






 本文深入探讨了推荐算法,包括非个性化推荐和个性化推荐,如基于用户和物品的协同过滤,以及关联规则推荐。同时,介绍了预测算法,如时间序列预测中的移动平均和指数平滑,以及回归预测方法。此外,还提到了特征工程的重要性,如标准化、归一化和离散化。最后,讨论了变量选择和模型缩减技术,如PCA和LDA。
本文深入探讨了推荐算法,包括非个性化推荐和个性化推荐,如基于用户和物品的协同过滤,以及关联规则推荐。同时,介绍了预测算法,如时间序列预测中的移动平均和指数平滑,以及回归预测方法。此外,还提到了特征工程的重要性,如标准化、归一化和离散化。最后,讨论了变量选择和模型缩减技术,如PCA和LDA。
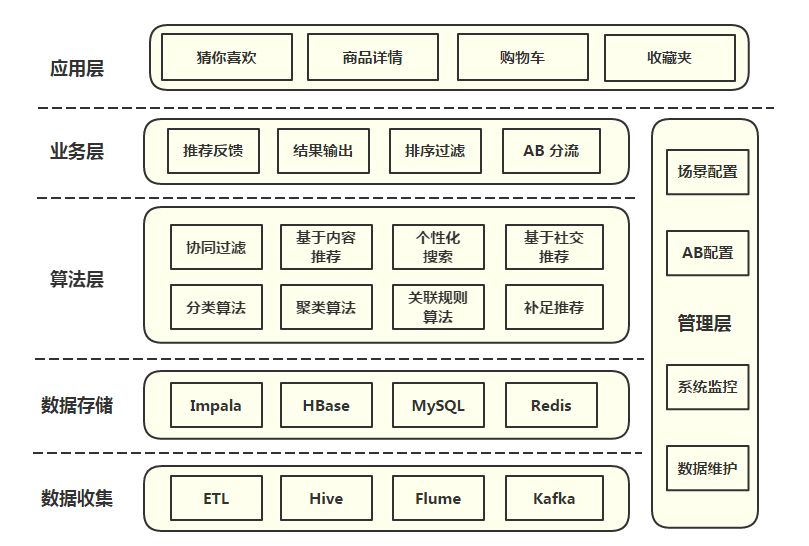
一. 推荐算法
非个性化推荐 "如果你不知道该推荐什么,那么推荐大家都喜欢的准没错"。
基于热门榜单或者最多使用等方式进行的推荐颗粒度较为粗,执行也相对来说比较容易, 同时效果相当不错,非个性化推荐在新用户冷启动、推荐系统冷启也均应用广泛。进一步的,可以利用人口统计学特征再进一步结合热门榜进行推荐。用户的基础数据如用户使用的手机,操作系统,版本等“识别”,城市位置,WiFi还是4G,登录信息如手机号, 手机安装渠道等等,每一项数据都或多或少有其统计学意义,能帮助推荐系统进行更加精准的推荐,如性别-关联电视剧表,年龄-关联电视剧表,职业-关联电视剧表,根据相关表查询时又可根据权重相互叠加给出推荐列表。利用用户的人口统计学特征越多,越能准确的预测用户兴趣。
个性化推荐
- 基于用户社交关系推荐 用户与谁交朋友与谁关系好,在一定程度上与他自身的品味和需要是正相关的。
- 基于用户的协同过滤算法(UF) 两个步骤:找到和目标用户兴趣相似的用户集合,找到集合中用户喜欢且目标用户没有听说过的物品推荐给用户。首先需要计算用户相似度。用户对冷门物品采取行为更能说明他们兴趣的相似度。如几乎所有人都购买过新华字典,但是购买数据挖掘导论的人显然兴趣更加相似。对通用物品权值可考虑进行处理。(相似用户集合,单个相似用户)UserCF推荐着重于反映用户兴趣相似的小群体热点。具有社交化,反映用户所在的小兴趣群体中物品的热门程度。
