



 本文探讨了onehot表示与分布式词向量的对比,重点介绍了SkipGram模型及其Negative Sampling方法,强调了分布式表示的全局泛化能力和Word2Vec的直观理解。通过实例演示和模型优化,揭示了CBOW与SkipGram的差异,以及如何通过评估方法如TSNE和词向量的相似度来验证模型效果。
本文探讨了onehot表示与分布式词向量的对比,重点介绍了SkipGram模型及其Negative Sampling方法,强调了分布式表示的全局泛化能力和Word2Vec的直观理解。通过实例演示和模型优化,揭示了CBOW与SkipGram的差异,以及如何通过评估方法如TSNE和词向量的相似度来验证模型效果。
大纲:
- 1. onehot vs 分布式表示
- 2. 分布式表示的全局泛化能力
- 3. how to learn word2vec - intuition
- 4. SkipGram
- 5. SkipGram Negative Sampling
- 6. 评估词向量
- 7. CBOW与SkipGram对比
1. onehot vs 分布式表示
Onehot表示:
V = (apple, going, I, home, machine ,learing)
- apple = (1,0,0,0,0,0)
- machine = (0,0,0,0,1,0)
- learning = (0,0,0,0,0,1)
- I go home = (0,1,1,1,0,0)
onehot缺点:
- 高维稀疏
- 无法计算单词之间的相似度,因每一个词映射到高维空间中都是互相正交的,词与词之间没有任何关联关系,这显然与实际情况不符合,因为实际中词与词之间有近义、反义等多种关系
分布式表示
V = (apple, going, I, home, machine ,learing)
- apple = (0.1, 0.3, 0.5, 0.1)
- machine = (0.2, 0.3, 0.1, 0.6)
- learning= (0.1, 0.2, 0.6, 0.1)
- I going home = (0.5, 1.1, 0.5, 0.2)
分布式表示优点:
- 低维稠密
- 可以计算单词之间的相似度,Word2vec虽然学习不到反义这种高层次语义信息,但它巧妙的运用了一种思想:“具有相同上下文的词语包含相似的语义”,使得语义相近的词在映射到欧式空间后中具有较高的余弦相似度。怎么把“具有相同上下文的词语包含相似的语义”这种思想融入模型是很关键的一步,在模型中,两个词是否出现在一起是通过判断这两个词在上下文中是否出现在一个窗口。

3. Capacity,分布式表示可以用100维的向量表示所有的单词, 而独热编码只能表示100个单词
2. 分布式表示的全局泛化能力
在机器学习中,我们要寻求的是在全局范围内泛化能力很强的模型。
Local generalization(局部泛化能力):
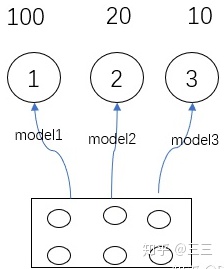
举个例子,model1,2,3分别表示用原材料做了1,2,3三道菜,第一道菜做了比其它两道菜的次数多,可以说model1的能力由于其它两道菜,模型1的泛化能力比较强。
Global generalization(全局泛化能力):
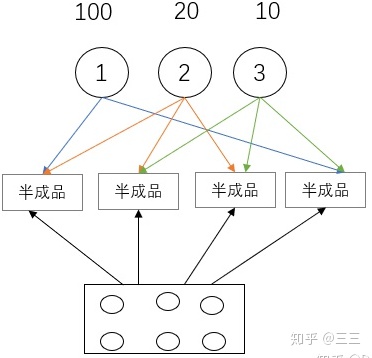
我们先做半成品出来,然后用这些半成品做成菜,我们在做每道菜的时候不断地在调整半成品的参数,这样就可以提高全局的泛化能力。这些半成品可以看作是parameter sharing。
3. how to learn word2vec - intuition
给定一个句子

当数据量很大时,挨在一起的单词语义相似度比不挨在一起的单词的语义相似度要高,
词向量:
- 上下文无关(静态词向量):SkipGram CBOW Glove
- 上下文有关(动态词向量):Bert ELMO

- CBOW:利用上下文词预测中心词
- SkipGram:利用中心词预测上下文词
- NNLM:利用前面的(n-1)个词预测第n个词
- Bert:随机选择一些词MASK掉,再用上下文词预测被MASK的词是什么
4. SkipGram
Skip-Gram模型的核心是:在文本中,距离越近的单词相似度会越高。
根据中心词去预测上下文词
SkipGram 核心思路:
语料库为 We are working on NLP Project, it is interesting

