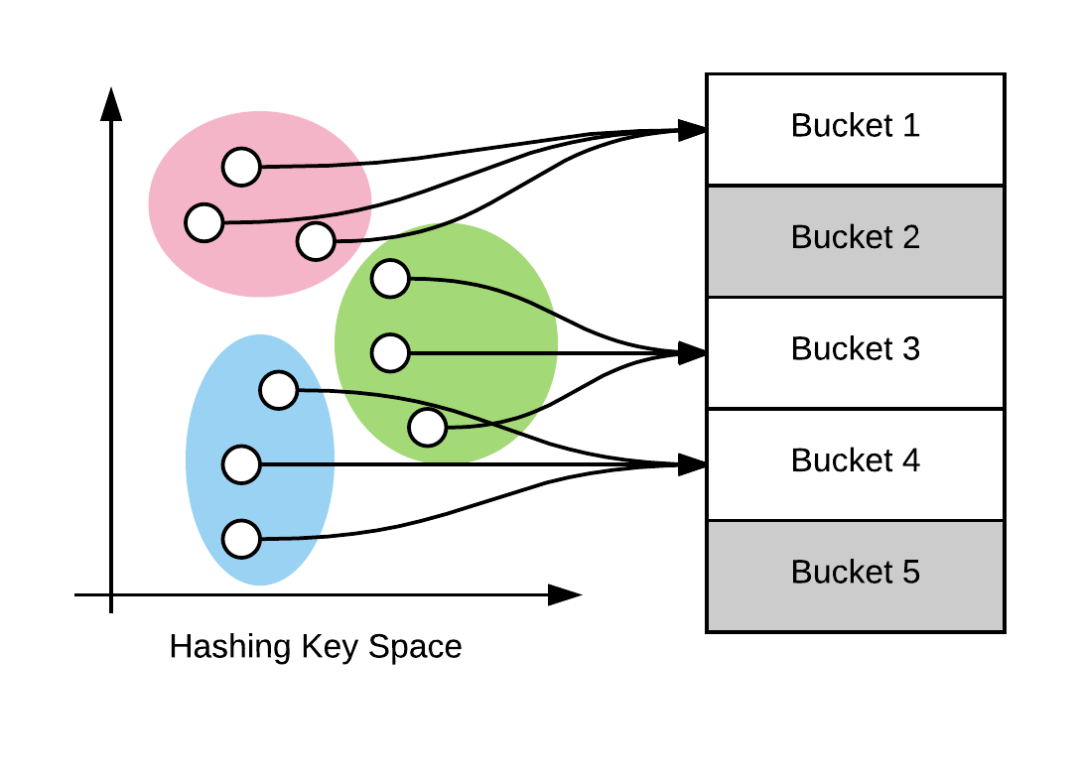
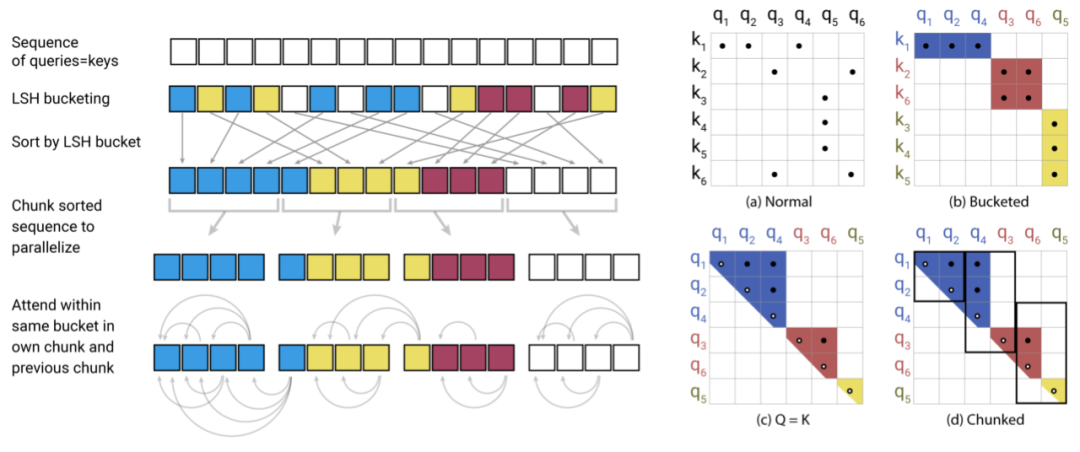
论文:Reformer: The Efficient Transformer
论文地址:https://openreview.net/pdf?id=rkgNKkHtvB
论文:Talking-Heads Attention
论文地址:https://arxiv.org/abs/2003.02436
Y[a, c] = einsum(X[a, b], W[b, c])


h·(dk +dv)·(n·dX +m·dM +n·m)(dk ·hk +dv ·hv)·(n·dX +m·dM +n·m)+n·m·h·(hk +hv)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