- 基于物品的协同过滤算法(CF) 物品A和物品B相似度是因为喜欢物品A的用户大都喜欢物品B。两个步骤,计算物品之间的相似度,根据物品的相似度和用户的历史行为为用户生成推荐列表。同上理论,对于热门物品的权重加一定的惩罚因素。同时,活跃用户对于物品的相似度的贡献要小于不活跃用户。ItemCF着重于维系用户历史兴趣。更加个性化,对用户兴趣的延伸。
- 基于关联规则推荐 发现用户与物品之间的关联关系。协同过滤推荐。对于用户建模:基于用户基础数据、第三方数据(如微博登录)、产品中操作数据(点击转发查看页面停留时间购买评论),建立用户兴趣图谱,标签体系树状结构配上权重(-1~1)。对于物品建模:根据物品类型处理,如一首歌有超过 100 个元数据特征,包括歌曲的风格,年份,演唱者等等。每个用户(user)都有自己的偏好,比如A喜欢带有小清新的、吉他伴奏的、王菲等元素(latent factor),如果一首歌(item)带有这些元素,那么就将这首歌推荐给该用户,也就是用元素去连接用户和音乐。每个人对不同的元素偏好不同,而每首歌包含的元素也不一样。
- 基于知识推荐 某一领域的一整套规则和路线进行推荐。参照可汗学院知识树。如随着阅历的增长,程序员看书越来越专业,有一定的路线可寻。
- 基于模型的推荐模型 机器学习的方式训练用户喜好模型。技术驱动方向。
- 其他推荐思路 推荐是一个情景化的事。利用上下文信息进行推荐,利用用户访问推荐系统的时间、地点、心情、网络环境等进行推荐,将上下文信息,尤其是地点和时间信息加到推荐算法中,让推荐系统能准确预测某个特定时间以及特定地点的兴趣。以看视频为例,上班时间看下班后看,在家看还是在父母家看,一个人看和朋友一起看,都是上下文信息,结合上下文信息推荐会差别很大。用户上班下班的兴趣不一样,周末和上班兴趣不一样,上厕所阅读和在办公室阅读不一样。早上用户更会看一看科技新闻,周末以及晚上会看搞笑视频。用户要是wifi环境的话,给多推视频。
- 待学习:基于图的随机游走算法
如何判断一个推荐系统做得好不好?
- 获得反馈并一直迭代 与推荐系统的交互有用吗?他们对收到的推荐结果满意吗?
- 设计评测标准 能吸引更多的用户看内容的详情页 | 促使单个用户浏览更多内容
二. 预测算法
【一点资讯】数学技术之预测计算(三):预测计算常用算法 www.yidianzixun.com
