





链表的典型应用,LRU缓存淘汰算法。
缓存是一种可以提高数据读取性能的技术,在硬件设计、软件开发中都有广泛的应用,如CPU缓存,数据库缓存、浏览器缓存。
缓存有大小限制,所以需要缓存的清理机制,一般有以下三种策略:
先进先出策略FIFO(First In,First Out)
最少使用策略LFU(Least Frequently Used)
最近最少使用策略LRU(Least Recently Used)
实现LRU缓存淘汰算法思路:
如果被访问的数据之前已经缓存在链表中,便利找到数据对应的结点,并从原来位置删除,然后插入来链表头部。
如果方位数据没有缓存在链表中,分两种情况去处理
缓存未满,数据直接插入到链表头部
缓存已满,则先删除链表尾部节点,然后新数据直接插入链表头部。
这种处理思路,缓存访问的时间复杂度为O(n)。
链表是比数组稍微复杂一些的数据结构。
数组需要一款连续的内存空间。链表则不需要内存连续,通过“指针”将零散的内存块串联起来使用。

链表结构常见的有三种:单(向)链表,双向链表、循环链表。
单链表每个数据节点存储数据之外,还需要一个指针记录链上下一个节点的地址,叫做后继指针 next。

单链表有两个特殊的节点,头结点记录链表接地址,尾节点指针指向空地址 NULL。
插入删除操作时间复杂度是O(1)。 查询时间复杂度为O(n)。

循环链表与单链表相比,就是尾部节点指针指向头部结点。

双向链表,顾名思义,就是每个节点比单向链表多了一个前驱指针 prev 指向前面节点。
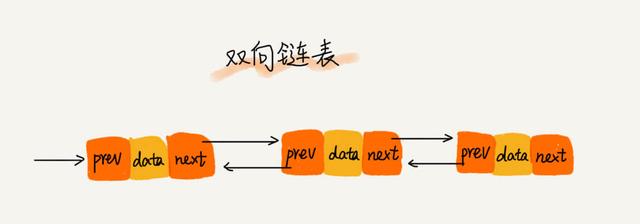
双向链表在查找指定指针指向节点,和在特定节点插入数据,删除数据等操作上时间复杂度都为O(1)。都比单链表有优势。
而且按值查询的效率也要比单链表高一些。因为,我们可以记录上次查找的位置 p,每次查询时,根据要查找的值与 p 的大小关系,决定是往前还是往后查找,所以平均只需要查找一半的数据。
但是由于双向链表记录同样的数据,内存空间上要比单向链表多,但是查询删除等操作更有时间上的优势,这就是用空间换取时间的设计思想。
前面提到的缓存实际上就是利用了空间换时间的设计思想。如果我们把数据存储在硬盘上,会比较节省内存,但每次查找数据都要询问一次硬盘,会比较慢。但如果我们通过缓存技术,事先将数据加载在内存中,虽然会比较耗费内存空间,但是每次数据查询的速度就大大提高了。
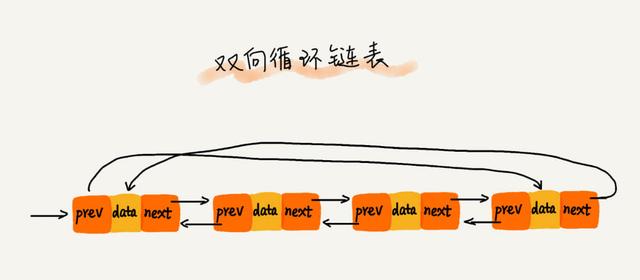
循环链表和双向链表结合而成就是双向循环链表了。















 261
261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