当窗口大小k等于2时 working为中心词的时候
目标函数为:
因此skipgram的目标函数为:
举例:
语料库:
doc1: 今天 天气 很好
doc2: 今天 上 NLP 课程
k=1
接下来看
embedding matrix
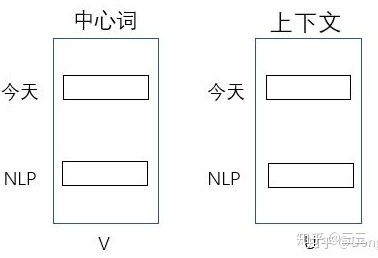
举例:
语料库 {今天, 天气, 好, NLP, 上课}
现在的skipgram的目标函数为:
现在出现了
现在解决这种方法有两种办法:
- hierarchical softmax(层次softmax)
- Negative Sampling(负采样)
5. SkipGram Negative Sampling
对于中心词
如果
如果
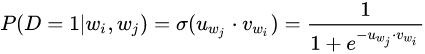
其中
其中
让人想起了逻辑回归
设
举例:
语料库:Today's weather is great
vocab=[Today's ,weather,is, great]
窗口k=1
正样本
负样本
对于正样本 我们想最大化P(D=1,正样本);对于负样本 我们想最大化P(D=0,负样本);
现在目标函数为:
在实际使用时,因为正样本的数量会远远少于负样本的数量(有很多负样本根本不会出现在文本中),所以我们引入Nagetive Sampling,从正样本对应的负样本中随机采样来减少负样本的数量(不考虑所有的负样本,而是对负样本进行采样)。
现在目标函数为:
举例:
s="I like NLP,it is interesting,but it is hard"
vocab=[I, like ,NLP, it,is,interesting,but ,hard] 词典长度=8
以NLP为中心词,K=1
- 正样本:(NLP,like) 负样本:(NLP,I) (NLP,but)
- 正样本:(NLP,it) 负样本:(NLP,hard) (NLP,I)
以it为中心词,k=1
- 正样本:(it,is) 负样本:(it,interesting) (it,hard)
- 正样本:(it,NLP) 负样本:(it,hard) (it,I
用
对
对
对
伪代码如下:
Skip-Gram 的缺点
没有考虑到上下文;
窗口长度有限,无法考虑全局;
无法有效学习低频词和未登录词OOV(out of vocabulary)
多义词无法区别。
上下文的问题可以用Elmo和Bert解决;
低频次和OOV可以用subword embedding
6. 评估词向量:
- TSNE 可视化词向量,对训练得到的词向量降维到二维空间进行观察
- similarity:已有一个训练好的词向量和人工标记的单词相似度表(football和basketball相似度=0.91),基于训练好的词向量进行相似度计算,
和
之间的相似度是不是接近于0.91。
- 类比(analogy):woman:man == boy:girl (如已知woman:man的相似性,给定boy来寻找girl)(woman-man =boy-?)
7. CBOW与SkipGram对比:
在cbow方法中,是用上下文词预测中心词,从而利用中心词的预测结果情况,使用梯度下降方法,不断的去调整上下文词的向量。当训练完成之后,每个词都会作为中心词,把上下文词的词向量进行了调整,这样也就获得了整个文本里面所有词的词向量。
可以看到,cbow预测行为的次数跟整个文本的词数几乎是相等的,复杂度大概是O(V);
而skip-gram是用中心词来预测上下文的词。在skip-gram中,会利用上下文词的预测结果情况,使用GradientDecent来不断的调整中心词的词向量,最终所有的文本遍历完毕之后,也就得到了文本所有词的词向量。
可以看出,skip-gram进行预测的次数是要多于cbow的:因为每个词在作为中心词时,都要使用上下文词进行预测一次。这样相当于比cbow的方法多进行了K次(假设K为窗口大小),因此时间的复杂度为O(KV),训练时间要比cbow要长。
但是在skip-gram当中,每个词都要收到周围的词的影响,每个词在作为中心词的时候,都要进行K次的预测、调整。因此, 当数据量较少,或者词为生僻词出现次数较少时, 这种多次的调整会使得词向量相对的更加准确。
在skip-gram里面,每个词在作为中心词的时候,实际上是 1个学生 VS K个老师,K个老师(上下文词)都会对学生(中心词)进行“专业”的训练,这样学生(中心词)的“能力”(向量结果)相对就会扎实(准确)一些,但是这样肯定会使用更长的时间;
cbow是 1个老师 VS K个学生,K个学生(上下文词)都会从老师(中心词)那里学习知识,但是老师(中心词)是一视同仁的,教给大家的一样的知识。至于你学到了多少,还要看下一轮(假如还在窗口内),或者以后的某一轮,你还有机会加入老师的课堂当中(再次出现作为上下文词),跟着大家一起学习,然后进步一点。因此相对skip-gram,你的业务能力肯定没有人家强,但是对于整个训练营(训练过程)来说,这样肯定效率高,速度更快。
卡门:cbow 与 skip-gram的比较zhuanlan.zhihu.com因此:


第一次编辑(2020)
参考:
Dong:词向量技术的学习zhuanlan.zhihu.com


















 779
779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