在多类预测模型中都常用的两种方法,即时间序列预测方法和回归预测方法
时间序列预测方法:在实时监控系统中会采集到大量的数据,有些数据具有周期性等时间特征,也称之为时间序列。挖掘出时间序列中所蕴含的信息,实现辅助人工决策,甚至是自动决策。和时间序列方法有关的预测算法,考虑的自变量只有一个时间t,即根据和问题有关的事件,得到和时间t有关的由N个观测数据组成的时间序列:

预测只是对未来态势的一个估计,不是未来事件的精确值,是在一定概率范围内的平均值,因此预测结果和实际结果之间会存在不一致情况,含有误差,但整体预测值趋于期望值,离差平方和最小。
通常时间序列可分解为三个模型,即加法模型(Y=T+S+C+I)和乘法模型(Y=T*S*C*I)以及两者结合的多种混合模型(如Y=T*S+C+I等)。
移动平均算法:简单移动平均和加权移动平均。
移动平均法(Moving average,MA) 指数平滑法(Exponential Smoothing,ES)_tz_zs的博客-CSDN博客_移动平滑法
移动平均法(滑动平均法)基本原理就是通过移动平均消除时间序列中的不规则变动和其他变动,从而揭示出时间序列的长期趋势。
移动平均法是用一组最近的实际数据值来预测未来一期或几期内公司产品的需求量、公司产能等的一种常用方法。移动平均法适用于即期预测。当产品需求既不快速增长也不快速下降,且不存在季节性因素时,移动平均法能有效地消除预测中的随机波动,是非常有用的。
移动平均法是一种简单平滑预测技术,它的基本思想是:根据时间序列资料、逐项推移,依次计算包含一定项数的序时平均值,以反映长期趋势的方法。因此,当时间序列的数值由于受周期变动和随机波动的影响,起伏较大,不易显示出事件的发展趋势时,使用移动平均法可以消除这些因素的影响,显示出事件的发展方向与趋势(即趋势线),然后依趋势线分析预测序列的长期趋势。
简单移动平均:
简单移动平均的各元素的权重都相等。简单的移动平均的计算公式如下:
Ft=(At-1+At-2+At-3+…+At-n)/n
式中,
Ft--对下一期的预测值;
n--移动平均的时期个数;
At-1--前期实际值;
At-2,At-3和At-n分别表示前两期、前三期直至前n期的实际值。加权移动平均法:
加权移动平均给固定跨越期限内的每个变量值以不同的权重。其原理是:历史各期产品需求的数据信息对预测未来期内的需求量的作用是不一样的。除了以n为周期的周期性变化外,远离目标期的变量值的影响力相对较低,故应给予较低的权重。 加权移动平均法的计算公式如下:
Ft=w1At-1+w2At-2+w3At-3+…+wnAt-n
式中,
w1--第t-1期实际销售额的权重;
w2--第t-2期实际销售额的权重;
wn--第t-n期实际销售额的权重;
n--预测的时期数;w1+ w2+…+ wn=1在运用加权平均法时,权重的选择是一个应该注意的问题。经验法和试算法是选择权重的最简单的方法。一般而言,最近期的数据最能预示未来的情况,因而权重应大些。例如,根据前一个月的利润和生产能力比起根据前几个月能更好的估测下个月的利润和生产能力。但是,如果数据是季节性的,则权重也应是季节性的。
回归预测方法 回归预测是通过找到影响事物发展变化的因素x,从而建立一种因果和相关关系的回归方程 y = f (x, a),通过影响因素的变化预测事物未来变化。
非线性回归预测和逐步回归算法 | 逻辑回归预测 | 岭回归(Ridge Regression)预测
岭回归(Ridge Regression)预测:岭回归与最小二乘类似,但当碰到数据有多重共线性时,就会用到岭回归。所谓“多重共线性”,简单的说就是自变量之间存在高度相关关系。在多重共线性中,即使是最小二乘法是无偏的,它们的方差也会很大。通过在回归中加入一些偏差,岭回归就会减少标准误差。实际上,岭回归是通过岭参数λ去解决多重共线性的问题,是一种专用于共线性数据分析的有偏估计回归方法、一种改良的最小二乘估计法,通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价获得回归系数更为符合实际、更可靠的回归方法,对病态数据的拟合会强于最小二乘法。
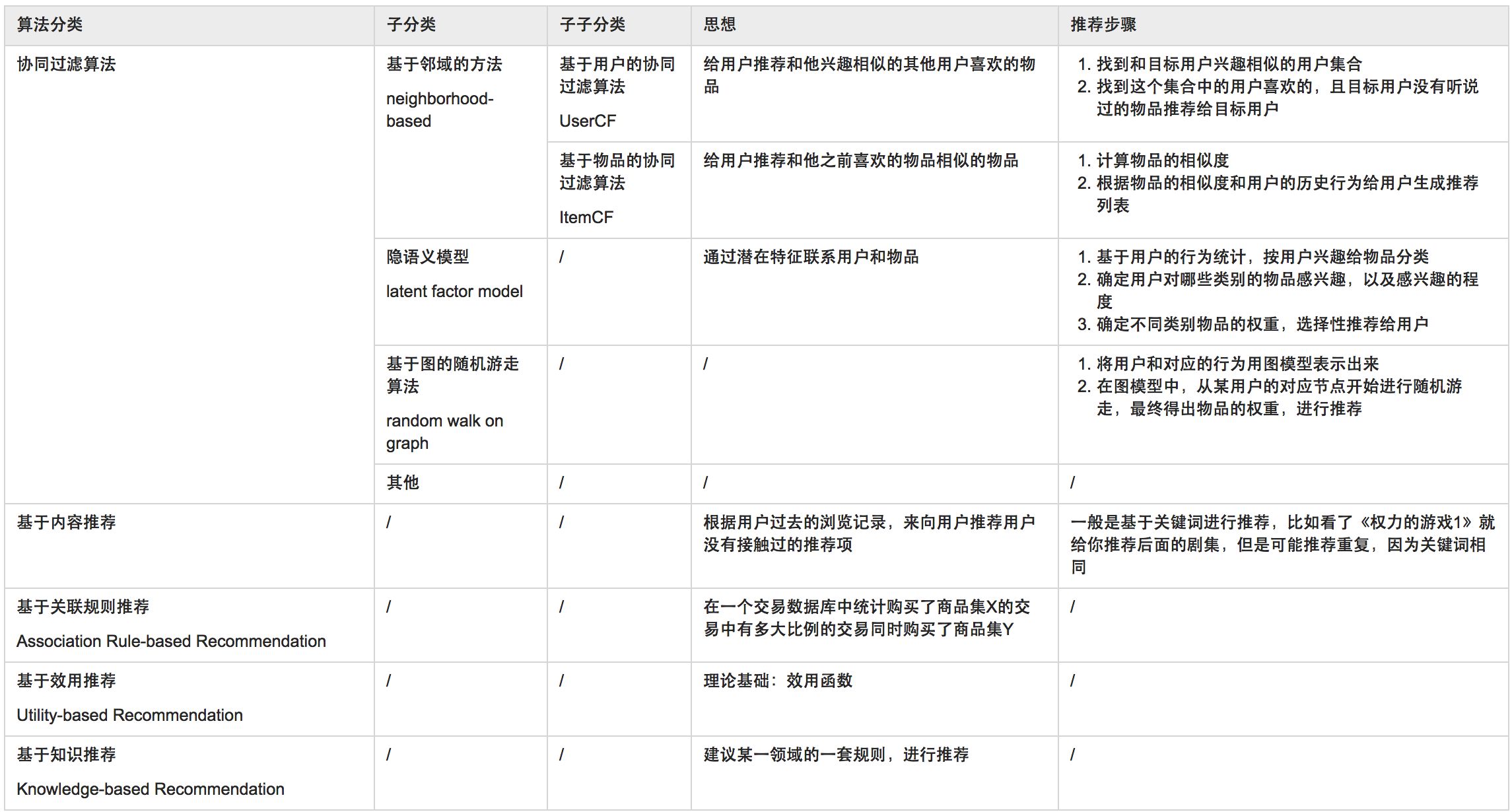
三. 特征工程
使用sklearn做单机特征工程 - jasonfreak - 博客园 (写的贼好)
需要重点记住的:
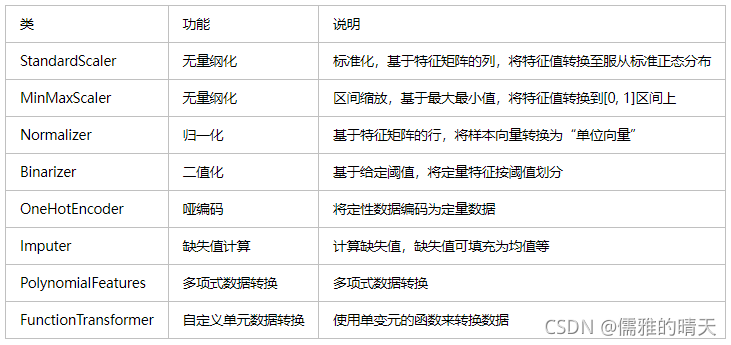
标准化 | 区间缩放 | 归一化 | 离散化 区别?
区间缩放(归一化) :将特征的取值区间缩放到某个特点的范围,例如[0, 1]等。
![]()
标准化:标准化的前提是特征值服从正态分布,标准化后,其转换成标准正态分布。
标准化需要计算特征的均值和标准差,公式表达为: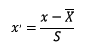
标准化与归一化的区别:
它们都是指特征工程中的特征缩放过程
使用特征缩放的作用是:
- 使不同量纲的特征处于同一数值量级,减少方差大的特征的影响,使模型更准确。
- 加快学习算法的收敛速度。
缩放过程可以分为以下几种:
- 缩放到均值为0,方差为1(Standardization——StandardScaler())(标准化)
- 缩放到0和1之间(Standardization——MinMaxScaler()) (区间缩放 / 归一化)
- 缩放到-1和1之间(Standardization——MaxAbsScaler())
- 缩放到0和1之间,保留原始数据的分布(Normalization——Normalizer())
1就是常说的z-score归一化,2是min-max归一化。
离散化 / 对定量特征二值化
定量特征二值化的核心在于设定一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0,公式表达如下:![]()
对定性特征哑编码 哑编码的意思是one hot encoding or label encoding
特征选择:
从两个方面考虑来选择特征:
- 特征是否发散:如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。
- 特征与目标的相关性:这点比较显见,与目标相关性高的特征,应当优选选择。除方差法外,本文介绍的其他方法均从相关性考虑。
Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
-
方差选择法 使用方差选择法,先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。
-
相关系数法 用相关系数法,先要计算各个特征对目标值的相关系数以及相关系数的P值。
-
卡方检验 经典的卡方检验是检验定性自变量对定性因变量的相关性。假设自变量有N种取值,因变量有M种取值,考虑自变量等于i且因变量等于j的样本频数的观察值与期望的差距,构建统计量:
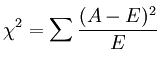
这个统计量的含义简而言之就是自变量对因变量的相关性。
-
互信息法 经典的互信息也是评价定性自变量对定性因变量的相关性的,互信息计算公式如下:

****************************************************************************************************************************************************************************************************************************
卡方检验Chi-Squared Test:卡方检验(Chi-Squared Test) - 知乎
卡方检验就是统计样本的实际观测值与理论推断值之间的偏离程度,实际观测值与理论推断值之间的偏离程度就决定卡方值的大小,如果卡方值越大,二者偏差程度越大;反之,二者偏差越小;若两个值完全相等时,卡方值就为0,表明理论值完全符合。
卡方检验属于非参数检验,由于非参检验不存在具体参数和总体正态分布的假设,所以有时被称为自由分布检验。
参数和非参数检验最明显的区别是它们使用数据的类型。非参检验通常将被试分类,如民主党和共和党,这些分类涉及名义量表或顺序量表,无法计算平均数和方差。
卡方检验分为拟合度的卡方检验和卡方独立性检验。
拟合度的卡方检验定义:主要使用样本数据检验总体分布形态或比例的假说。测验决定所获得的的样本比例与虚无假设中的总体比例的拟合程度如何。
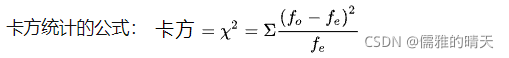
公式中O代表observation,即实际频数;E代表Expectation,即期望频数。

(差异如何显著取决于你原先的预期。)
卡方独立性检验
卡方独立性检验是用于两个或两个以上因素多项分类的计数资料分析,即研究两类变量之间(以列联表形式呈现)的关联性和依存性,或相关性、独立性、交互作用性。
卡方独立性检验的虚无假设指所测量的两个变量之间是独立的,即对于每个个体,所得到的一个变量值与另一个变量的值是不相关的。
p值(p value)就是当原假设为真时所得到的样本观察结果或更极端结果出现的概率。如果p值很小,说明在原假设下极端观测结果的发生概率很小。而如果出现了,根据小概率原理,就有理由拒绝原假设;p值越小,拒绝原假设的理由越充分
PCA
LDA
线性回归的缩减(shrinkage)方法:机器学习算法实践-岭回归和LASSO - 知乎
岭回归(Ridge Regression)和LASSO(Least Absolute Shrinkage and Selection Operator)
两种回归均是在标准线性回归的基础上加上正则项来减小模型的方差。
岭回归是加上L2正则项 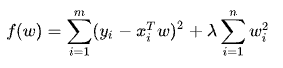
当数据特征中存在共线性,即相关性比较大的时候,会使得标准最小二乘求解不稳定, XTX的行列式接近零,计算 XTX 的时候误差会很大。这个时候我们需要在cost function上添加一个惩罚项,称为L2正则化。
Lasso是加上L1正则项。LASSO(The Least Absolute Shrinkage and Selection Operator)是另一种缩减方法,将回归系数收缩在一定的区域内。LASSO的主要思想是构造一个一阶惩罚函数获得一个精炼的模型, 通过最终确定一些变量的系数为0进行特征筛选。
降维:降维是将高维度的数据保留下最重要的一些特征,去除噪声和不重要的特征,从而实现提升数据处理速度的目的。
降维的算法有很多,比如奇异值分解(SVD)、主成分分析(PCA)、因子分析(FA)、独立成分分析(ICA)。
PCA(Principal Component Analysis) 主成分分析(PCA)原理详解 - 知乎
即主成分分析方法(无监督学习),是一种使用最广泛的数据降维算法。PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。PCA的工作就是从原始的空间中顺序地找一组相互正交的坐标轴,新的坐标轴的选择与数据本身是密切相关的。其中,第一个新坐标轴选择是原始数据中方差最大的方向,第二个新坐标轴选取是与第一个坐标轴正交的平面中使得方差最大的,第三个轴是与第1,2个轴正交的平面中方差最大的。依次类推,可以得到n个这样的坐标轴。通过这种方式获得的新的坐标轴,我们发现,大部分方差都包含在前面k个坐标轴中,后面的坐标轴所含的方差几乎为0。于是,我们可以忽略余下的坐标轴,只保留前面k个含有绝大部分方差的坐标轴。事实上,这相当于只保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,实现对数据特征的降维处理。
LDA 线性判别分析 PCA主要是从特征的协方差角度,去找到比较好的投影方式,LDA更多的是考虑了标注,即希望投影后不同类别之间数据点的距离更大,同一类别的数据点更紧凑。
线性判别分析(LDA)是用于监督学习问题的一种常用技术。LDA是一种降维技术,用作机器学习和模式分类应用程序中的预处理步骤。LDA的目标就是把数据从高维降到低维,从而可以除去一些冗杂的和因变量的特征。相对于非监督学习的主成分分析(PCA)算法,它考虑了样本自带的标签,所以LDA是一种监督学习算法。
例子:贷款违约预测 贷款违约预测-Task3 特征工程 - 云+社区 - 腾讯云
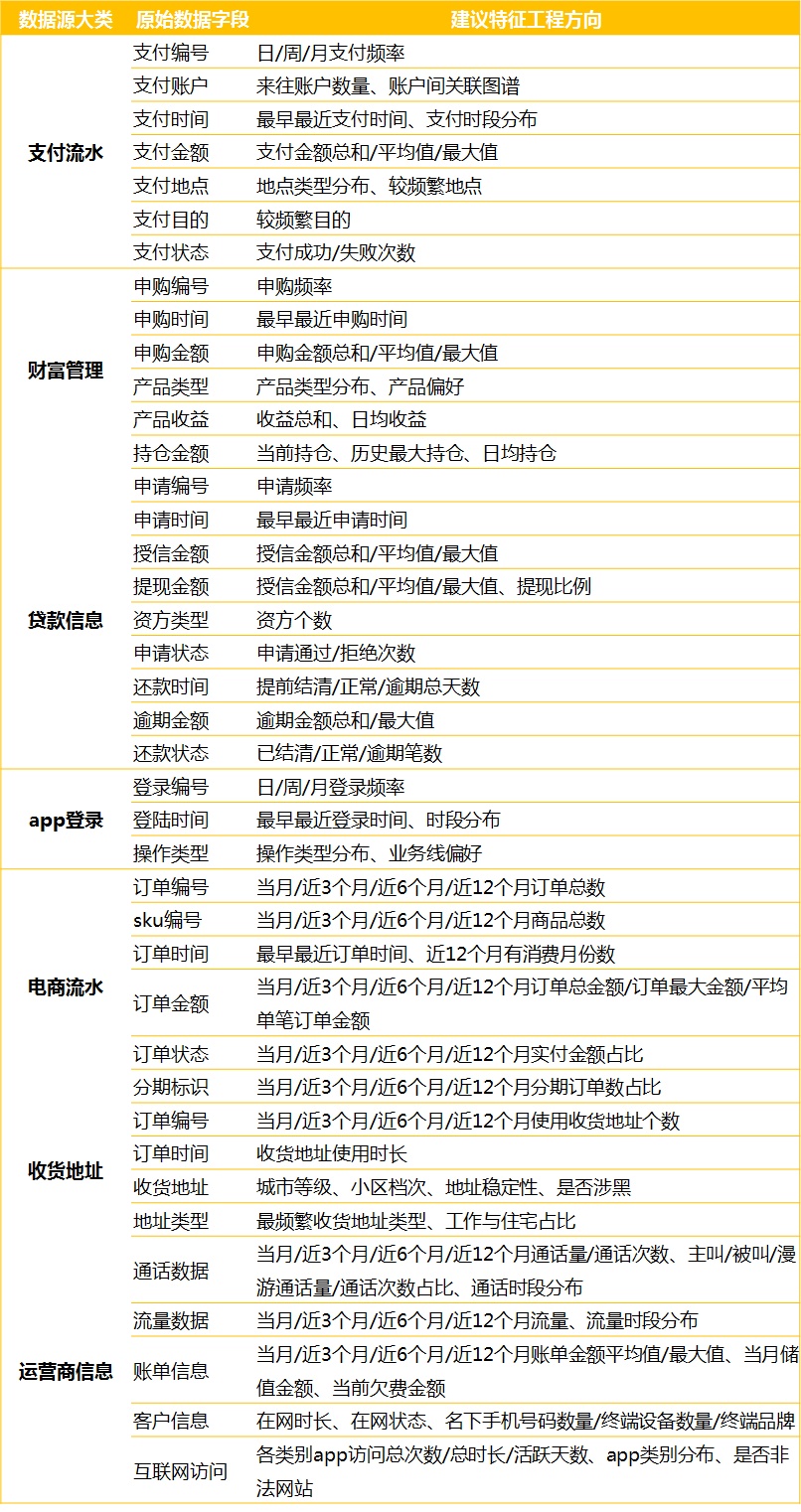
如何预测一家奶茶店的营业额,寻找影响营业额的外部因素?
首先,我们可以从美团点评,高德地图,搜房网等渠道爬取公开的商业数据,就是日常使用APP时能看到的那些数据:什么地方,什么店,卖什么东西,价格怎么样,口碑怎么样,人气怎么样等。这些数据应该都是基于经纬度的,不能直接使用,需要整合。怎么整合这些基于经纬度的数据?这就涉及构造特征。
构造特征:我们(主观)分析一下影响奶茶店营业额的因素:周边人群密度 | 消费水平 | 人群质量 等等
变量选择
单变量筛选 在高维情况下,有时候我们需要预先筛选部分变量,然后再训练模型。
最直接的筛选方式是计算每个特征和目标变量之间的相关性,并保留相关性高于某阈值的特征。最常见的相关性是皮尔森相关系数,但它只能刻画两个变量之间的线性关系。如果特征变量和目标变量之间是二次相关,皮尔森相关系数就难以胜任了。秩相关系数能够较好的刻画出单调的非线性关系。另外,还有基于互信息的变量筛选方式,这常出现在分类模型中。除此之外,还可以用单个特征来拟合目标变量,残差越小,这个特征越重要。如果用线性模型来拟合,此时X的维度为1,它和皮尔森相关系数是等价的;如果是用非参数模型,比如样条函数,局部线性模型等,通常能够较好刻画出单个特征和目标变量之间的非线性相关关系。但是非参数模型的计算量比计算相关性大很多,且结果的好坏依赖于模型的选取(model dependent)。
通过模型选择变量 Lasso 基于模型的变量选择同时考虑了所有变量,能有效刻画模型之间的交互作用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









